
Conjugate gradients is a method to efficiently avoid the calculation of the inverse Hessian by iteratively descending conjugate directions. The inspiration for this approach follows from a careful study of the weakness of the method of steepest descent (see section 4.3 4.3 4.3 for details), where line searches are applied iteratively in the direction associated with the gradient. Figure 8.6 8.6 8.6 illustrates how the method of steepest descent, when applied in a quadratic bowl, progresses in a rather ineffective back-and-forth, zig-zag pattern. This happens because each line search direction, when given by the gradient, is guaranteed to be orthogonal to the previous line search direction.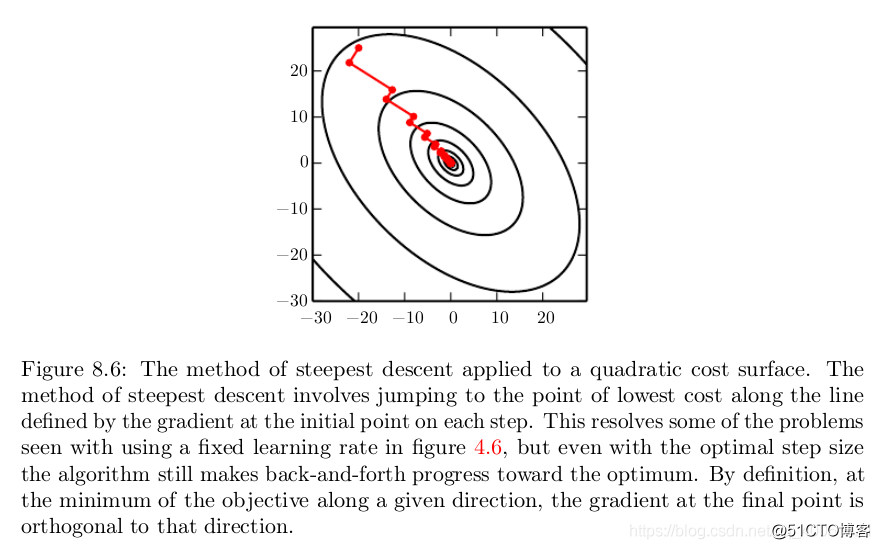
Let the previous search direction be d t ? 1 . \boldsymbol{d}_{t-1} . dt?1?. At the minimum, where the line search terminates, the directional derivative is zero in direction d t ? 1 : ? θ J ( θ ) \boldsymbol{d}_{t-1}: \nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) dt?1?:?θ?J(θ). d t ? 1 = 0 \boldsymbol{d}_{t-1}=0 dt?1?=0.
Since the gradient at this point defines the current search direction, d t = ? θ J ( θ ) \boldsymbol{d}_{t}=\nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta}) dt?=?θ?J(θ) will have no contribution in the direction d t ? 1 \boldsymbol{d}_{t-1} dt?1?. Thus d t \boldsymbol{d}_{t} dt? is orthogonal to d t ? 1 d_{t-1} dt?1?. This relationship between d t ? 1 d_{t-1} dt?1? and d t \boldsymbol{d}_{t} dt? is illustrated in figure 8.6 8.6 8.6 for multiple iterations of steepest descent.
As demonstrated in the figure, the choice of orthogonal directions of descent do not preserve the minimum along the previous search directions. This gives rise to the zig-zag pattern of progress, where by descending to the minimum in the current gradient direction, we must re-minimize the objective in the previous gradient direction. Thus, by following the gradient at the end of each line search we are, in a sense, undoing progress we have already made in the direction of the previous line search. The method of conjugate gradients seeks to address this problem.
In the method of conjugate gradients, we seek to find a search direction that is conjugate to the previous line search direction, i.e. it will not undo progress made in that direction. At training iteration t t t, the next search direction d t \boldsymbol{d}_{t} dt? takes the form:
d t = ? θ J ( θ ) + β t d t ? 1 \boldsymbol{d}_{t}=\nabla_{\boldsymbol{\theta}} J(\boldsymbol{\theta})+\beta_{t} \boldsymbol{d}_{t-1} dt?=?θ?J(θ)+βt?dt?1?
where β t \beta_{t} βt? is a coefficient whose magnitude controls how much of the direction, d t ? 1 d_{t-1} dt?1?, we should add back to the current search direction.
Two directions, d t \boldsymbol{d}_{t} dt? and d t ? 1 \boldsymbol{d}_{t-1} dt?1?, are defined as conjugate if d t ? H d t ? 1 = 0 \boldsymbol{d}_{t}^{\top} \boldsymbol{H} \boldsymbol{d}_{t-1}=0 dt??Hdt?1?=0, where H \boldsymbol{H} H is the Hessian matrix.
