举一个例子 : 扩容Resize:
JDK1.7:
Segment:
Segment本身就相当于一个HashMap对象。同HashMap一样,Segment包含一个HashEntry数组,数组中的每一个HashEntry既是一个键值对,也是一个链表的头节点。
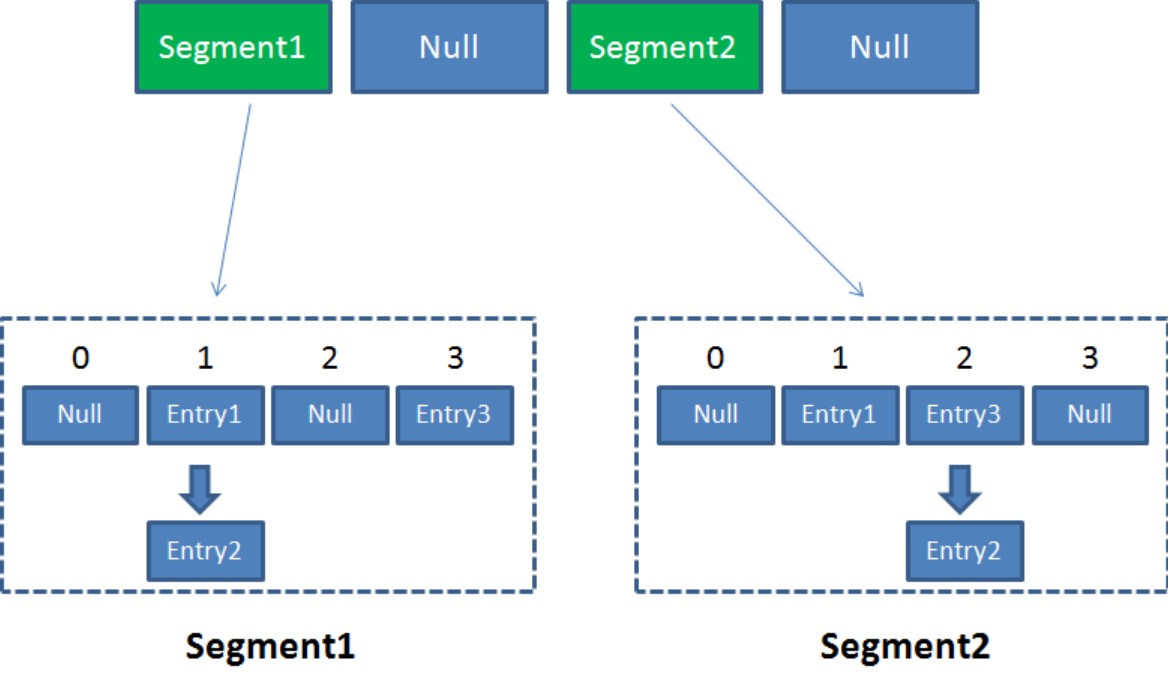
可以说,ConcurrentHashMap是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表
ConcurrentHashMap当中每个Segment各自持有一把锁。在保证线程安全的同时降低了锁的粒度,让并发操作效率更高。
Get:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象 -- 第一次定位 到 Segment
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。-- 第二次定位 到 具体元素
5.插入或覆盖HashEntry对象。
6.释放锁。
size:元素数量
1.遍历所有的Segment。
2.把Segment的元素数量累加起来。
3.把Segment的修改次数累加起来。
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计(最多三次),尝试次数+1;如果不是。说明没有修改,统计结束。
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计。 -- 升级锁
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等。
7.释放锁,统计结束。
JDK1.8:
从JDK1.7版本的ReentrantLock(重入锁)+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树
优化:
put:
步骤:对当前的table进行无条件自循环直到put成功
如果没有初始化就先调用initTable()方法来进行初始化过程
如果没有hash冲突就直接CAS插入 -- 两次哈希,减少哈希冲突
如果还在进行扩容操作就先进行扩容
如果存在hash冲突,就加锁来保证线程安全,这里有两种情况,一种是链表形式就直接遍历到尾端插入,一种是红黑树就按照红黑树结构插入,
最后一个如果该链表的数量大于阈值8,就要先转换成黑红树的结构,break再一次进入循环;
如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //两次hash,减少hash冲突,可以均匀分布
int binCount = 0;
for (Node<K,V>[] tab = table;;) { //对这个table进行迭代
Node<K,V> f; int n, i, fh;
//这里就是上面构造方法没有进行初始化,在这里进行判断,为null就调用initTable进行初始化,属于懒汉模式初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果i位置没有数据,就直接无锁插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//如果在进行扩容,则先进行扩容操作
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//如果以上条件都不满足,那就要进行加锁操作,也就是存在hash冲突,锁住链表或者红黑树的头结点
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { //表示该节点是链表结构
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//这里涉及到相同的key进行put就会覆盖原先的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //插入链表尾部
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//红黑树结构
Node<K,V> p;
binCount = 2;
//红黑树结构旋转插入
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) { //如果链表的长度大于8时就会进行红黑树的转换
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//统计size,并且检查是否需要扩容
return null;
}
- initTable() -- 初始化
- helpTransfer() -- 多线程扩容(transfer():扩容)
- treeifyBin() -- 链表转红黑树
- addCount() -- 计算size 和 是否进行扩容
get:
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //计算两次hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {//读取首节点的Node元素
if ((eh = e.hash) == h) { //如果该节点就是首节点就返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值为负值表示正在扩容,这个时候查的是ForwardingNode的find方法来定位到nextTable来
//查找,查找到就返回
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//既不是首节点也不是ForwardingNode,那就往下遍历
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
size:
在put操作时,就已经调用了addCount,将size计算好了
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE :
(int)n);
}
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a; //变化的数量
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
扩容:
原文:https://www.cnblogs.com/hehell/p/15090415.html