一、数据库
1.简介
目前数据库产品有300+多种,数据库产品繁多,但是在在进行数据库产品的选择的时候我们主要考虑成本低,可用高,易维护,满足业务需求的条件下进行高效选择。 当前的数据库产品又可以分为关系型和非关系型数据库,关系数据库主要选择流行的产品Oracle, MySQL , SQL Serve 等,对于非关系型数据库,列式存储的数据库主要有MongoDB,Hbase等。
2.数据库的选择
金融数据库对数据一致性,可用性要求相对比较高,基本都属于P0的业务,包括支付订单类型系统,白条核心系统,白条账务等都属于核心的业务等级,这样的业务一般使用MySQL的分库分表,读写分离的方案,有效的提升系统的吞吐量。
根据数据等级要求(P0-P4):数据库选择流程:
(1)关系型数据库(P0-P3)
(2)非结构化存储数据(P4)
?
二、hbase
1. hbase是什么
答:HBase是一个分布式的、面向列的开源数据库。
2.hbase的特点
3.hbase的原理
4.hbase适用场景
?
三、kafka
1.kafka是什么
答:Kafka是一个分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。
2.kafka特点
(1) 高吞吐量。据了解,Kafka每秒可以生产约25万条消息(50 MB),每秒处理55万条消息(110 MB)。
(2) 持久化。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
(3) 分布式系统。所有的producer、broker和consumer都会有多个,均为分布式的。?????
(4) 可扩展性。kafka使用zookeeper来实现动态的集群扩展,不需要更改客户端(producer和consumer)的配置。broker会在 zookeeper注册并保持相关的元数据(topic,partition信息等)更新。而客户端会在zookeeper上注册相关的watcher。?????
3.Kafka中角色与术语
? 它们之间的数据流程如右图所示
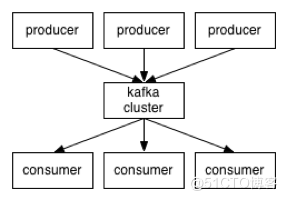
Kafka集群中维护的partitions如图所示:

???? 一个partition可以有多个备份,默认为1。
???? 每个partition都有一个唯一的leader,所有的读写操作都在leader上完成。
? 每个消息在partition中的位置叫做offset。
? 同一个Consumer Group中的consumers,Kafka将相应Topic中每个消息只发送给其中一个Consumer。
4.Kafka系统架构

kafka是显式分布式架构,producer、broker(Kafka)和consumer都可以有多个。
Kafka的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存
5.相关文档
?
?
原文:https://blog.51cto.com/u_10707460/3260029