The straightforward way to impose conjugacy would involve calculation of the eigenvectors of H \boldsymbol{H} H to choose β t \beta_{t} βt?, which would not satisfy our goal of developing a method that is more computationally viable than Newton’s method for large problems. Can we calculate the conjugate directions without resorting to(借助) these calculations? Fortunately the answer to that is yes.
Two popular methods for computing the β t \beta_{t} βt? are:
For a quadratic surface, the conjugate directions ensure that the gradient along the previous direction does not increase in magnitude. We therefore stay at the minimum along the previous directions. As a consequence, in a k k k -dimensional parameter space, the conjugate gradient method requires at most k k k line searches to achieve the minimum. The conjugate gradient algorithm is given in algorithm 8.9. 8.9 . 8.9.
Nonlinear Conjugate Gradients: So far we have discussed the method of conjugate gradients as it is applied to quadratic objective functions. Of course, our primary interest in this chapter is to explore optimization methods for training neural networks and other related deep learning models where the corresponding objective function is far from quadratic. Perhaps surprisingly, the method of conjugate gradients is still applicable in this setting, though with some modification.
Practitioners report reasonable results in applications of the nonlinear conjugate gradients algorithm to training neural networks, though it is often beneficial to initialize the optimization with a few iterations of stochastic gradient descent before commencing(开始) nonlinear conjugate gradients. Also, while the (nonlinear) conjugate gradients algorithm has traditionally been cast as a batch method, minibatch versions have been used successfully for the training of neural networks( Le et al. , 2011). Adaptations of conjugate gradients specifically for neural networks have been proposed earlier, such as the scaled conjugate gradients algorithm ( Moller , 1993).
The Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm attempts to bring some of the advantages of Newton’s method without the computational burden. In that respect, BFGS is similar to the conjugate gradient method. However, BFGS takes a more direct approach to the approximation of Newton’s update. Recall that Newton’s update is given by
θ ? = θ 0 ? H ? 1 ? θ J ( θ 0 ) \boldsymbol{\theta}^{*}=\boldsymbol{\theta}_{0}-\boldsymbol{H}^{-1} \nabla_{\boldsymbol{\theta}} J\left(\boldsymbol{\theta}_{0}\right) θ?=θ0??H?1?θ?J(θ0?)
where H \boldsymbol{H} H is the Hessian of J J J with respect to θ \boldsymbol{\theta} θ evaluated at θ 0 \boldsymbol{\theta}_{0} θ0?. The primary computational difficulty in applying Newton’s update is the calculation of the inverse Hessian H ? 1 \boldsymbol{H}^{-1} H?1.
The approach adopted by quasi-Newton methods (of which the BFGS algorithm is the most prominent) is to approximate the inverse with a matrix M t M_{t} Mt? that is iteratively refined by low rank updates to become a better approximation of H ? 1 \boldsymbol{H}^{-1} H?1.
The specification and derivation of the BFGS approximation is given in many textbooks on optimization, including Lue ( 1984 ) (1984) (1984).
Once the inverse Hessian approximation M t M_{t} Mt? is updated, the direction of descent ρ t \rho_{t} ρt? is determined by ρ t = M t g t \rho_{t}=M_{t} g_{t} ρt?=Mt?gt?. A line search is performed in this direction to determine the size of the step, ? ? \epsilon^{*} ??, taken in this direction. The final update to the parameters is given by:
θ t + 1 = θ t + ? ? ρ t \boldsymbol{\theta}_{t+1}=\boldsymbol{\theta}_{t}+\epsilon^{*} \boldsymbol{\rho}_{t} θt+1?=θt?+??ρt?
Like the method of conjugate gradients, the BFGS algorithm iterates a series of line searches with the direction incorporating second-order information. However unlike conjugate gradients, the success of the approach is not heavily dependent on the line search finding a point very close to the true minimum along the line. Thus, relative to conjugate gradients, BFGS has the advantage that it can spend less time refining each line search. On the other hand, the BFGS algorithm must store the inverse Hessian matrix, M M M, that requires O ( n 2 ) O\left(n^{2}\right) O(n2) memory, making BFGS impractical for most modern deep learning models that typically have millions of parameters.
