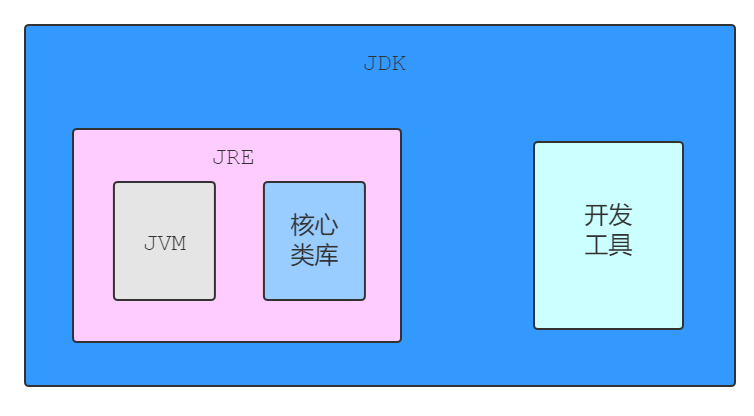
是Java程序运行时的环境,==包含JVM==和运行时所需要的核心类库。
我们想要运行一个已有的Java程序,那么只需要安装JRE即可。
是Java程序开发工具包,==包含JRE==和开发人员所需要使用的工具。
其中的开发工具:编译工具(==javac.exe==)和运行工具(==java.exe==)。
| 目录名称 | 说明 |
|---|---|
| bin | 该路径下存放了JDK的各种工具命令。==javac==和==java==就放在这个目录 |
| conf | 该路径下存放了JDK的相关配置文件 |
| include | 该路径下存放了一些平台特定的头文件 |
| jmods | 该路径下存放了JDK的各种模块 |
| legal | 该路径下存放了JDK各模块的授权文档 |
| lib | 该路径下存放了JDK工具的一些补充JAR包 |
其余文件为说明性文档。
关键字:就是被Java语言赋予了特定含义的单词。
常量:在程序运行过程中,其值不可以发生改变的量。
| 常量类型 | 说明 |
|---|---|
| 字符串常量 | 用双引号括起来的内容 |
| 整数常量 | 不带小数的数字 |
| 小数常量 | 带小数的数字 |
| 字符常量 | 用单引号括起来的内容 |
| 布尔常量 | 布尔值,表示真假 |
| 空常量 | 一个特殊的值,空值,==不能直接输出== |
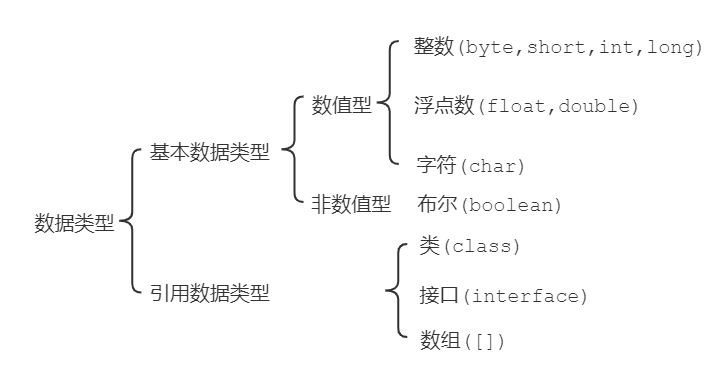
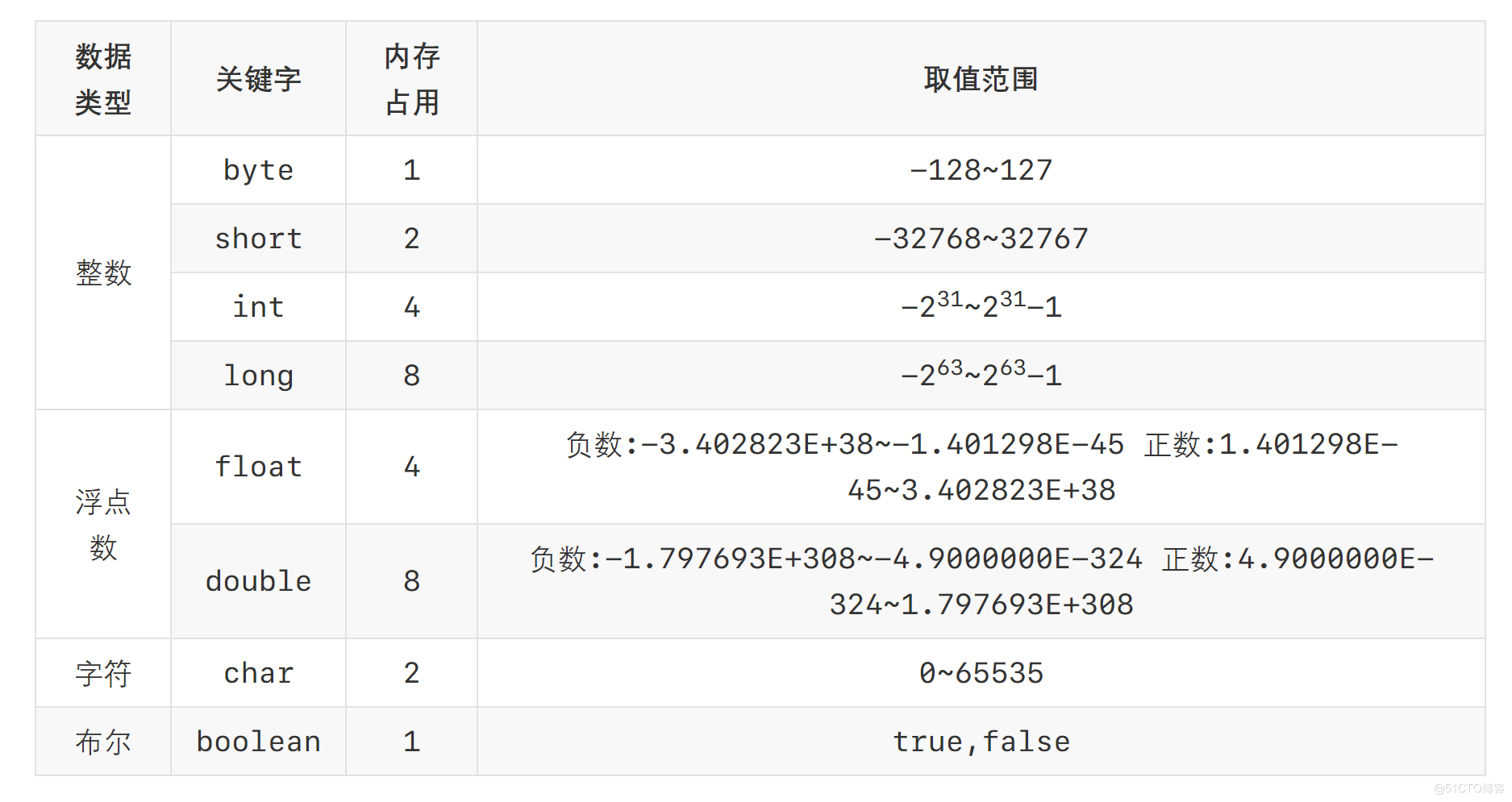
我们知道计算机是可以用来存储数据的,但是无论是内存还是硬盘,计算机存储设备的最小信息单元叫"位(bit)",我们又称之为"比特位",通常用小写的字母"b"表示。而计算机中最小的存储单元叫"字节(byte)",通常用大写字母"B"表示,字节是由连续的8个位组成。
Java语言是强类型语言,对于每一种数据都给出了明确的数据类型,不同的数据类型也分配了不同的==内存空间==,所以他们表示的==数据大小==也是不一样的。
 ![image-20200920142842809]
![image-20200920142842809]
变量:在程序运行过程中,其值可以发生改变的量。从本质上讲,变量是内存中一小块区域。
格式:数据类型 变量名 = 变量值;
取值和修改值
取值格式:变量名
定义long类型,为防止整数过大,变量值最后面加上L,例如: long a = 100000000L;
标识符:就是给类、方法、变量等起名字的符号。
小驼峰命名法:==方法、变量==
大驼峰命名法:==类==
约定1:标识符是一个单词的时候,首字母大写
把一个表示数据==范围小的数值==或者==变量==赋值给另一个表示数据==范围大的变量==
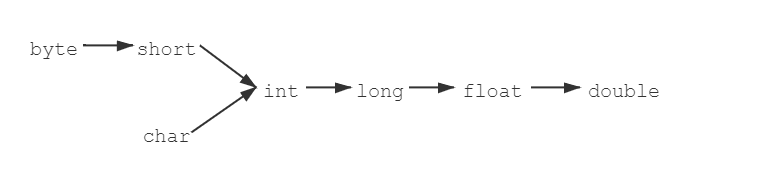
把一个表示==范围大的数值==或者==变量==赋值给另外一个表示数据==范围小的变量==
运算符:对常量或者变量进行操作的==符号==
