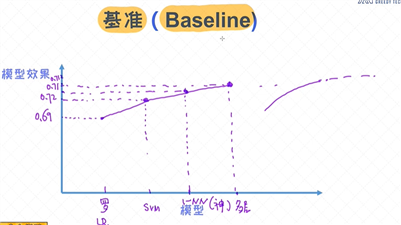
基准(baseline)在建模过程中非常重要。简单来讲,在设计模型的阶段, 首先试图通过简单的方法来快速把系统搭起来, 之后逐步把模块细化, 从而不断得到更好的解决方案。对于分类任务, 逻辑回归 模型可以称得上
是最好的基准,也是比较靠谱的基准。 在实际工作中,切忌一上来就使用复杂的模型,这是不可取的。
谈到分类,也许没有比逻辑回归更简单的方法了,受到工业界的极大的欢迎。逻辑回归的基本概念,以及如何一步步来构建逻辑回归中起到最核心作用的条件概率。

二分类问题
基准(Baseline)

基准(baseline)在建模过程中非常重要。简单来讲,在设计模型的阶段, 首先试图通过简单的方法来快速把系统搭起来, 之后逐步把模块细化, 从而不断得到更好的解决方案。对于分类任务, 逻辑回归 模型可以称得上
是最好的基准,也是比较靠谱的基准。 在实际工作中,切忌一上来就使用复杂的模型,这是不可取的。
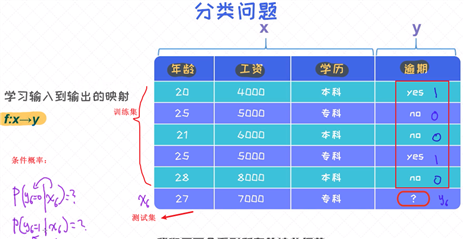
分类问题
二分类问题

核心问题是: 如果通过条件概率 p(y|x) 来描述x和y之间的关系。
逻辑回归 实际上是基于线性回归模型构建起来的, 所以这里也希望通过线性回归方程一步步来构造上述的条件概率p(y∣x)。
我们是不能把条件概率p(y∣x)表示成 p(y|x) = wT x + b,因为右边的式子不满足条件概率的性质。
那么是否可以改造线性回归 wT x + b使得它的值域映射到(0, 1)区间了?
如何把正无穷到负无穷区间的值映射到(0,1)区间?
答案就是使用逻辑函数。

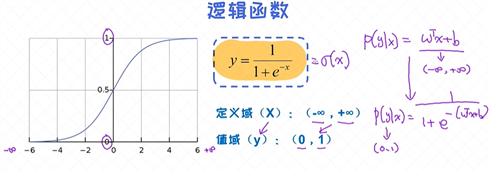
逻辑函数
逻辑函数的应用非常广泛, 特别是在神经网络中处处可见, 很大程度上是源于它不可或缺的性质:
可以把任意区间的值映射到(0, 1)区间。这样的值既可以作为概率, 也可以作为一种权重。另外,由于大多数模型在训练时涉及到 导数 (derivative)的计算, 同时逻辑函数的导数具有极其简单的形态, 这也使得逻辑函
数受到了很大的欢迎。
样本的条件概率
当把 线性回归 的式子和逻辑函数拼在一起的时候, 就可以得到合理的 条件概率 的表达式。
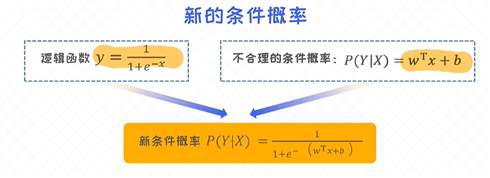
在 逻辑回归 中我们针对的是 二分类问题 , 所以一个样本必须要属于其中的某一个分类。这就意味着, 条件概率 p(y=1|x) 和 p(y=0|x) 之和一定会等于1。

对于逻辑回归, 它的参数是 w, b, 前者是向量, 后者是标量。在这里, 两个条件概率的表达式是可以替换顺序的。只要能保证两个条件概率之和等于1就可以了。

如何构造逻辑回归模型的目标函数,它是从条件概率获得。先理解最大似然估计,之后在最大似然的框架下试着推导出逻辑回归的目标函数。
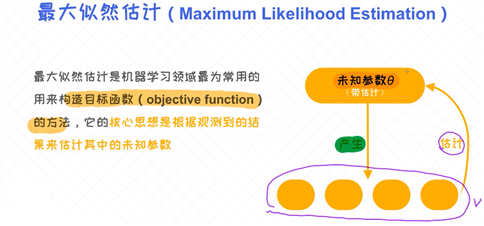
最大似然估计(Maximum Likelihood Estimation)在机器学习建模中有着举足轻重的作用。它可以指引我们去构造模型的目标函数, 以及求出使 目标函数 最大或者最小的参数值。
如何理解 最大似然估计 呢?
一个比较抽象的解释是: 假如有个未知的模型(看作是黑盒子), 并且它产生了很多能观测到的样本。这时候, 我们便可以通过最大化这些样本的概率反过来求出模型的最优参数 ,这个过程称之为最大似然估计。



