Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,数据是保存在内存里面的. 官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
Redis: 由C语言编写的一种NoSQL, 以key-value存在, 数据保存在内存里面 性能比较高
Redis应用场景:
redis中存储的数据是以key-value的形式存在的.其中value支持5种数据类型 .在日常开发中主要使用比较多的有字符串、哈希、字符串列表、字符串集合四种类型,其中最为常用的是字符串类型。
? 字符串(String)
? 哈希(hash) 类似HashMap
? 字符串列表(list)
? 字符串集合(set) 类似HashSet
? 有序的字符串集合(sorted-set或者叫zset)
string是redis最基本的类型,用的也是最多的,一个key对应一个value。 一个键最大能存储512MB.
| 命令 | 描述 |
|---|---|
| SET key value(重点) | 设置指定 key 的值 |
| GET key(重点) | 获取指定 key 的值 |
| DEL key | 删除key |
| GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value)。 |
| SETEX key seconds value(重点) | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位)。 |
| SETNX key value | 只有在 key 不存在时设置 key 的值。 |
| INCR key(重点) | 将 key 中储存的数字值增一。 |
| INCRBY key increment | 将 key 所储存的值加上给定的增量值(increment) 。 |
| DECR key | 将 key 中储存的数字值减一。 |
| DECRBY key decrement | key 所储存的值减去给定的减量值(decrement) 。 |
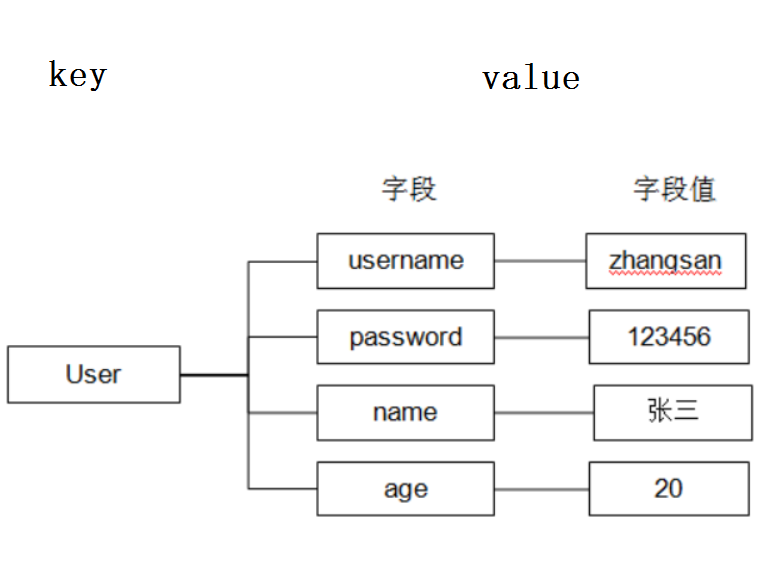
? 假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下: 保存、更新: User对象 ==> json(string) ==>redis
? 如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,下边讲的hash可以很好的解决这个问题
Redis中hash 是一个键值对集合。
? Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
? Redis存储hash可以看成是String key 和String value的map容器. 也就是说把值看成map集合.
? 它它特别适合存储对象相比较而言,将一个对象类型存储在Hash类型里要比存储在String类型里占用更少的内存空间并方便存取整个对象
| 命令 | 命令描述 |
|---|---|
| hset key filed value | 将哈希表 key 中的字段 field 的值设为 value |
| hmset key field1 value1 [field2 value2]...(重点) | 同时将多个 field-value (字段-值)对设置到哈希表 key 中 |
| hget key filed | 获取存储在哈希表中指定字段的值 |
| hmget key filed1 filed2 (重点) | 获取多个给定字段的值 |
| hdel key filed1 [filed2] (重点) | 删除一个或多个哈希表字段 |
| hlen key | 获取哈希表中字段的数量 |
| del key | 删除整个hash(对象) |
| HGETALL key (重点) | 获取在哈希表中指定 key 的所有字段和值 |
| HKEYS key | 获取所有哈希表中的字段 |
| HVALS key | 获取哈希表中所有值 |
ArrayList使用数组方式存储数据,所以根据索引查询数据速度快,而新增或者删除元素时需要涉及到位移操作,所以比较慢。
? LinkedList使用双向链表方式存储数据,每个元素都记录前后元素的指针,所以插入、删除数据时只是更改前后元素的指针指向即可,速度非常快。然后通过下标查询元素时需要从头开始索引,所以比较慢,但是如果查询前几个元素或后几个元素速度比较快。
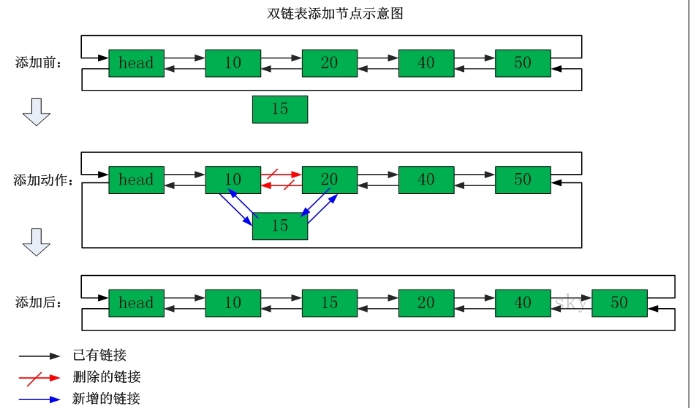
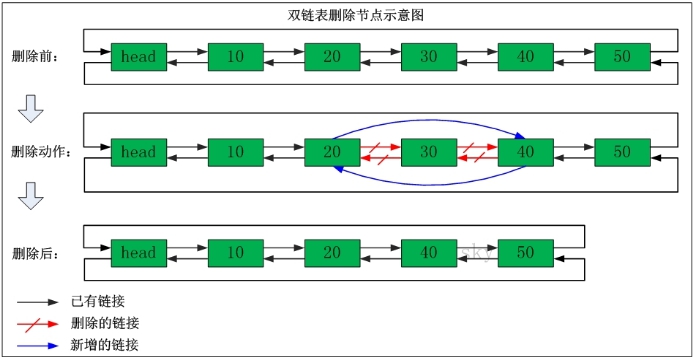
列表类型(list)可以存储一个有序的字符串列表(链表),常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
? 列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
如好友列表,粉丝列表,消息队列,最新消息排行等。
? rpush方法就相当于将消息放入到队列中,lpop/rpop就相当于从队列中拿去消息进行消费
| 命令 | 命令描述 |
|---|---|
| lpush key value1 value2...(重点) | 将一个或多个值插入到列表头部(左边) |
| rpush key value1 value2...(重点) | 在列表中添加一个或多个值(右边) |
