准备工作:准备hadoop-2.7.7.tar.gz、jdk-8u191-linux-x64.tar.gz压缩包,版本可以不同,我这里用的是hadoop-2.7.7和jdk1.8。
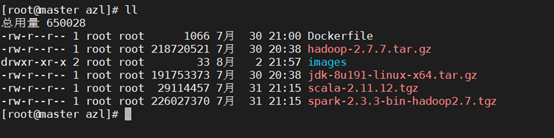
1. 上传hadoop-2.7.7.tar.gz、jdk-8u191-linux-x64.tar.gz压缩包。
[root@master ~]# cd /home/azl
[root@master azl ]# ll
2. 创建Dockerfile文件
[root@master azl ] # vim Dockerfile
#选择centos7.7.1908作为基础镜像#选择centos7.7.1908作为基础镜像
FROM centos:centos7.7.1908
#镜像维护者信息(根据自己的信息进行修改)
MAINTAINER xxx@xxx.com
#构建容器时需要运行的命令
#生成相应的主机密钥文件
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
RUN ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key
RUN ssh-keygen -t ed25519 -f /etc/ssh/ssh_host_ed25519_key
#将宿主机的文件拷贝至境像(ADD会自动解压),这里要切换到jdk和hadoop压缩包所在路径
ADD jdk-8u191-linux-x64.tar.gz /usr/local
ADD hadoop-2.7.7.tar.gz /usr/local
#设置环境变量
ENV CENTOS_DEFAULT_HOME /root
ENV JAVA_HOME /usr/local/jdk1.8.0_191
ENV HADOOP_HOME /usr/local/hadoop-2.7.7
ENV JRE_HOME ${JAVA_HOME}/jre
ENV CLASSPATH ${JAVA_HOME}/lib:${JRE_HOME}/lib
ENV PATH ${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#终端默认登录进来的工作目录
WORKDIR $CENTOS_DEFAULT_HOME
#启动sshd服务并且暴露22端口
EXPOSE 22
CMD ["/usr/sbin/sshd", "-D"]CMD ["/usr/sbin/sshd", "-D"]
3. 编译docker文件
[root@master azl ] # docker build -t xxx/hadoop:2.7.7 . #-t后面是镜像名,根据需要修改
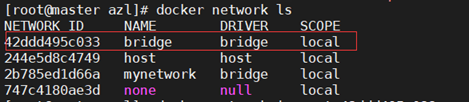
4. 设置网络
[root@master azl ] # docker network ls
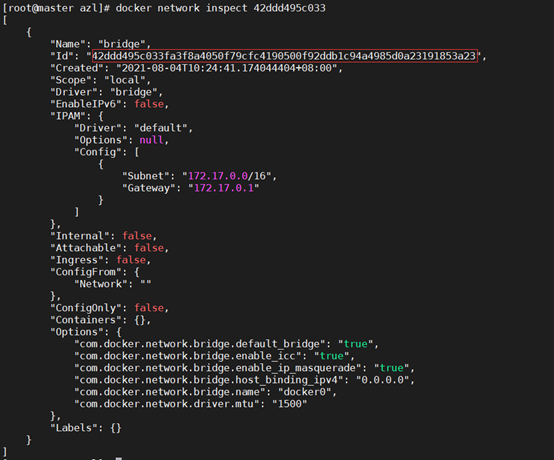
[root@master azl ] # docker network inspect [容器id]
5. 创建自己的网络
[root@master azl ] # docker network create --subnet=172.22.0.0/16 mynetwork(mynework网络名随便取)

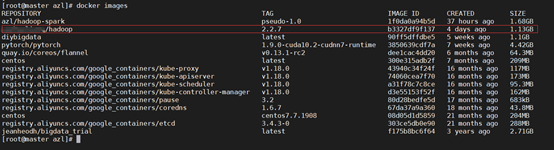
6. 查看镜像
[root@master azl ] # docker images
7. 运行容器并进行端口映射
[root@master azl ] #docker run -d --name hadoop --hostname hadoop -P -p 50070:50070 -p 8088:8088 -p 19888:19888 --net mynetwork --ip 172.22.0.2 b3327df9f137[镜像id]
8. 查看容器
[root@master azl ] # docker ps
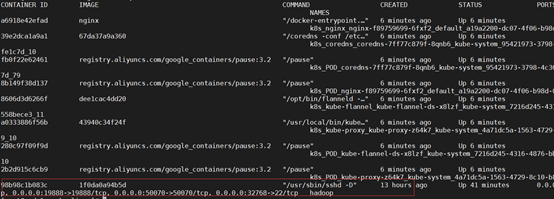
可以看到容器已经运行起来了,下面进入容器内部
9. 进入容器
[root@master azl ] # docker exec -ti 98b98c1b083c[容器id] /bin/bash
10. 设置ssh免密登录
[root@hadoop ~ ] # cd ~/.ssh