Limited Memory BFGS (or L-BFGS) The memory costs of the BFGS algorithm can be significantly decreased by avoiding storing the complete inverse Hessian approximation M M M. The L-BFGS algorithm computes the approximation M M M using the same method as the BFGS algorithm, but beginning with the assumption that M ( t ? 1 ) M^{(t-1)} M(t?1) is the identity matrix, rather than storing the approximation from one step to the next. If used with exact line searches, the directions defined by L-BFGS are mutually conjugate.
However, unlike the method of conjugate gradients, this procedure remains well behaved when the minimum of the line search is reached only approximately. The L-BFGS strategy with no storage described here can be generalized to include more information about the Hessian by storing some of the vectors used to update M M M at each time step, which costs only O ( n ) O(n) O(n) per step.
Batch normalization (Ioffe and Szegedy, 2015) is one of the most exciting recent innovations in optimizing deep neural networks and it is actually not an optimization algorithm at all. Instead, it is a method of adaptive reparametrization, motivated by the difficulty of training very deep models.
Very deep models involve the composition of several functions or layers. The gradient tells how to update each parameter, under the assumption that the other layers do not change. In practice, we update all of the layers simultaneously. When we make the update, unexpected results can happen because many functions composed together are changed simultaneously, using updates that were computed under the assumption that the other functions remain constant.
As a simple example, suppose we have a deep neural network that has only one unit per layer and does not use an activation function at each hidden layer: y ^ = x w 1 w 2 w 3 … w l \hat{y}=x w_{1} w_{2} w_{3} \ldots w_{l} y^?=xw1?w2?w3?…wl?. Here, w i w_{i} wi? provides the weight used by layer i i i. The output of layer i i i is h i = h i ? 1 w i h_{i}=h_{i-1} w_{i} hi?=hi?1?wi?. The output y ^ \hat{y} y^? is a linear function of the input x x x, but a nonlinear function of the weights w i . w_{i} . wi?. Suppose our cost function has put a gradient of 1 on y ^ \hat{y} y^?, so we wish to decrease y ^ \hat{y} y^? slightly. The back-propagation algorithm can then compute a gradient g = ? w y ^ . g=\nabla_{\boldsymbol{w}} \hat{y} . g=?w?y^?.
Consider what happens when we make an update w ← w ? ? g \boldsymbol{w} \leftarrow \boldsymbol{w}-\epsilon \boldsymbol{g} w←w??g. The first-order Taylor series approximation of y ^ \hat{y} y^? predicts that the value of y ^ \hat{y} y^? will decrease by ? g ? g \epsilon \boldsymbol{g}^{\top} \boldsymbol{g} ?g?g. If we wanted to decrease y ^ \hat{y} y^? by . 1 .1 .1, this first-order information available in the gradient suggests we could set the learning rate ? \epsilon ? to . 1 g ? g \frac{.1}{g^{\top} g} g?g.1?. However, the actual update will include second-order and third-order effects, on up to effects of order l l l. The new value of y ^ \hat{y} y^? is given by
x ( w 1 ? ? g 1 ) ( w 2 ? ? g 2 ) … ( w l ? ? g l ) x\left(w_{1}-\epsilon g_{1}\right)\left(w_{2}-\epsilon g_{2}\right) \ldots\left(w_{l}-\epsilon g_{l}\right) x(w1???g1?)(w2???g2?)…(wl???gl?)
An example of one second-order term arising from this update is ? 2 g 1 g 2 ∏ i = 3 l w i \epsilon^{2} g_{1} g_{2} \prod_{i=3}^{l} w_{i} ?2g1?g2?∏i=3l?wi? This term might be negligible if ∏ i = 3 l w i \prod_{i=3}^{l} w_{i} ∏i=3l?wi? is small, or might be exponentially large if the weights on layers 3 through l l l are greater than 1. 1 . 1. This makes it very hard to choose an appropriate learning rate, because the effects of an update to the parameters for one layer depends so strongly on all of the other layers. Second-order optimization algorithms address this issue by computing an update that takes these second-order interactions into account, but we can see that in very deep networks, even higher-order interactions can be significant. Even second-order optimization algorithms are expensive and usually require numerous approximations that prevent them from truly accounting for all significant second-order interactions. Building an n n n -th order optimization algorithm for n > 2 n>2 n>2 thus seems hopeless. What can we do instead?
