目标是在3台虚拟机上搭建一个Hadoop完全分布式集群。
集群规划如下:
|
? |
192.168.56.107 |
192.168.56.108 |
192.168.56.109 |
|
HDFS |
NameNode |
SecondaryNameNode |
|
|
YARN |
|
|
ResourceManager |
?
?
刚创建好的虚拟机默认不能ssh登陆,通过如下命令设置:
# 安装openssh $ sudo apt-get install openssh-server openssh-client # 启动 $ service ssh start
在mac上可以ssh登陆3台虚拟机,但是需要密码
注意:
这个时候使用iTerm工具,可以在mac上同步分发命令到多个会话,效果如下:
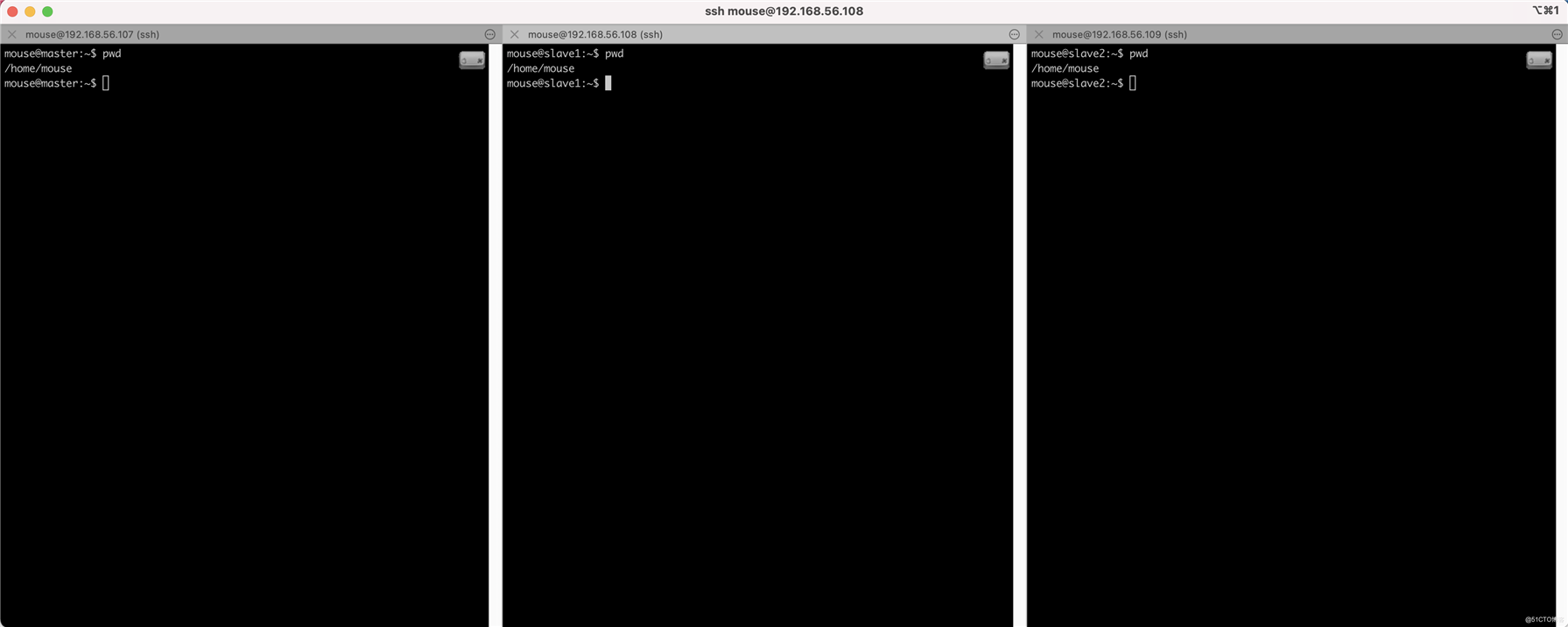
我们后续的命令默认都是操作三个节点,如果需要只在一个节点执行的命令,会单独说明
?
刚创建好的系统默认安装的是vim tiny版本,按键与显示不符,解决办法如下:
# Ubuntu预装的是vim tiny版本,需要删除后安装完整版 $ sudo apt-get remove vim-common $ sudo apt-get install vim
?
