VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
2021-07-22 08:54:20
Paper: https://arxiv.org/pdf/2104.11178.pdf
1. Background and Motivation:
本文尝试用一个共享的 backbone 来学习三个模态的特征表达,并且是用 transformer 的框架,自监督的方式去学习。作者认为监督学习的自监督有如下两个问题:
1). 无法充分利用海量无标签数据;
2). CV 的众多任务中,获得有标签数据,是非常困难的。
因此,本文尝试从无监督学习的角度,提出了 VATT 模型。
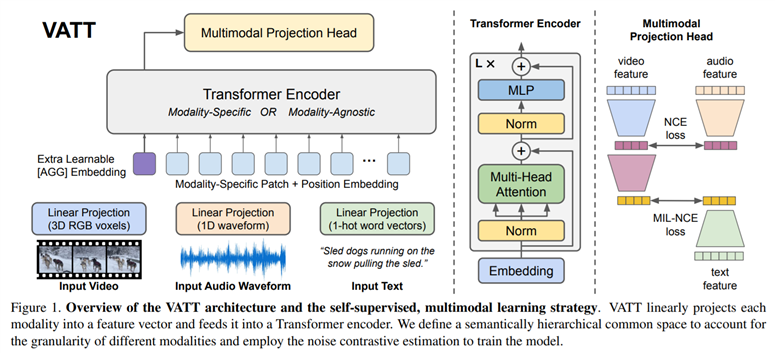
如上图所示,更残暴的是,作者直接让三个模态共享同一个骨干网络。实验证明,与模态无关的骨干网络可以取得与不同模态的骨干网络,相似的结果。
==
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
原文:https://www.cnblogs.com/wangxiaocvpr/p/15043367.html