Batch normalization provides an elegant way of reparametrizing almost any deep network. The reparametrization significantly reduces the problem of coordinating updates across many layers. Batch normalization can be applied to any input or hidden layer in a network. Let H \boldsymbol{H} H be a minibatch of activations of the layer to normalize, arranged as a design matrix, with the activations for each example appearing in a row of the matrix. To normalize H \boldsymbol{H} H, we replace it with
H ′ = H ? μ σ \boldsymbol{H}^{\prime}=\frac{\boldsymbol{H}-\boldsymbol{\mu}}{\sigma} H′=σH?μ?
where μ \boldsymbol{\mu} μ is a vector containing the mean of each unit and σ \boldsymbol{\sigma} σ is a vector containing the standard deviation of each unit. The arithmetic here is based on broadcasting the vector μ \boldsymbol{\mu} μ and the vector σ \boldsymbol{\sigma} σ to be applied to every row of the matrix H \boldsymbol{H} H. Within each row, the arithmetic is element-wise, so H i , j H_{i, j} Hi,j? is normalized by subtracting μ j \mu_{j} μj? and dividing by σ j . \sigma_{j} . σj?. The rest of the network then operates on H ′ \boldsymbol{H}^{\prime} H′ in exactly the same way that the original network operated on H \boldsymbol{H} H.
At training time,
μ = 1 m ∑ i H i , : \boldsymbol{\mu}=\frac{1}{m} \sum_{i} \boldsymbol{H}_{i,:} μ=m1?i∑?Hi,:?
and
σ = δ + 1 m ∑ i ( H ? μ ) i 2 \boldsymbol{\sigma}=\sqrt{\delta+\frac{1}{m} \sum_{i}(\boldsymbol{H}-\boldsymbol{\mu})_{i}^{2}} σ=δ+m1?i∑?(H?μ)i2? ?
where δ \delta δ is a small positive value such as 1 0 ? 8 10^{-8} 10?8 imposed to avoid encountering the undefined gradient of z \sqrt{z} z ? at z = 0 z=0 z=0. Crucially, we back-propagate through these operations for computing the mean and the standard deviation, and for applying them to normalize H \boldsymbol{H} H.
This means that the gradient will never propose an operation that acts simply to increase the standard deviation or mean of h i ; h_{i} ; hi?;
the normalization operations remove the effect of such an action and zero out its component in the gradient. This was a major innovation of the batch normalization approach. Previous approaches had involved adding penalties to the cost function to encourage units to have normalized activation statistics or involved intervening to renormalize unit statistics after each gradient descent step. The former approach usually resulted in imperfect normalization and the latter usually resulted in significant wasted time as the learning algorithm repeatedly proposed changing the mean and variance and the normalization step repeatedly undid this change.
Revisiting the y ^ = x w 1 w 2 … w l \hat{y}=x w_{1} w_{2} \ldots w_{l} y^?=xw1?w2?…wl? example, we see that we can mostly resolve the difficulties in learning this model by normalizing h l ? 1 h_{l-1} hl?1?. Suppose that x x x is drawn from a unit Gaussian. Then h l ? 1 h_{l-1} hl?1? will also come from a Gaussian, because the transformation from x x x to h l h_{l} hl? is linear. However, h l ? 1 h_{l-1} hl?1? will no longer have zero mean and unit variance. After applying batch normalization, we obtain the normalized h ^ l ? 1 \hat{h}_{l-1} h^l?1? that restores the zero mean and unit variance properties. For almost any update to the lower layers, h ^ l ? 1 \hat{h}_{l-1} h^l?1? will remain a unit Gaussian. The output y ^ \hat{y} y^? may then be learned as a simple linear function y ^ = w l h ^ l ? 1 \hat{y}=w_{l} \hat{h}_{l-1} y^?=wl?h^l?1?. Learning in this model is now very simple because the parameters at the lower layers simply do not have an effect in most cases; their output is always renormalized to a unit Gaussian. In some corner cases, the lower layers can have an effect. Changing one of the lower layer weights to 0 can make the output become degenerate, and changing the sign of one of the lower weights can flip the relationship between h ^ l ? 1 \hat{h}_{l-1} h^l?1? and y y y. These situations are very rare. Without normalization, nearly every update would have an extreme effect on the statistics of h l ? 1 . h_{l-1} . hl?1?. Batch normalization has thus made this model significantly easier to learn.
In this example, the ease of learning of course came at the cost of making the lower layers useless. In our linear example, the lower layers no longer have any harmful effect, but they also no longer have any beneficial effect. This is because we have normalized out the first and second order statistics, which is all that a linear network can influence. In a deep neural network with nonlinear activation functions, the lower layers can perform nonlinear transformations of the data, so they remain useful. Batch normalization acts to standardize only the mean and variance of each unit in order to stabilize learning, but allows the relationships between units and the nonlinear statistics of a single unit to change.
