如图1,为了快速应对早期的业务快速发展,我们架设一个超级简单的Web服务,只有一台应用服务器和DB,这种架构简单,便于快速开发和部署。但随着应用服务器的QPS不断增长,水涨船高,DB的QPS也逐渐提升,对DB的响应时间也有很高要求,单DB已无法快速满足业务发展。这时候可以考虑对DB进行分库分表,或者读写分离等方式以满足业务的发展。但是这些方式仍然有很多问题:
DB为了数据高可靠,牺牲性能,具体表现为数据是存储到硬盘中,而不是内存,这样即使DB重启保证数据不会丢失。所以访问DB常常要从硬盘读取数据,从图2可以看出硬盘的读取时间远远大于内存的。
图1 最简单的Web架构
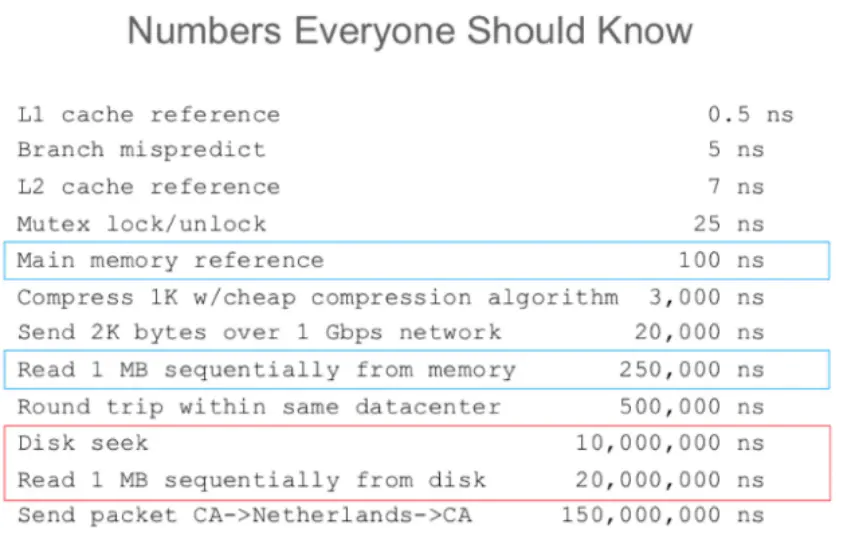
图2 服务器不同级别的访问时间
在大部分业务场景下,数据的读取符合二八原则,即80%的访问量是落到20%的热点数据上,假设我们把这20%热点数据通过内存保存起来,在访问这20%数据时先访问保存的内存地方,这就是缓存。这将极大提升数据读取速度,最终降低请求的响应时间,提高QPS。为了解决上面提出的问题,引入缓存组件,将热点数据缓存到内存中,架构图如图3所示。应用服务器读取数据的顺序为:
因此,Web架构引入缓存后:
降低存储成本,Cache+DB承受更多请求量,大大减少原有需要承受这么多请求量的DB服务器。
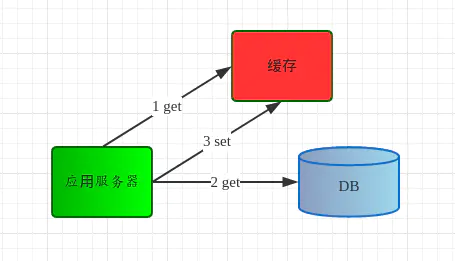
图3 引入缓存的简单Web架构
选择缓存作为Web架构的数据读取组件后,下一步根据业务场景选择具体的缓存组件,从缓存数据分布的特点对比表如下。

从数据存储方式看,对比表如下。

Memcached作为一款经典的缓存组件,具备极高的读取性能,下面将从四个特性分析Memcached的高性能。
Memcached协议和基于libevent的事件处理都不是Memcached特有的特性,所以本文重点分享Memcached内置内存存储方式和不互相通信的分布式的特性。
传统的内存分配是通过malloc/free实现,易产生内存碎片,加重操作系统内存管理器的负担。Memcached使用Slab Allocation机制高效管理内存,Slab Allocation机制按照一个特定的增长比例,将分配的内存分割成特定长度的块,完全解决内存碎片问题。