| lpop key(重点) | 左边弹出一个 相当于移除第一个 |
| rpop key(重点) | 右边弹出一个 相当于移除最后一个 |
| llen key | 返回指定key所对应的list中元素个数 |
| LINDEX key index | 通过索引获取列表中的元素 |
| LINSERT key BEFORE| AFTER pivot value | 在列表的元素前或者后插入元素 |
1.List是一个字符串链表,left、right都可以插入添加;
2. 如果key不存在,创建新的链表;
如果键已存在,新增内容;
如果值全移除,对应的键也就消失了。
链表的操作无论是头和尾效率都极高,但假如是对中间元素进行操作,效率就一般.
Redis的Set是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中 集合是通过哈希表实现的,所以添加,删除,查找的时间复杂度都是O(1)。集合中最大的成员数为 2的32次方 -1 (4294967295, 每个集合可存储40多亿个成员)。
? Redis还提供了多个集合之间的交集、并集、差集的运算
? 特点:无序+唯一
? 投票记录
? 共同好友、共同兴趣、分类标签
| 命令 | 命令描述 |
|---|---|
| sadd key member1 [member2] (重点) | 向集合添加一个或多个成员 |
| srem key member1 [member2] | 移除一个成员或者多个成员 |
| smembers key | 返回集合中的所有成员,查看所有 |
| SCARD key | 获取集合的成员数 |
| SPOP key | 移除并返回集合中的一个随机元素 |
| SDIFF key1 [key2] (重点) | 返回给定所有集合的差集(key1有key2没有的) |
| SUNION key1 [key2] (重点) | 返回所有给定集合的并集(两个合并返回,重复的只算一个) |
| SINTER key1 [key2] (重点) | 返回给定所有集合的交集(返回两个重复的部分) |
共同好友
Redis 有序集合和集合一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
有序集合的成员是唯一的,但分数(score)却可以重复。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。 集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
特点: 有序(根据分数排序)+唯一
排行榜:例如视频网站需要对用户上传的视频做排行榜.
| 命令 | 命令描述 |
|---|---|
| ZADD key score member [score member ...](重点) | 增加元素 |
| ZSCORE key member | 获取元素的分数 |
| ZREM key member [member ...] | 删除元素 |
| ZCARD key | 获得集合中元素的数量 |
| ZRANGE key start stop[WITHSCORES] (重点) | 获得排名在某个范围的元素列表 |
| ZREVRANGE key start stop (重点) | 按照分数从高到低排序 |
keys *: 查询所有的key
exists key:判断是否有指定的key 若有返回1,否则返回0
expire key 秒数:设置这个key在缓存中的存活时间 (重要)
ttl key:展示指定key的剩余时间
? 若返回值为 -1:永不过期
? 若返回值为 -2:已过期或者不存在
del key:删除指定key (重要)
rename key 新key:重命名
type key:判断一个key的类型
ping :测试连接是否连接
? redis默认是16个数据库, 编号是从0~15. 【默认是0号库】
? Redis的高性能是由于其将所有数据都存储在了内存中,为了使Redis在重启之后仍能保证数据不丢失,需要将数据从内存中同步到硬盘(文件)中,这一过程就是持久化。
? Redis支持两种方式的持久化,一种是RDB方式,一种是AOF方式。可以单独使用其中一种或将二者结合使用。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。这种方式是就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。 这种方式是默认已经开启了,不需要配置.

| 关键字 | 时间(秒) | key修改数量 | 解释 |
|---|---|---|---|
| save | 900 | 1 | 每900秒(15分钟)至少有1个key发生变化,则dump内存快照 |
| save | 300 | 10 | 每300秒(5分钟)至少有10个key发生变化,则dump内存快照 |
| save | 60 | 10000 | 每60秒(1分钟)至少有10000个key发生变化,则dump内存快照 |
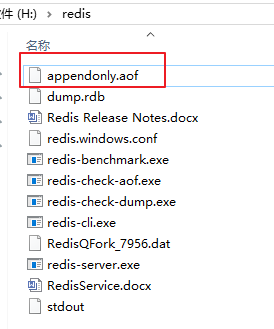
? AOF持久化机制会将每一个收到的写命令都通过write函数追加到文件中,默认的文件名是appendonly.aof。 这种方式默认是没有开启的,要使用时候需要配置.

redis-server.exe redis.windows.conf
开启aof持久化机制后,默认会在目录下产生一个appendonly.aof文件

原文:https://www.cnblogs.com/qiuji/p/15110628.html