Because the final layer of the network is able to learn a linear transformation, we may actually wish to remove all linear relationships between units within a layer. Indeed, this is the approach taken by Desjardins et al. (2015), who provided the inspiration for batch normalization. Unfortunately, eliminating all linear interactions is much more expensive than standardizing the mean and standard deviation of each individual unit, and so far batch normalization remains the most practical approach.
Normalizing the mean and standard deviation of a unit can reduce the expressive power of the neural network containing that unit. In order to maintain the expressive power of the network, it is common to replace the batch of hidden unit activations H \boldsymbol{H} H with γ H ′ + β \gamma \boldsymbol{H}^{\prime}+\boldsymbol{\beta} γH′+β rather than simply the normalized H ′ \boldsymbol{H}^{\prime} H′. The variables γ \gamma γ and β \boldsymbol{\beta} β are learned parameters that allow the new variable to have any mean and standard deviation. At first glance, this may seem useless-why did we set the mean to 0 \mathbf{0} 0, and then introduce a parameter that allows it to be set back to any arbitrary value β ? \beta ? β? The answer is that the new parametrization can represent the same family of functions of the input as the old parametrization, but the new parametrization has different learning dynamics. In the old parametrization, the mean of H \boldsymbol{H} H was determined by a complicated interaction between the parameters in the layers below H \boldsymbol{H} H. In the new parametrization, the mean of γ H ′ + β \gamma \boldsymbol{H}^{\prime}+\boldsymbol{\beta} γH′+β is determined solely by β \beta β. The new parametrization is much easier to learn with gradient descent.
Most neural network layers take the form of ? ( X W + b ) \phi(\boldsymbol{X} \boldsymbol{W}+\boldsymbol{b}) ?(XW+b) where ? \phi ? is some fixed nonlinear activation function such as the rectified linear transformation. It is natural to wonder whether we should apply batch normalization to the input X \boldsymbol{X} X, or to the transformed value X W + b \boldsymbol{X} \boldsymbol{W}+\boldsymbol{b} XW+b. Ioffe and Szegedy ( 2015 )recommend the latter. More specifically, X W + b \boldsymbol{X} \boldsymbol{W}+\boldsymbol{b} XW+b should be replaced by a normalized version of X W X W XW. The bias term should be omitted because it becomes redundant with the β \beta β parameter applied by the batch normalization reparametrization. The input to a layer is usually the output of a nonlinear activation function such as the rectified linear function in a previous layer. The statistics of the input are thus more non-Gaussian and less amenable to standardization by linear operations.
In convolutional networks, described in chapter 9, it is important to apply the same normalizing μ \mu μ and σ \sigma σ at every spatial location within a feature map, so that the statistics of the feature map remain the same regardless of spatial location.
In some cases, it may be possible to solve an optimization problem quickly by breaking it into separate pieces. If we minimize f ( x ) f(x) f(x) with respect to a single variable x i x_{i} xi?, then minimize it with respect to another variable x j x_{j} xj? and so on, repeatedly cycling through all variables, we are guaranteed to arrive at a (local) minimum. This practice is known as coordinate descent, because we optimize one coordinate at a time. More generally, block coordinate descent refers to minimizing with respect to a subset of the variables simultaneously. The term “coordinate descent” is often used to refer to block coordinate descent as well as the strictly individual coordinate descent.
Coordinate descent makes the most sense when the different variables in the optimization problem can be clearly separated into groups that play relatively isolated roles, or when optimization with respect to one group of variables is significantly more efficient than optimization with respect to all of the variables.
For example, consider the cost function
J ( H , W ) = ∑ i , j ∣ H i , j ∣ + ∑ i , j ( X ? W ? H ) i , j 2 J(\boldsymbol{H}, \boldsymbol{W})=\sum_{i, j}\left|H_{i, j}\right|+\sum_{i, j}\left(\boldsymbol{X}-\boldsymbol{W}^{\top} \boldsymbol{H}\right)_{i, j}^{2} J(H,W)=i,j∑?∣Hi,j?∣+i,j∑?(X?W?H)i,j2?
This function describes a learning problem called sparse coding, where the goal is to find a weight matrix W \boldsymbol{W} W that can linearly decode a matrix of activation values H H H to reconstruct the training set X X X. Most applications of sparse coding also involve weight decay or a constraint on the norms of the columns of W \boldsymbol{W} W, in order to prevent the pathological solution with extremely small H \boldsymbol{H} H and large W \boldsymbol{W} W.