表达式:用==运算符==把常量或者变量连接起来==符合java语法的式子==就可以成为表达式。
不同运算符连接起来的表达式体现的是不同类型的表达式。
算术表达式中包含多个基本数据类型的值的时候,整个算术表达式的类型会自动进行提升。
提升规则:
符号:=
作用:赋值
注意:扩展的赋值运算符==隐含==了强制类型转换
| 符号 | 作用 | 说明 |
|---|---|---|
| ++ | 自增 | 变量值加1 |
| -- | 自减 | 变量值减1 |
| 符号 | 说明 |
|---|---|
| == | a\==b,判断a和b的值是否==相等==,成立为true,不成立为false |
| != | a!=b,判断a和b的值是否==不相等==,成立为true,不成立为false |
| > | a>b,判断a是否==大于==b,成立为true,不成立为false |
| \>= | a>=b,判断a是否==大于等于==b,成立为true,不成立为false |
| < | a<b,判断a是否==小于==b,成立为true,不成立为false |
| <= | a<=b,判断a是否==小于等于==b,成立为true,不成立为false |
逻辑运算符,是用来==连接关系表达式==的运算符,当然逻辑运算符也可以直接==连接布尔类型的变量或常量==
| 符号 | 作用 | 说明 |
|---|---|---|
| & | 逻辑与 | a&b,a和b都是true,结果为true,否则为false |
| | | 逻辑或 | a|b,a和b都是false,结果为false,否则为true |
| ^ | 逻辑异或 | a^b,a和b不同为true,相同为false |
| ! | 逻辑非 | !a,结果和a的结果正好相反 |
| 符号 | 作用 | 说明 |
|---|---|---|
| && | 短路与 | 作用和&相同,但是有短路效果,左边为false,右边不执行 |
| || | 短路或 | 作用和|相同,但是有短路效果,左边为true,右边不执行 |
==注意事项:==
逻辑与&,无论左边真假,右边都要执行。
短路与&&,如果左边为真,右边执行,如果左边为假,右边不执行。
import java.util.Scanner;
// 导包的动作必须出现在类定义的上边Scanner sc = new Scanner(System.in);
// 上面这个格式里面,只有sc是变量名,可以变,其它的都不允许变int i = sc.next();
// 上面这个格式里面,只有i是变量名,可以变,其它的都不允许变顺序结构是程序中最简单最基本的流程控制,没有特定的语法结构,按照代码的先后顺序,依次执行,程序中大多数的代码都是这样执行的。
if (关系表达式) {
语句体;
}执行流程:
if (关系表达式) {
语句体1;
} else {
语句体2;
}执行流程:
if (关系表达式1) {
语句体1;
} else if (关系表达式2) {
语句体2;
}
...
else {
语句体n+1;
}执行流程:
switch (表达式) {