# 因为我是下载到mac上了,因此需要上传java到ubuntu $ scp mouse@192.168.1.12:/Users/mouse/Downloads/jdk-8u291-linux-x64.tar.gz /home/mouse/java
配置Java环境
$ vi ~/.bash_profile
加入如下2行代码
export JAVA_HOME=/home/mouse/java/jdk1.8.0_291 export PATH=$PATH:$JAVA_HOME/bin
使得代码生效,需要source一下
$ source ~/.bash_profile
验证java
$ java -version
?
ubuntu可以在"设置"->"共享"里更改主机名hostname
这三台虚拟机分别命名为
此外,在配置下host
# 修改hosts文件 $ vi /etc/hosts
加入如下内容
192.168.56.107 master 192.168.56.108 slave1 192.168.56.109 slave2
生成文件
$ ssh-keygen -t rsa -P ‘‘ -f ~/.ssh/id_rsa
复制到其他节点
$ ssh-copy-id -i master $ ssh-copy-id -i slave1 $ ssh-copy-id -i slave2
?
Hadoop有4个包含所有配置的配置文件,分别是:
但有一些配置是需要我们设置的,这4个文件如下:
?
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mouse/hadoop/log/hadoop_dir</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/mouse/hadoop/log/hadoop_dir/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/mouse/hadoop/log/hadoop_dir/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:9868</value>
</property>
</configuration>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave2</value>
</property>
<!-- 命令行执行hadoop classpath得到的值-->
<property>
<name>yarn.application.classpath</name>
<value>$hadoop classpath</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
export JAVA_HOME=/home/mouse/java/jdk1.8.0_291
master slave1 slave2
首次启动需要格式化namenode(注意:只在namenode服务器执行)
$ hadoop namenode -format
# 在namenode服务器执行 $ start-dfs.sh # 在resourcemanager服务器执行 $ start-yarn.sh
停止
# 在namenode服务器执行 $ stop-yarn.sh # 在resourcemanager服务器执行 $ stop-dfs.sh
快捷命令(不推荐)
$ start-all.sh $ stop-all.sh
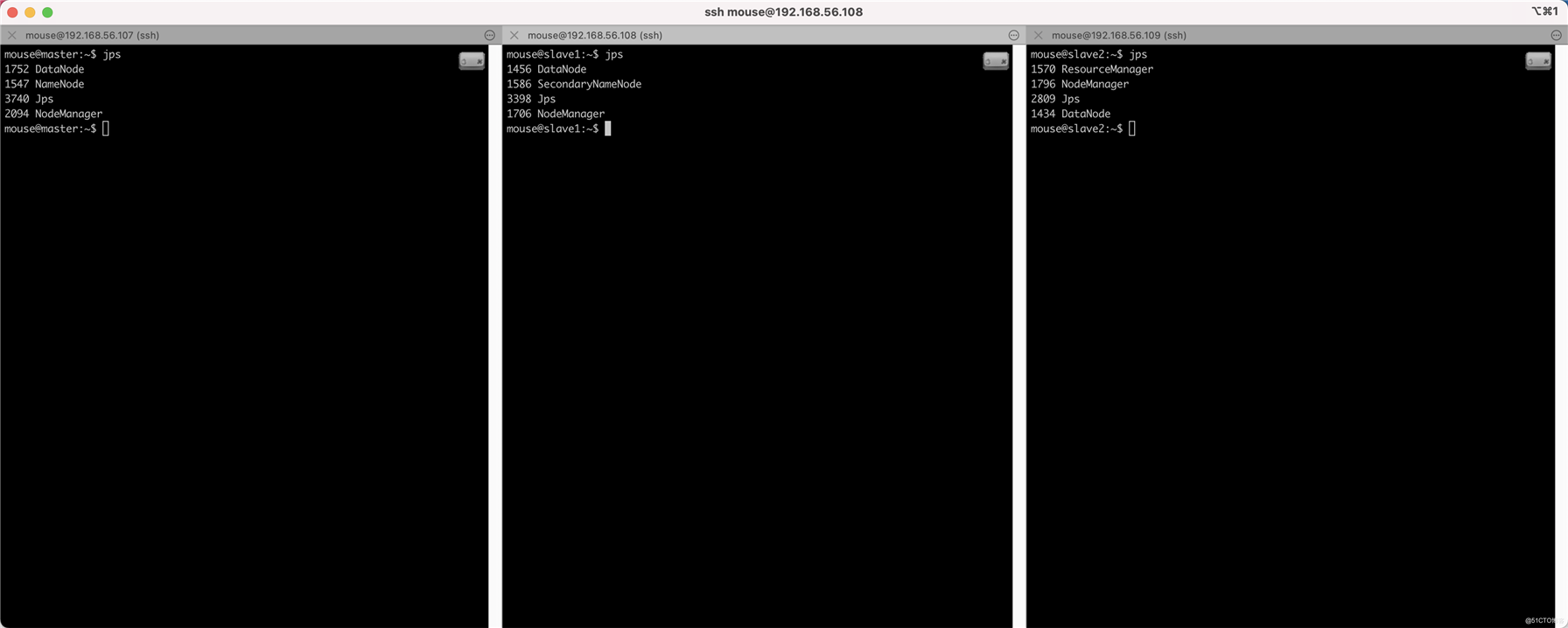
$ jps
结果如下图,说明全部启动成功了,符合预期
?