The function J J J is not convex. However, we can divide the inputs to the training algorithm into two sets: the dictionary parameters W W W and the code representations H \boldsymbol{H} H. Minimizing the objective function with respect to either one of these sets of variables is a convex problem. Block coordinate descent thus gives us an optimization strategy that allows us to use efficient convex optimization algorithms, by alternating between optimizing W \boldsymbol{W} W with H \boldsymbol{H} H fixed, then optimizing H \boldsymbol{H} H with W \boldsymbol{W} W fixed.
Coordinate descent is not a very good strategy when the value of one variable strongly influences the optimal value of another variable, as in the function f ( x ) = f(\boldsymbol{x})= f(x)= ( x 1 ? x 2 ) 2 + α ( x 1 2 + x 2 2 ) \left(x_{1}-x_{2}\right)^{2}+\alpha\left(x_{1}^{2}+x_{2}^{2}\right) (x1??x2?)2+α(x12?+x22?) where α \alpha α is a positive constant. The first term encourages the two variables to have similar value, while the second term encourages them to be near zero. The solution is to set both to zero. Newton’s method can solve the problem in a single step because it is a positive definite quadratic problem. However, for small α \alpha α, coordinate descent will make very slow progress because the first term does not allow a single variable to be changed to a value that differs significantly from the current value of the other variable.
Sometimes, directly training a model to solve a specific task can be too ambitious if the model is complex and hard to optimize or if the task is very difficult. It is sometimes more effective to train a simpler model to solve the task, then make the model more complex. It can also be more effective to train the model to solve a simpler task, then move on to confront the final task. These strategies that involve training simple models on simple tasks before confronting the challenge of training the desired model to perform the desired task are collectively known as pretraining.
Greedy algorithms break a problem into many components, then solve for the optimal version of each component in isolation. Unfortunately, combining the individually optimal components is not guaranteed to yield an optimal complete solution. However, greedy algorithms can be computationally much cheaper than algorithms that solve for the best joint solution, and the quality of a greedy solution is often acceptable if not optimal. Greedy algorithms may also be followed by a fine-tuning stage in which a joint optimization algorithm searches for an optimal solution to the full problem. Initializing the joint optimization algorithm with a greedy solution can greatly speed it up and improve the quality of the solution it finds.
Pretraining, and especially greedy pretraining, algorithms are ubiquitous(无处不在) in deep learning. In this section, we describe specifically those pretraining algorithms that break supervised learning problems into other simpler supervised learning problems. This approach is known as greedy supervised pretraining.
In the original (Bengio et al., 2007) version of greedy supervised pretraining, each stage consists of a supervised learning training task involving only a subset of the layers in the final neural network. An example of greedy supervised pretraining is illustrated in figure below, in which each added hidden layer is pretrained as part of a shallow supervised MLP, taking as input the output of the previously trained hidden layer.
Instead of pretraining one layer at a time, Simonyan and Zisserman ( 2015 ) pretrain a deep convolutional network (eleven weight layers) and then use the first four and last three layers from this network to initialize even deeper networks (with up to nineteen layers of weights). The middle layers of the new, very deep network are initialized randomly. The new network is then jointly trained.
Another option, explored by Yu et al. (2010) is to use the outputs of the previously trained MLPs, as well as the raw input, as inputs for each added stage.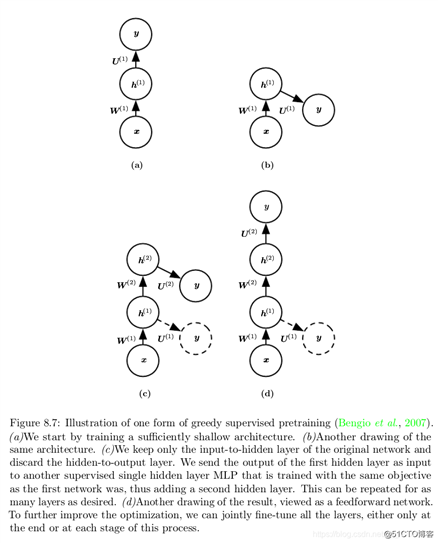
Why would greedy supervised pretraining help? The hypothesis initially discussed by Bengio et al. (2007) is that it helps to provide better guidance to the intermediate levels of a deep hierarchy. In general, pretraining may help both in terms of optimization and in terms of generalization.