case 值1:
语句体1;
break;
case 值2:
语句体2;
break;
...
default:
语句体n+1;
[break;]
}格式说明:
重复做某件事情
循环结构的组成:
for (初始化语句; 条件判断语句; 条件控制语句) {
循环体语句;
}执行流程:
如果是false,循环结束
执行循环体语句
执行条件控制语句
// 基本格式
while (条件判断语句) {
循环体语句;
}// 完整格式
初始化语句;
while (条件判断语句) {
循环体语句;
条件控制语句;
}执行流程:
执行初始化语句
// 基本格式
do {
循环体语句;
} while (条件判断语句);// 完整格式
初始化语句;
do {
循环体语句;
条件控制语句;
} while (条件判断语句);执行流程:
执行初始化语句
==死循环格式:==
for (;;) { }
while (true) { }
do { } while (true);while的死循环格式是最常用的
命令提示符窗口中<kbd>Ctrl+C</kbd>可以结束死循环
语句结构:
顺序语句: 以分号结尾,表示一句话的结束
分支语句: 一对大括号表示if的整体结构,整体描述一个完整的if语句
? 一对大括号表示switch的整体结构,整体描述一个完整的switch语句
循环语句: 一对大括号表示for的整体结构,整体描述一个完整的for语句
? 一对大括号表示while的整体结构,整体描述一个完整的while语句
? do...while以分号结尾,整体描述一个完整的do...while语句
任何语句对外都可以看成一句话,一句代码
分支语句中包含分支语句称为分支嵌套
循环语句中包含循环语句称为循环嵌套
作用: 用于产生一个随机数
使用步骤:
import java.util.Random;
// 导包的动作必须出现在类定义的上边Random r = new Random();
// 上面这个格式里面,只有r是变量名,可以变,其它的都不允许变int number = r.nextInt(10); // 获取数据的范围: [0, 10) 包括0,不包括10
// 上面这个格式里面,number是变量名,可以变,10可以变,其它的都不允许变数组(array)是一种用于存储多个相同类型数据的存储模型。
格式一: 数组类型[] 变量名
范例: int[] arr
定义一个int类型的数组,数组名是arr
格式二: 数组类型 变量名[]
范例: int arr[]
定义一个int类型的变量,变量名是arr数组
Java中的数组必须先初始化才能使用。
所谓初始化:就是将数组中的数组元素分配内存空间,并为每个数组元素赋值。
动态初始化:初始化时只指定数组长度,由系统为数组分配初始值
Java程序在运行时,需要在内存中分配空间。为了提高运算效率,就对空间进行了不同区域的划分。因为每一片区域都有特定的处理数据方式和内存管理。
静态初始化:初始化时指定每个数组元素的初始值,由系统决定数组长度
原文:https://blog.51cto.com/u_15302000/3314380