转:https://blog.csdn.net/wx1528159409/article/details/84667658
从概念上理解
Hive是基于Hadoop的一个数据仓库工具;它是MapReduce的一个封装,底层就是MapReduce程序;
Hive可以将结构化的数据文件(eg:按照各字段分类的数据)映射成一张虚表,并提供类SQL查询功能;
有了Hive后我们就不用再写麻烦的MapReduce程序了。
从本质上来说;
Hive就是把sql语句转化为MapReduce程序。
Hive没有服务端,它本质是Hadoop或者说是HDFS的一个客户端,对HDFS的数据和Meta store的元数据进行操作;
通常我们启动Hive是通过JDBC客户端操作的;
ps:对比hadoop中,通过命令start-dfs.sh启动HDFS服务端,然后通过hadoop fs -命令来启动HDFS客户端进行实际操作;
服务端是提供后台服务的,客户端是进行具体操作然后让服务端提供对应服务的。
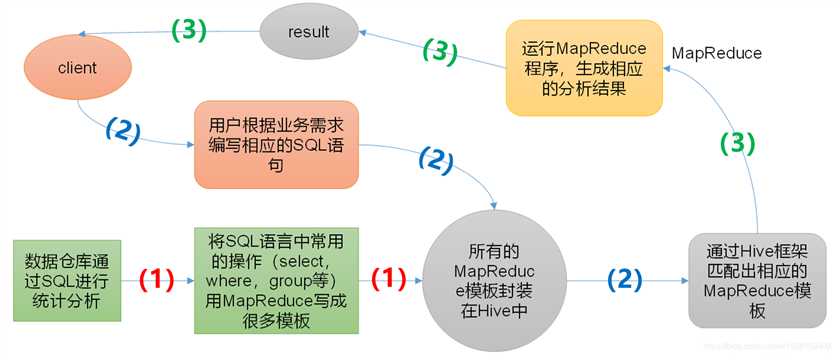
为什么说Hive是基于Hadoop的呢?
(1)Hive处理的数据实际存放在HDFS中,默认路径/user/hive/warehouse;
(2)Hive分析数据的底层实现还是MapReduce程序;
(3)Hive调度资源时,用的是Yarn框架;
(4)在服务器中运行Hive之前需要群起HDFS和YARN。
Hive的优缺点
1. 优点
(1)简单、只需要写SQL语句就行;
(2)Hive常用于数据分析,适合处理离线数据(静态数据);
(3)优势在于处理大数据;
(4)支持用户自定义函数;
ps:mysql适合处理数据的增删改查,适合处理实时数据(动态数据)
2. 缺点
(1)Hive的表达有限,无法表达迭代式算法((第一个MapReducer程序的结果作为另一个MapReducer程序的输入,这种就是迭代式算法));
(2)数据挖掘不擅长(擅长数据挖掘的是Spark);
(3)Hive自动生成MapReduce作业,通常不够智能化,效率比较低;
(4)Hive调优一般比较困难,粒度较粗。
原文:https://www.cnblogs.com/wex1022/p/15125556.html