# NameNode http://master:9870 # ResourceManager http://slave2:8042

?
只在namenode节点上执行
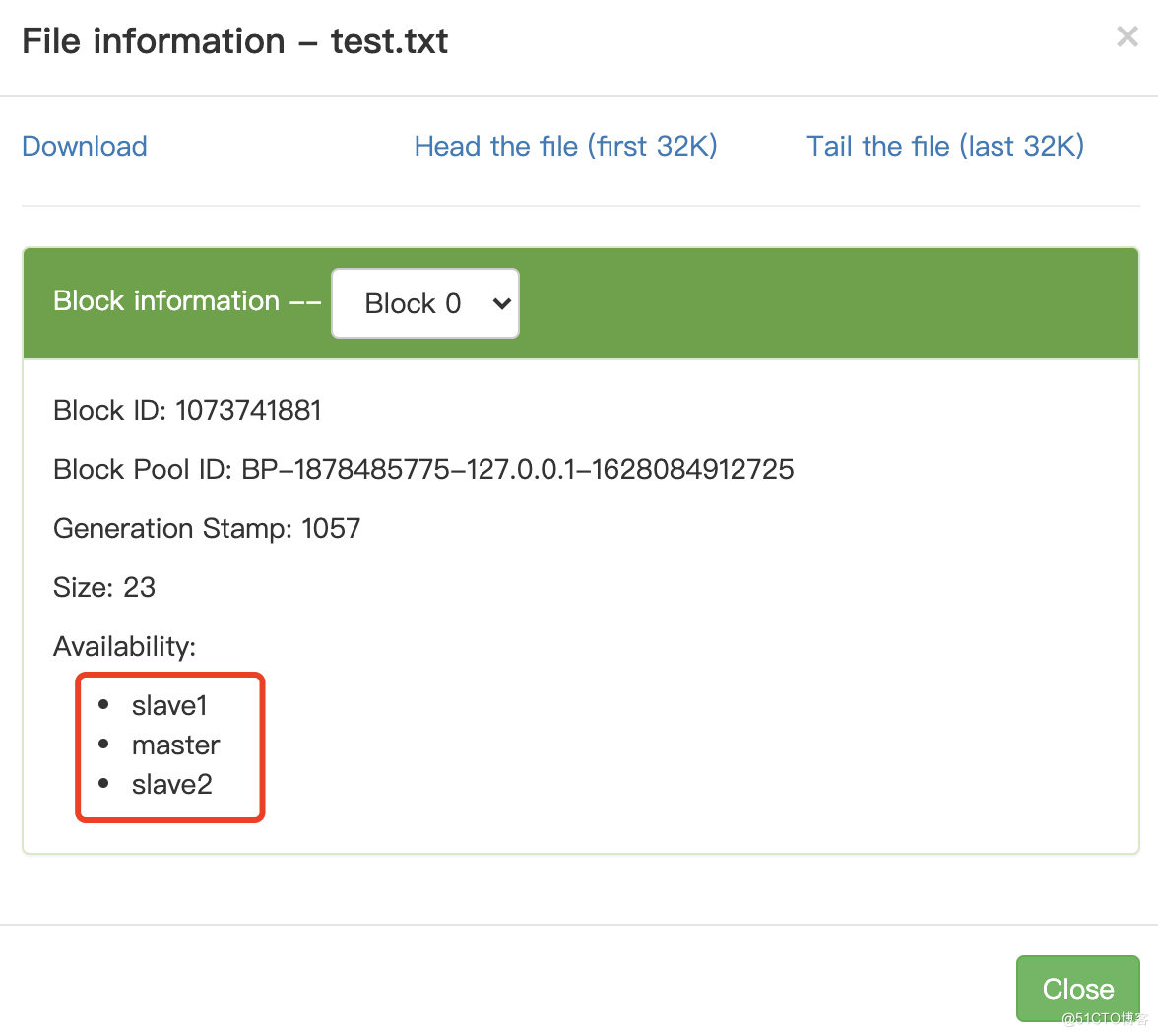
# /home/mouse/test.txt是本地路径 /是hdfs路径 $ hadoop dfs -put /home/mouse/test.txt /
访问http://master:9870/查看我们上传的文件,可以发现有3个副本,分别位于三个节点:
?