如果出现这种情况,说明root用户下没有登陆过ssh,登陆一下就好了
执行ssh localhost
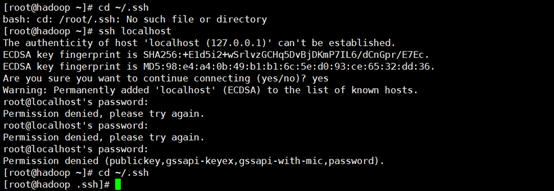
一路回车,再次执行cd ~/.ssh,成功进入.ssh目录
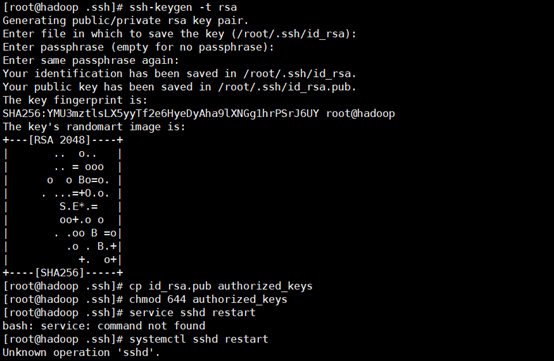
[root@hadoop ~ ] # ssh-keygen -t rsa,一路回车
生成两个文件,一个私钥,一个公钥,执行:cp id_rsa.pub authorized_keys
11. 本机无密钥登录
修改authorized_keys权限:chmod 644 authorized_keys
尝试登录和退出,好了,现在可以无密钥登录了。
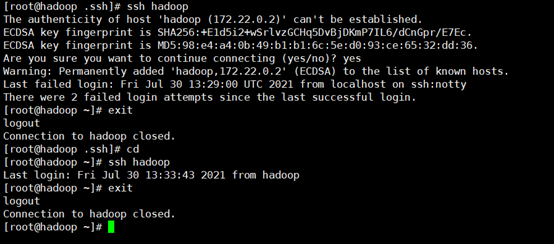
12. 建立临时文件夹
[root@hadoop ~]# mkdir /usr/local/hadoop-2.7.7/tmp
[root@hadoop ~]# mkdir -p /usr/local/hadoop-2.7.7/dfs/namenode_data
[root@hadoop ~]# mkdir -p /usr/local/hadoop-2.7.7/dfs/datanode_data
13. 切换到hadoop-2.7.7目录下
[root@hadoop ~]# cd /usr/local/ hadoop-2.7.7
[root@hadoop hadoop-2.7.7]# java -version
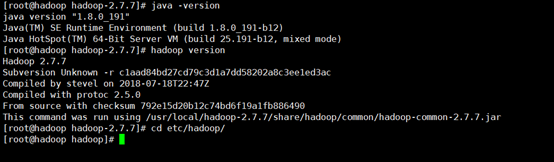
[root@hadoop hadoop-2.7.7]# cd etc/hadoop
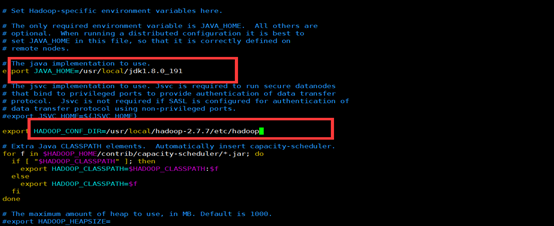
[root@hadoop hadoop]# vim hadoop-env.sh
按照如下配置,保存退出。
14. 修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml配置文件。
[root@hadoop hadoop]# vim core-site.xml
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.7.7/tmp</value>
</property>
</configuration>
[root@hadoop hadoop]# vim hdfs-site.xml
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/local/hadoop-2.7.7/dfs/namenode_data</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop-2.7.7/dfs/datanode_data</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
我们这里先复制一份mapred-site.xml.template并改名为mapred-site.xml
[root@hadoop hadoop]# cp mapred-site.xml.template mapred-site.xml
vim打开
[root@hadoop hadoop]# vim mapred-site.xml
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop:19888</value>
</property>
</configuration>
[root@hadoop hadoop]# vim yarn-site.xml
yarn-site.xml:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
15. 配置所有从属节点的主机名或ip地址,由于是单机版,所以指定本机即可
[root@hadoop hadoop]# vim slaves

16. 切换到根目录
[root@hadoop hadoop]# cd
[root@hadoop ~]# clear
格式化
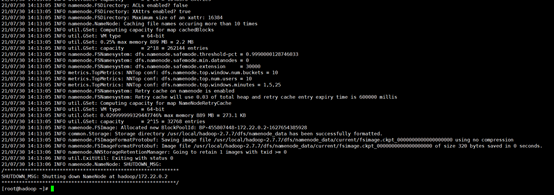
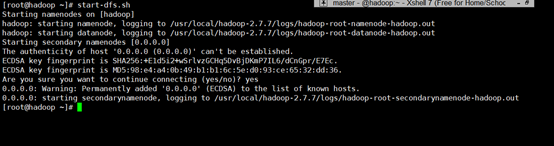
[root@hadoop ~]# start-dfs.sh
[root@hadoop ~]# start-yarn.sh

[root@hadoop ~]# mr-jobhistory-daemon.sh start historyserver

jps查看,现在hadoop环境已经配置好了,浏览器访问50070、19888端口可以看到hadoop界面
[root@hadoop ~]# jps
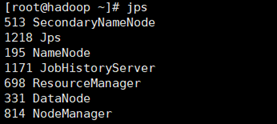
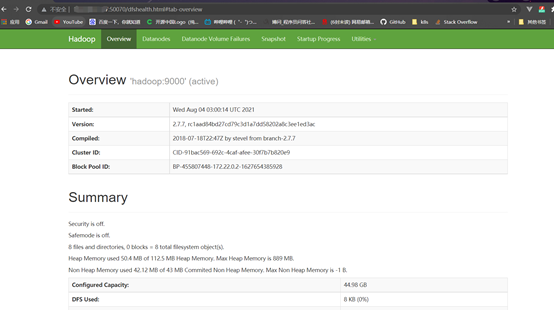
此时,我们的hadoop环境就已经搭建好了,下面在浏览器访问试试。
http://ip:50070
http://ip:19888
Docker环境下部署单机伪分布式hadoop环境
原文:https://www.cnblogs.com/azl2674/p/15098251.html