An approach related to supervised pretraining extends the idea to the context of transfer learning: Yosinski et al (2014) pretrain a deep convolutional net with 8 layers of weights on a set of tasks (a subset of the 1000 ImageNet object categories) and then initialize a same-size network with the first k k k layers of the first net. All the layers of the second network (with the upper layers initialized randomly) are then jointly trained to perform a different set of tasks (another subset of the 1000 ImageNet object categories), with fewer training examples than for the first set of tasks. Other approaches to transfer learning with neural networks are discussed in section 15.2.
Another related line of work is the FitNets (Romero et al., 2015) approach. This approach begins by training a network that has low enough depth and great enough width (number of units per layer) to be easy to train.
This network then becomes a teacher for a second network, designated the student.
The student network is much deeper and thinner (eleven to nineteen layers) and would be difficult to train with SGD under normal circumstances. The training of the student network is made easier by training the student network not only to predict the output for the original task, but also to predict the value of the middle layer of the teacher network. This extra task provides a set of hints about how the hidden layers should be used and can simplify the optimization problem. Hints on middle layers may thus be one of the tools to help train neural networks that otherwise seem difficult to train, but other optimization techniques or changes in the architecture may also solve the problem.
To improve optimization, the best strategy is not always to improve the optimization algorithm. Instead, many improvements in the optimization of deep models have come from designing the models to be easier to optimize.
In principle, we could use activation functions that increase and decrease in jagged non-monotonic patterns. However, this would make optimization extremely difficult. In practice, it is more important to choose a model family that is easy to optimize than to use a powerful optimization algorithm. Most of the advances in neural network learning over the past 30 years have been obtained by changing the model family rather than changing the optimization procedure. Stochastic gradient descent with momentum, which was used to train neural networks in the 1980 s, remains in use in modern state of the art neural network applications.
Specifically, modern neural networks reflect a design choice to use linear transformations between layers and activation functions that are differentiable almost everywhere and have significant slope in large portions of their domain. In particular, model innovations like the LSTM, rectified linear units and maxout units have all moved toward using more linear functions than previous models like deep networks based on sigmoidal units. These models have nice properties that make optimization easier. The gradient flows through many layers provided that the Jacobian of the linear transformation has reasonable singular values. Moreover, linear functions consistently increase in a single direction, so even if the model’s output is very far from correct, it is clear simply from computing the gradient which direction its output should move to reduce the loss function. In other words, modern neural nets have been designed so that their local gradient information corresponds reasonably well to moving toward a distant solution.
Other model design strategies can help to make optimization easier. For example, linear paths or skip connections between layers reduce the length of the shortest path from the lower layer’s parameters to the output, and thus mitigate the vanishing gradient problem (Srivas et al., 2015 ). A related idea to skip connections is adding extra copies of the output that are attached to the intermediate hidden layers of the network, as in GoogLeNet (Szegedy et al., 2014 a 2014 \mathrm{a} 2014a and deeply-supervised nets (Lee et al., 2014). These “auxiliary heads” are trained to perform the same task as the primary output at the top of the network in order to ensure that the lower layers receive a large gradient. When training is complete the auxiliary heads may be discarded. This is an alternative to the pretraining strategies, which were introduced in the previous section. In this way, one can train jointly all the layers in a single phase but change the architecture, so that intermediate layers (especially the lower ones) can get some hints about what they should do, via a shorter path. These hints provide an error signal to lower layers.
As argued in section 8.2.7, many of the challenges in optimization arise from the global structure of the cost function and cannot be resolved merely by making better estimates of local update directions. The predominant strategy for overcoming this problem is to attempt to initialize the parameters in a region that is connected to the solution by a short path through parameter space that local descent can discover.
Continuation methods are a family of strategies that can make optimization easier by choosing initial points to ensure that local optimization spends most of its time in well-behaved regions of space. The idea behind continuation methods is to construct a series of objective functions over the same parameters. In order to minimize a cost function J ( θ ) J(\boldsymbol{\theta}) J(θ), we will construct new cost functions { J ( 0 ) , … , J ( n ) } \left\{J^{(0)}, \ldots, J^{(n)}\right\} {J(0),…,J(n)}. These cost functions are designed to be increasingly difficult, with J ( 0 ) J^{(0)} J(0) being fairly easy to minimize, and J ( n ) J^{(n)} J(n), the most difficult, being J ( θ ) J(\theta) J(θ), the true cost function motivating the entire process.
