在日常的数据分析中,经常需要将数据根据某个(多个)字段划分为不同的群体(group)进行分析,如电商领域将全国的总销售额根据省份进行划分,分析各省销售额的变化情况,社交领域将用户根据画像(性别、年龄)进行细分,研究用户的使用情况和偏好等。在Pandas中,上述的数据处理操作主要运用groupby完成,这篇文章就介绍一下groupby的基本原理及对应的agg、transform和apply操作。
为了后续图解的方便,采用模拟生成的10个样本数据,代码和数据如下:
company=["A","B","C"] ? data=pd.DataFrame({ "company":[company[x] for x in np.random.randint(0,len(company),10)], "salary":np.random.randint(5,50,10), "age":np.random.randint(15,50,10) })
在pandas中,实现分组操作的代码很简单,仅需一行代码,在这里,将上面的数据集按照company字段进行划分:
In [5]: group = data.groupby("company")
将上述代码输入ipython后,会得到一个DataFrameGroupBy对象
In [6]: group Out[6]: <pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002B7E2650240>
那这个生成的DataFrameGroupBy是啥呢?对data进行了groupby后发生了什么?ipython所返回的结果是其内存地址,并不利于直观地理解,为了看看group内部究竟是什么,这里把group转换成list的形式来看一看:
In [8]: list(group) Out[8]: [(‘A‘, company salary age 3 A 20 22 6 A 23 33), (‘B‘, company salary age 4 B 10 17 5 B 21 40 8 B 8 30), (‘C‘, company salary age 0 C 43 35 1 C 17 25 2 C 8 30 7 C 49 19)]
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),第二个元素的是对应组别下的DataFrame,整个过程可以图解如下:
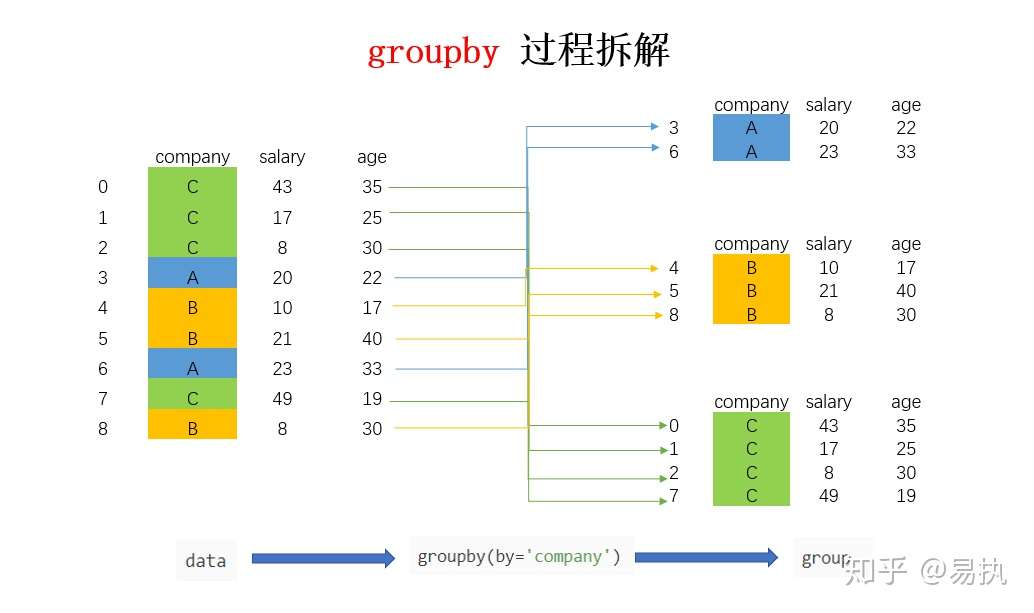
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。下面来讲讲groupby之后的常见操作。
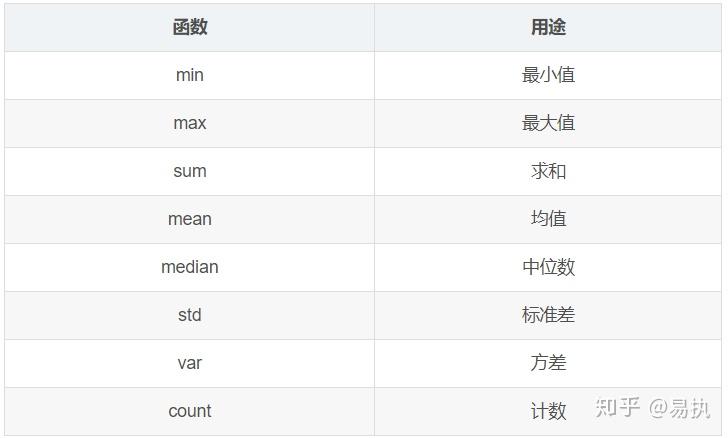
聚合操作是groupby后非常常见的操作,会写SQL的朋友对此应该是非常熟悉了。聚合操作可以用来求和、均值、最大值、最小值等,下面的表格列出了Pandas中常见的聚合操作。
针对样例数据集,如果我想求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
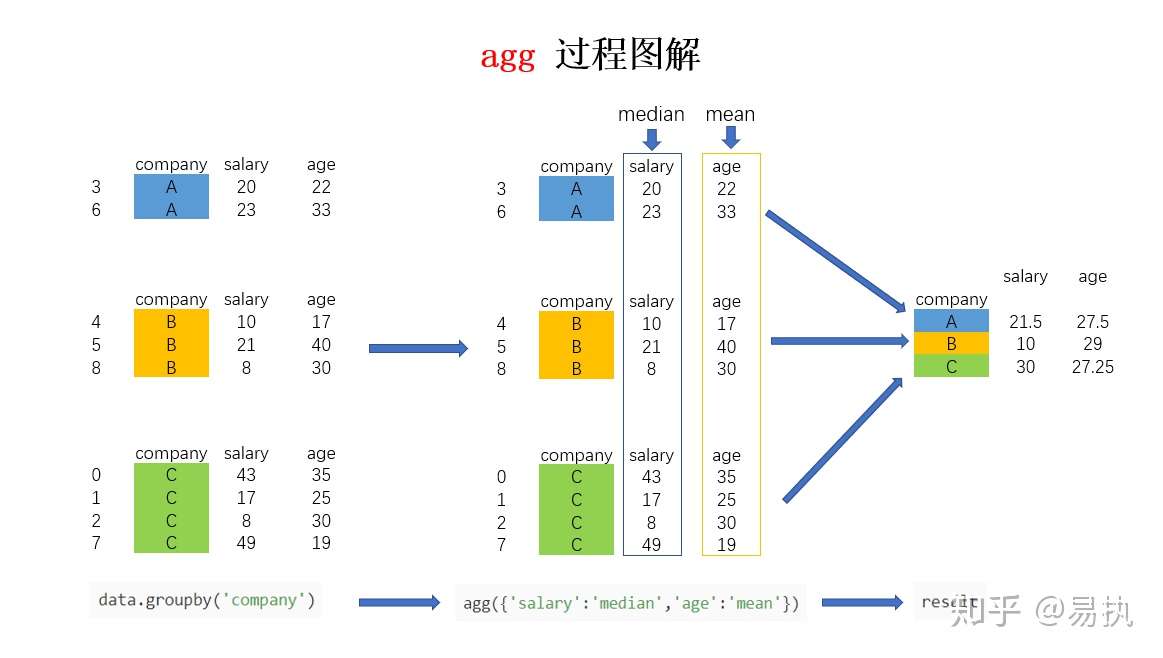
In [12]: data.groupby("company").agg(‘mean‘) Out[12]: salary age company A 21.50 27.50 B 13.00 29.00 C 29.25 27.25
如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定:
In [17]: data.groupby(‘company‘).agg({‘salary‘:‘median‘,‘age‘:‘mean‘}) Out[17]: salary age company A 21.5 27.50 B 10.0 29.00 C 30.0 27.25
