以一个例子展示一维卷积过程:
假设输入数据为 6 个维度的数据,有 4 个通道,即[6,4]的数据。
设置核大小(kernel_size)为 2,卷积的步长(stride)为 2,核数量(也就是out_channels)为 1 的卷积。
其中卷积核的通道数和输入的通道数相同,即同样是 4 。
卷积过程及结果如下图所示:
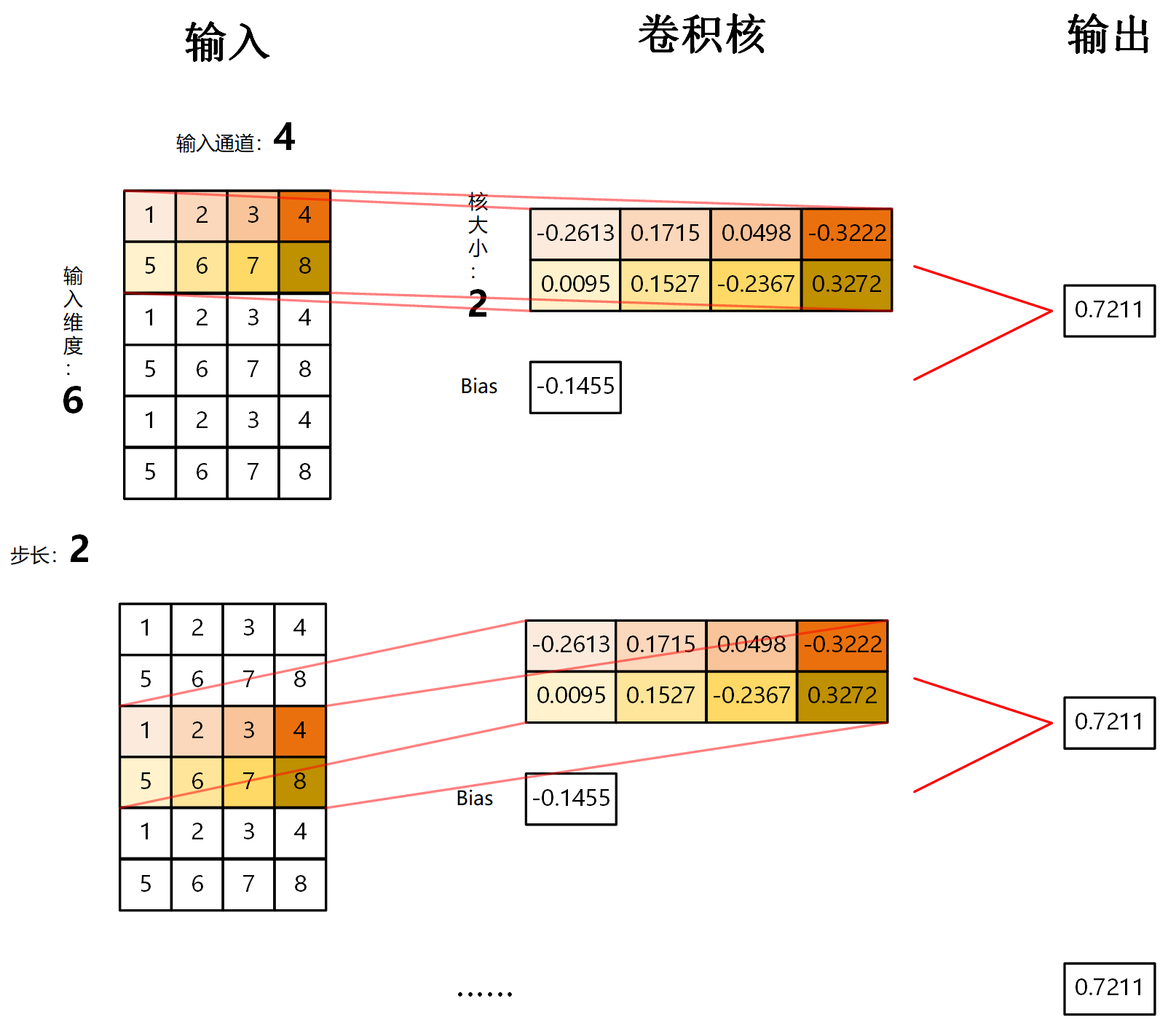
得到一个[1,3]得输出。
第一维结果1:由于核维度默认和输入通道数相同,所以当只有一个卷积核时,第一维输出就为1。有多少个卷积核,输出第一维就是多少。
第二维结果3:可通过公式计算:\(N=\frac{W-F+2P}{S}+1\)。其中:\(W\)为输入大小,\(F\)为核大小,\(P\)为填充大小,\(S\)为步长。
通过pytorch的实现:
pytorch的一维卷积nn.Conv1d()参数:
例程:
import torch
import torch.nn as nn
torch.manual_seed(2021)
a = [1, 2, 3, 4]
b = [5, 6, 7, 8]
inp = torch.Tensor([a, b, a, b, a, b])
# 扩充一维,作为batch_size
inp = inp.unsqueeze(0)
print(inp.shape)
# 调换位置
inp = inp.permute(0, 2, 1)
model = nn.Conv1d(in_channels=4, out_channels=1, kernel_size=2, stride=2, padding=0)
# 显示权重
for name, parameters in model.named_parameters():
print(name, ‘:‘, parameters)
out = model(inp)
print(out.shape)
print(out)
结果:
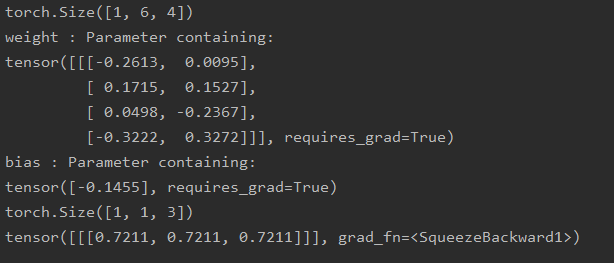
[batch_size, 6, 4]nn.Conv1d()计算时,它的输入格式是[batch_size, in_channels, in_size],所以要使用permute()函数,把后面两个维度的顺序调换一下!unsqueeze()函数,扩充1维。将[batch_size, 6]变为[batch_size, 6, 1]。卷积过程也如下图所示: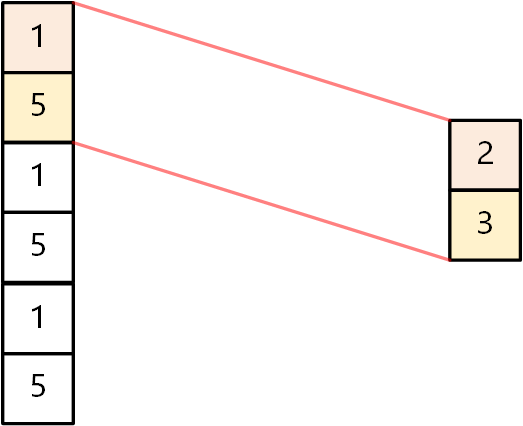
原文:https://www.cnblogs.com/aionwu/p/15088988.html