程序很简单,代码如下:
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (args.length != 2) {
System.err.println("Usage: WordCount <input path> <output path>");
System.exit(-1);
}
//指定作业执行规范 控制整个作业的运行
Job job = new Job();
job.setJarByClass(WordCount.class);
job.setJobName("Word Count");
//输入数据的路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//输出数据的路径 必须不存在
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
static class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(",");
for (String w : words) {
context.write(new Text(w), new LongWritable(1));
}
}
}
static class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long counter = 0;
for (LongWritable l : values) {
counter += l.get();
}
context.write(key, new LongWritable(counter));
}
}
}
使用IDEA工具
打包设置,参考如下截图:
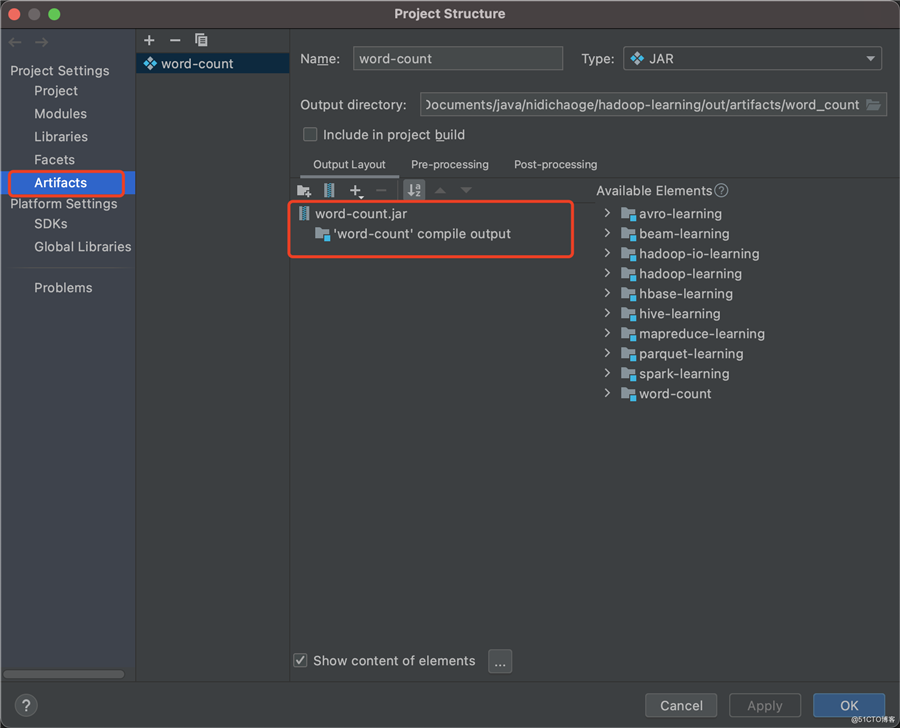
配置完成后,在"Build"->"Build Artifacts"即可
?
上传jar包
# 上传jar包 $ hdfs dfs -put [jar path] /
执行
# 必须使用全路径类名 # 输出目录必须不存在 $ hadoop jar word-count.jar com.mouse.word.count.WordCount /test.txt /user/mouse/wordcount
?
Done~
?
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
?
原文:https://blog.51cto.com/u_15323863/3289655