Slab Allocation将内存分割成不同Slab Class,把相同尺寸的块(Chunk)组成组(Slab),如图4所示。Slab Allocation重复使用已分配的内存块,覆盖原有内存块的数据。
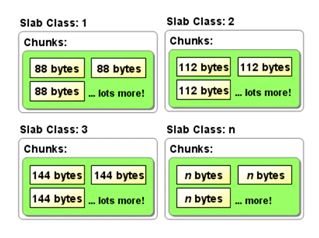
图4 Slab Class
首先介绍Slab Allocation的概念:
Memcached根据数据大小选择最合适的Slab,如图5所示,100 bytes items选择112 bytes的Slab Chunk存储数据,内存空间利用率最高,其中items包含缓存数据的key/value等,具体请查看拙作[Memcached] Slab Allocation的MC项占用空间分析及实践。
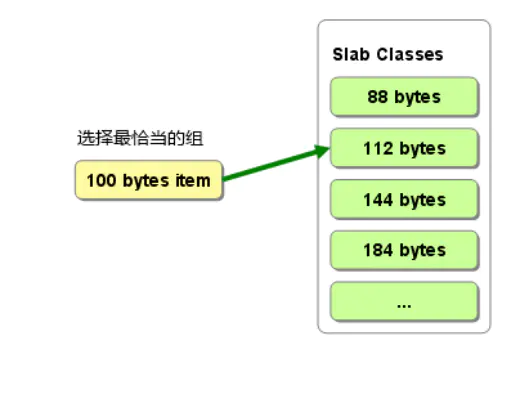
图5 数据选择最合适的Slab
1 (88+112)/2/112=89% 112 bytes的Chunk存放的期望大小是(88+112)/2,所以期望内存利用率是89%,其他同理。
2 (112+144)/2/144=89%
3 (144+184)/2/184=89%
4 ...
1 Growth Factor=2 : (n+2*n)/2/2n=75%
2 Growth Factor=1.25 : (n+1.25*n)/2/1.25n=90%
3 Growth Factor=gf : (n+gf*n)/2/(gf*n)=(1+gf)/2gf
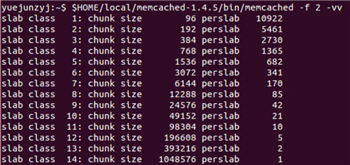
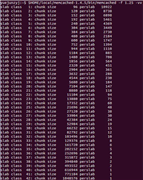
图7 Growth Factor=1.25的Slab Alloaction
图8为Memcached保存item流程图,具体步骤为:
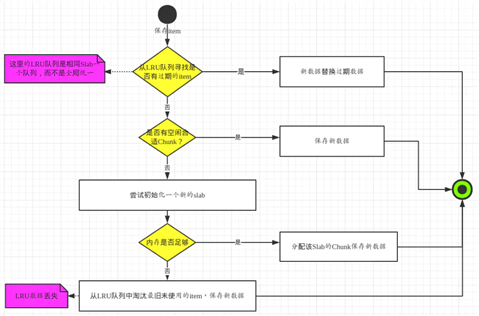
图8 Memcached保存记录过程
memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能,各个memcached不会互相通信以共享信息,由客户端的实现访问Memcached集群。如图9,应用程序通过MC客户端程序库访问MC集群,MC客户端程序库根据Hash算法从服务器列表选择一台MC服务器存放数据,各个MC之间不共享数据,也就没有脑裂问题。
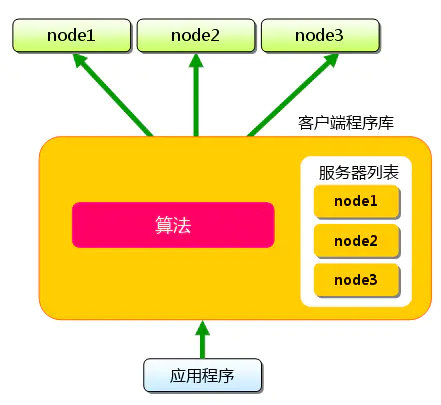
MC客户端程序库根据普通的Hash取余算法选择MC服务器存放数据,如果移除或者新增MC服务器,MC客户端程序库要根据服务器列表总数重新取余,就会选择一台其他的MC服务器存储数据,而该台服务器没有缓存上一台服务器的数据,所以导致大量数据发起大量请求访问DB获取数据,容易造成雪崩问题。
为了解决Hash取余算法的固有缺点,MC引入一致性Hash算法,如果图10所示,首先求出MC服务器(节点)的哈希值,将其分配到0~2^32的环上。然后用同样的方法求出存放数据的哈希值,映射到环上,并从数据映射的位置开始顺时针查找,将数据存放到最近的一个MC节点。如果超过2^32仍然找不到服务器,就会保存到第一台MC节点上。获取数据的查找方式也是如
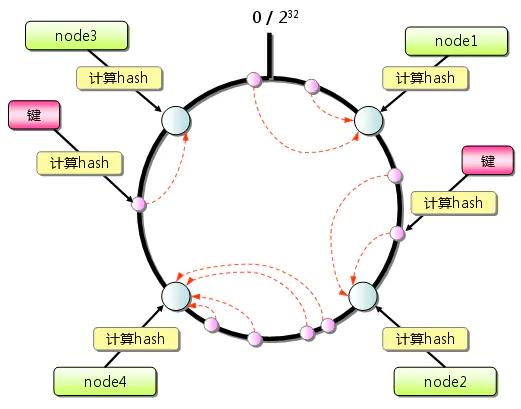
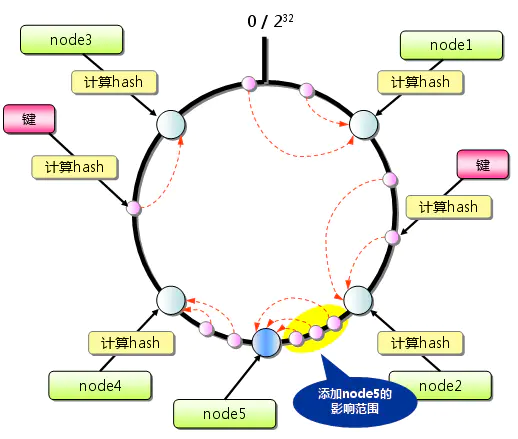
图11 一致性Hash:添加服务器
图12的哈希表或许更加直观,md5根据key值摘要一个128bit的哈希值(校验和),一般表示为32位的16进制数,我们取哈希值的第一位范围将key映射到不同节点,如图12左侧表格所示。当新增一个节点5,把原本映射到节点4的一半数据映射到节点5,其他三个节点不受影响。但是引出数据在MC节点上分布不均匀的问题,原本左侧表格每个节点映射的数据量一样,但是右侧表格的节点4/5只有其他三个节点的一半数据量,导致节点4/5的带宽和内存使用率一直不饱满。

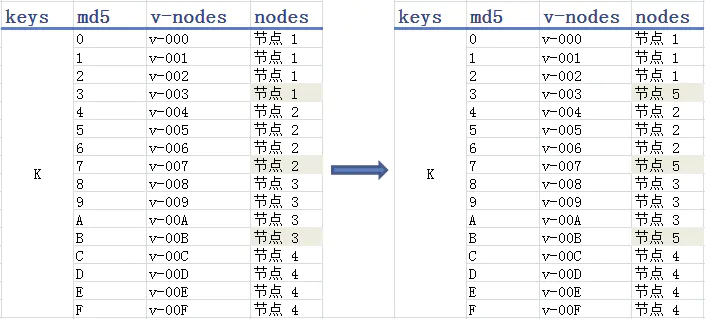
图13 一致性Hash:引入虚拟节点
一致性Hash算法启示
1. 为什么不能用缓存保存session?
2. 为什么同一个MC的数据,有的缓存(值较大的旧数据)要2天才被置换出,有的缓存(值较小的新数据)几分钟就被置换出?