When we say that J ( i ) J^{(i)} J(i) is easier than J ( i + 1 ) J^{(i+1)} J(i+1), we mean that it is well behaved over more of θ \boldsymbol{\theta} θ space. A random initialization is more likely to land in the region where local descent can minimize the cost function successfully because this region is larger. The series of cost functions are designed so that a solution to one is a good initial point of the next. We thus begin by solving an easy problem then refine the solution to solve incrementally harder problems until we arrive at a solution to the true underlying problem.
Traditional continuation methods (predating the use of continuation methods for neural network training) are usually based on smoothing the objective function. See Wu (1997) for an example of such a method and a review of some related methods. Continuation methods are also closely related to simulated annealing, which adds noise to the parameters (Kirkpatrick et al., 1983). Continuation methods have been extremely successful in recent years. See Mobe (2015) for an overview of recent literature, especially for AI applications. Continuation methods traditionally were mostly designed with the goal of overcoming the challenge of local minima. Specifically, they were designed to reach a global minimum despite the presence of many local minima. To do so, these continuation methods would construct easier cost functions by “blurring” the original cost function. This blurring operation can be done by approximating via sampling.
J ( i ) ( θ ) = E θ ′ ~ N ( θ ′ ; θ , σ ( i ) 2 ) J ( θ ′ ) J^{(i)}(\boldsymbol{\theta})=\mathbb{E}_{\theta^{\prime} \sim \mathcal{N}\left(\boldsymbol{\theta}^{\prime} ; \boldsymbol{\theta}, \sigma^{(i) 2}\right)} J\left(\boldsymbol{\theta}^{\prime}\right) J(i)(θ)=Eθ′~N(θ′;θ,σ(i)2)?J(θ′)
The intuition for this approach is that some non-convex functions become approximately convex when blurred.
In many cases, this blurring preserves enough information about the location of a global minimum that we can find the global minimum by solving progressively less blurred versions of the problem.
This approach can break down in three different ways.
First, it might successfully define a series of cost functions where the first is convex and the optimum tracks from one function to the next arriving at the global minimum, but it might require so many incremental cost functions that the cost of the entire procedure remains high. NP-hard optimization problems remain NP-hard, even when continuation methods are applicable.
The other two ways that continuation methods fail both correspond to the method not being applicable. First, the function might not become convex. no matter how much it is blurred. Consider for example the function J ( θ ) = ? θ ? θ J(\boldsymbol{\theta})=-\boldsymbol{\theta}^{\top} \boldsymbol{\theta} J(θ)=?θ?θ. Second, the function may become convex as a result of blurring, but the minimum of this blurred function may track to a local rather than a global minimum of the original cost function.
Though continuation methods were mostly originally designed to deal with the problem of local minima, local minima are no longer believed to be the primary problem for neural network optimization. Fortunately, continuation methods can still help. The easier objective functions introduced by the continuation method can eliminate flat regions, decrease variance in gradient estimates, improve conditioning of the Hessian matrix, or do anything else that will either make local updates easier to compute or improve the correspondence between local update directions and progress toward a global solution.
Bengio et al. (2009) observed that an approach called curriculum learning or shaping can be interpreted as a continuation method. Curriculum learning is based on the idea of planning a learning process to begin by learning simple concepts and progress to learning more complex concepts that depend on these simpler concepts. This basic strategy was previously known to accelerate progress in animal training (Skinnesn. 2004: Krueger and Dayan, 2009) and machine94). Bengio ef learning (Solomonoff, 1989; Elman, 1993; Sanger, 19. justified this strategy as a continuation method, where earlier J ( i ) J^{(i)} J(i) are made easier by increasing the influence of simpler examples (either by assigning their contributions to the cost function larger coefficients, or by sampling them more frequently), and experimentally demonstrated that better results could be obtained by following a curriculum on a large-scale neural language modeling task. Curriculum learning has been successful on a wide range of natural language (S Whoherte at alu. 2011a: Mikolov et al., 2011b; Tu and Honavar, 2011) and computes vision (Kumar et al., 2010; Lee and Grauman, 2011; Supancic and Ramanan, 201 tasks.
Another important contribution to research on curriculum learning arose in the context of training recurrent neural networks to capture long-term dependencies:
Zaremba and Sutskever (2014) found that much better results were obtained with a stochastic curriculum, in which a random mix of easy and difficult examples is always presented to the learner, but where the average proportion of the more difficult examples (here, those with longer-term dependencies) is gradually increased. With a deterministic curriculum, no improvement over the baseline (ordinary training from the full training set) was observed.
The optimization methods discussed in this chapter are often directly applicable to these specialized architectures with little or no modification.
?
Optimization for Training Deep Models(3)
原文:https://blog.51cto.com/u_13393656/3312617