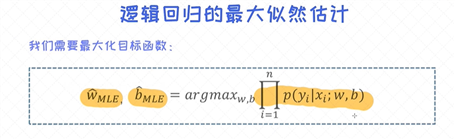
逻辑回归的似然函数
对于单个样本的 条件概率 已经定义过了, 这个概率也可以看作是似然概率。下一步得把所有的样本全部考虑进来, 这时候我们得到的就是所有样本的似然概率。

有了所有样本的 似然概率 之后, 我们的目标就是要求出让这个似然概率最大化的模型的参数( 对于逻辑回归模型就是w, b),这个过程称之为最大似然估计(maximum likelihood estimation)。


经过一系列的简化操作之后,发现不能继续再简化了。剩下的工作就是要寻找让目标函数最小化的参数w, b。那如何求出最优解呢? 一个经典的优化算法是梯度下降法!

求函数的最大值/ 最小值
对于求解函数的最优参数, 通常有两种简单的方法:
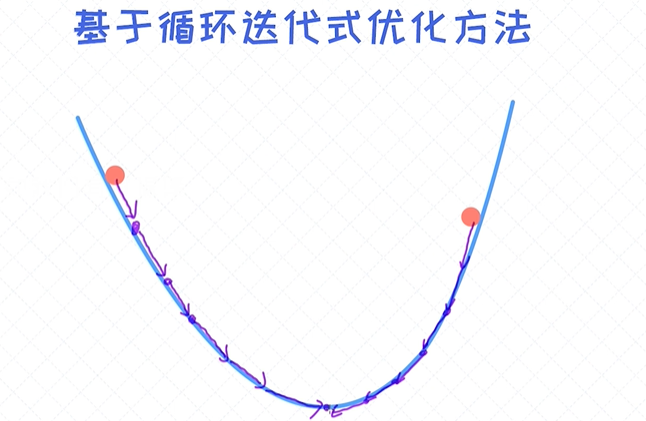
梯度下降法
梯度下降法 非常实用, 几乎所有的模型我们都可以使用梯度下降法来训练。这也说明此方法是具有通用性的,不管问题有多复杂。特别是对于深度学习, 它的作用无可替代, 我们常说的反向传播算法 (back-
propagation)其实本质上就是梯度下降法。需要注意的一点是: 梯度下降法依赖于求导, 这也是为什么对函数的求导能力如此重要!



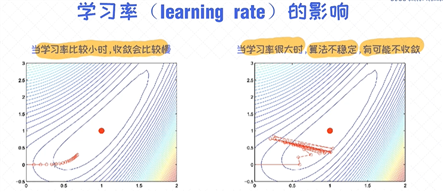
对于梯度下降法来说,有一个重要的参数叫作学习率(learning rate), 我们可以把它看作是可调节的参数(也称之为超参数)。学习率对于收敛以及对最终的结果起到很重要的作用。
对于逻辑函数的求导
梯度下降法的核心是对函数的求导。 逻辑回归的目标函数本身具有一定的复杂度, 其中就涉及到对逻辑函数的求导过程。对逻辑函数的求导:


逻辑回归的梯度下降法
对于逻辑回归,我们有两组参数分别为w, b, 所以求导的关键也就围绕这两组参数。这个过程中会涉及到一些 复合函数的求导法则 。


有了对w, b的结果之后,最终可以写出整个逻辑回归的梯度下降法的过程。
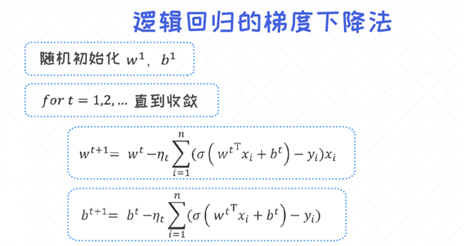
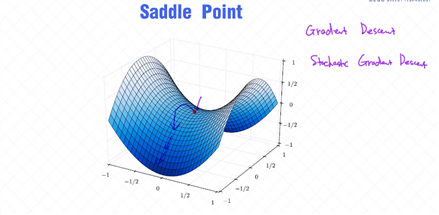
梯度下降法过程中, 如何判断迭代过程是否已经收敛 ?
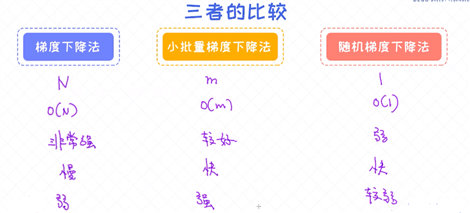
随机梯度下降法以及小批量梯度下降法。这两者均是梯度下降法的变种,适合用在数据量比较大的场景。实际上,工业界中用得最广泛的是小批量梯度下降法。
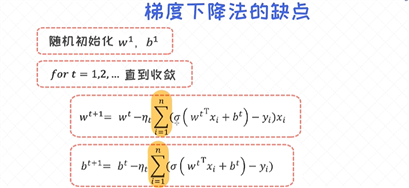
梯度下降法的缺点
当样本很多的时候, 每一次迭代所花费的时间成本是很高的。举个例子, 当数据集里有一百万个样本的时候, 每一次的参数更新就需要循环所有的样本并把它们的梯度做累加。
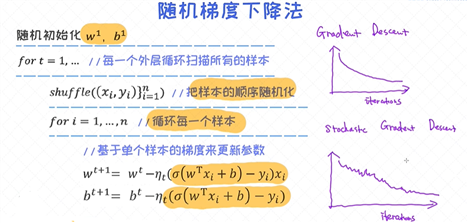
随机梯度下降法
随机梯度下降法(SGD) 可以看作是梯度下降法的极端的情况。在梯度下降法里,每次的参数更新依赖于所有的样本。然而, 在随机梯度下降法里, 每一次的迭代不再依赖于所有样本的梯度之和, 而是仅仅依赖于其中
一个样本的梯度 。所以这种方法的优势很明显, 通过很“便宜”的方式获得梯度, 并频繁的对参数做迭代更新, 这有助于在更短的时间内得到收敛结果。
虽然SGD用很低的成本可以更新到模型的参数,但也有自身的缺点。
由于梯度的计算仅依赖于一个样本,计算出的结果包含较大的噪声;实际上, SGD的收敛效率通常是更高的, 而且有些时候SGD的最后找出来的解更优质。
由于在 随机梯度下降法中, 我们用一个样本的 梯度 来代替所有样本的梯度之和, 计算出来的结果包含大量噪声,并且不太稳定。为了部分解决这个问题,我们通常会把学习率设置为较小的值, 这样可以有效削弱梯度
计算中带来的不稳定性。
相比梯度下降法, 当我们使用随机梯度下降法的时候可以看到每一次迭代之后的目标函数或者损失函数会有一些波动性。有时候的更新会带来目标值的提升,其他时候的更新可能反而让目标值变得更差。但只要实
现细节合理,大的趋势是沿着好的方向而发展的。
小批量梯度下降法
梯度下降法和随机梯度下降法其实可以看作是两个极端, 前者在计算梯度时考虑所有的样本, 后者则仅仅考虑其中的一个样本。既然这两个极端各有各自的优缺点,那是否可以使用一个折中的方案呢? 答案是肯定
的,这个方法叫作 小批量梯度下降法 (mini-batch gradient descent)。 它每次从样本中选择一部分子集,并基于这些选出来的样本计算梯度, 并做参数的更新。

比较不同的算法
对于各类梯度下降法做一个总结:
用逻辑回归模型来解决一个分类问题 - 预测银行客户是否开设账户。在这个过程中,会涉及到数据可视化、独热编码、F1-SCORE等技术。
理解数据
理解数据是解决问题的第一步,在这里我们从多方位来理解一下数据本身的一些特点比如哪些特征具有更好地预测能力,下面给出了部分数据的快照以及字段的说明。
特征选择
对特征本身的重要性有大概的认知之后,我们可以选择把那些关联度不高的特征可以从数据中剔除掉。对于特征个数很多的数据来讲,这种操作还是非常有效的。但由于目前案例的数据特征并没有特别多,在这里先保留所有的特征。关于 特征选择 ,其实有很多不同的方法如根据 相关性 来选择、根据 贪心算法 来选择、根据树模型来选择等等,在后续的课程里会做详细的讲解。
类别变量和独热编码
对于类别型变量如本科、硕士、博士,在放到模型之前我们需要做特殊的处理,因为我们都知道模型的输入一定是数量化的信息,那如何把“本科,硕士,博士“这些字段转换成数量化的信号呢?
如果一个特征的值为类别型变量,”本科“, ”硕士“,”博士“,每一个值如何转换成数字呢?
硕士大于本科, 博士大于硕士, 类似于男大于女, 或者女大于男。 从这个角度考虑,我们就不能把类别型变量直接设置为某一个具体的值, 因为这些值本身是有大小关系的。
正确的做法是把变量值转化为独热编码的形态。
独热编码
对于类别型变量,正确做法是使用独热编码(one-hot encoding), 这也是最常用的编码方式。 然后直接把独热编码输入到模型就可以了。 一般来讲,独热编码的转换会让特征维度上升,比如对于一个类别型变量 - “城
市”, 可能的取值为1000多个,那当我们把这个变量转换成独热编码之后就变成了1000多维的向量。
模型的评估
对于这个案例,标签类型的占比是很不平衡的,这种数据我们也称之为不平衡数据(imbalanced data)。 对于不平衡数据,评估标准上也需要格外地注意,因为选错了评估标准可能导致建模本身失去了意义。
由于负样本很多,假如把所有的样本分类成负样本,准确率已经高达99%,看似训练得很好。
原文:https://www.cnblogs.com/shengyang17/p/15058527.html