值较大的数据占用Slab Class的大Chunk size,值较小的数据占用Slab Class的小Chunk size,根据Slab钙化问题,当值较小的数据占用Slab Class空间不够用时,并且没有多余的内存和过期的数据,不会挪用值较大的数据占用Slab Class空间,只会复用原有值较小的数据占用Slab Class空间,根据LRU算法置换出同一种Slab的Chunk数据。
3. Cache失效后的拥堵问题
通常我们会为两种数据做Cache,一种是热数据,也就是说短时间内有很多人访问的数据;另一种是高成本的数据,也就说查询很耗时的数据。当这些数据过期的瞬间,如果大量请求同时到达,那么它们会一起请求后端重建Cache,造成拥堵问题。
一般有如下几种解决思路可供选择:
4. Multiget的无底洞问题
出于效率的考虑,很多Memcached应用都以Multiget操作为主,随着访问量的增加,系统负载捉襟见肘,遇到此类问题,直觉通常都是增加服务器来提升系统性能,但是在实际操作中却发现问题并不简单,新加的服务器好像被扔到了无底洞里一样毫无效果。Multiget根据key请求多台服务器,但这并不是问题的症结,真正的原因在于客户端在请求多台服务器时是并行的还是串行的!问题是很多客户端,在处理Multiget多服务器请求时,使用的是串行的方式!也就是说,先请求一台服务器,然后等待响应结果,接着请求另一台,结果导致客户端操作时间累加,请求堆积,性能下降。
5. 缓存命中率下降,但是内存的利用率很高时,我们需要如何进行处理?
内存空间不足,导致缓存失效移除,命中率下降,既然内存利用率高,扩容MC服务器
6. 缓存命中率下降,内存的利用率也在下降时,我们需要如何进行处理?
跟问题2类似,也是Slab钙化问题。空间利用率高的Slab Class不会使用空间利用率低的其他的Slab Class,导致空间利用率高的Slab Class不断因为LRU踢出数据,总体而言,缓存命中率下降,内存的利用率也会下降。
Slab钙化降低内存使用率,如果发生Slab钙化,有三种解决方案:
7. 通常情况下,缓存的粒度越小,命中率会越高。
举个实际的例子说明:当缓存单个对象的时候(例如:单个用户信息),只有当该对象对应的数据发生变化时,我们才需要更新缓存或者移除缓存。而当缓存一个集合的时候(例如:所有用户数据),其中任何一个对象对应的数据发生变化时,都需要更新或移除缓存。
由于序列化和反序列化需要一定的资源开销,当处于高并发高负载的情况下,对大对象数据的频繁读取有可能会使得服务器的CPU崩溃。
8. 缓存被“击穿”问题
对于一些设置了过期时间的key,如果这些key可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑另外一个问题:缓存被“击穿”的问题。
1 static Lock reenLock = new ReentrantLock();
2
3 public List<String> getData04() throws InterruptedException {
4 List<String> result = new ArrayList<String>();
5 // 从缓存读取数据
6 result = getDataFromCache();
7 if (result.isEmpty()) {
8 if (reenLock.tryLock()) {
9 try {
10 System.out.println("我拿到锁了,从DB获取数据库后写入缓存");
11 // 从数据库查询数据
12 result = getDataFromDB();
13 // 将查询到的数据写入缓存
14 setDataToCache(result);
15 } finally {
16 reenLock.unlock();// 释放锁
17 }
18
19 } else {
20 result = getDataFromCache();// 先查一下缓存
21 if (result.isEmpty()) {
22 System.out.println("我没拿到锁,缓存也没数据,先小憩一下");
23 Thread.sleep(100);// 小憩一会儿
24 return getData04();// 重试
25 }
26 }
27 }
28 return result;
29 }
还可以使用分级缓存;采用 L1 (一级缓存)和 L2(二级缓存) 缓存方式,L1 缓存失效时间短,L2 缓存失效时间长。 请求优先从 L1 缓存获取数据,如果 L1缓存未命中则加锁,只有 1 个线程获取到锁,这个线程再从数据库中读取数据并将数据再更新到到 L1 缓存和 L2 缓存中,而其他线程依旧从 L2 缓存获取数据并返回。这种方式,主要是通过避免缓存同时失效并结合锁机制实现。所以,当数据更 新时,只能淘汰 L1 缓存,不能同时将 L1 和 L2 中的缓存同时淘汰。L2 缓存中 可能会存在脏数据,需要业务能够容忍这种短时间的不一致。而且,这种方案 可能会造成额外的缓存空间浪费。
原文:https://www.cnblogs.com/MrLiuZF/p/15072746.html