agg聚合过程可以图解如下(第二个例子为例):
transform是一种什么数据操作?和agg有什么区别呢?为了更好地理解transform和agg的不同,下面从实际的应用场景出发进行对比。
在上面的agg中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用transform的话,实现代码如下:
In [21]: avg_salary_dict = data.groupby(‘company‘)[‘salary‘].mean().to_dict() ? In [22]: data[‘avg_salary‘] = data[‘company‘].map(avg_salary_dict) ? In [23]: data Out[23]: company salary age avg_salary 0 C 43 35 29.25 1 C 17 25 29.25 2 C 8 30 29.25 3 A 20 22 21.50 4 B 10 17 13.00 5 B 21 40 13.00 6 A 23 33 21.50 7 C 49 19 29.25 8 B 8 30 13.00
如果使用transform的话,仅需要一行代码:
In [24]: data[‘avg_salary‘] = data.groupby(‘company‘)[‘salary‘].transform(‘mean‘) ? In [25]: data Out[25]: company salary age avg_salary 0 C 43 35 29.25 1 C 17 25 29.25 2 C 8 30 29.25 3 A 20 22 21.50 4 B 10 17 13.00 5 B 21 40 13.00 6 A 23 33 21.50 7 C 49 19 29.25 8 B 8 30 13.00
还是以图解的方式来看看进行groupby后transform的实现过程(为了更直观展示,图中加入了company列,实际按照上面的代码只有salary列):

图中的大方框是transform和agg所不一样的地方,对agg而言,会计算得到A,B,C公司对应的均值并直接返回,但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果,如果有不理解的可以拿这张图和agg那张对比一下。
apply应该是大家的老朋友了,它相比agg和transform而言更加灵活,能够传入任意自定义的函数,实现复杂的数据操作。在Pandas数据处理三板斧——map、apply、applymap详解中,介绍了apply的使用,那在groupby后使用apply和之前所介绍的有什么区别呢?
区别是有的,但是整个实现原理是基本一致的。两者的区别在于,对于groupby后的apply,以分组后的子DataFrame作为参数传入指定函数的,基本操作单位是DataFrame,而之前介绍的apply的基本操作单位是Series。还是以一个案例来介绍groupby后的apply用法。
假设我现在需要获取各个公司年龄最大的员工的数据,该怎么实现呢?可以用以下代码实现:
In [38]: def get_oldest_staff(x): ...: df = x.sort_values(by = ‘age‘,ascending=True) ...: return df.iloc[-1,:] ...: ? In [39]: oldest_staff = data.groupby(‘company‘,as_index=False).apply(get_oldest_staff) ? In [40]: oldest_staff Out[40]: company salary age 0 A 23 33 1 B 21 40 2 C 43 35
这样便得到了每个公司年龄最大的员工的数据,整个流程图解如下:
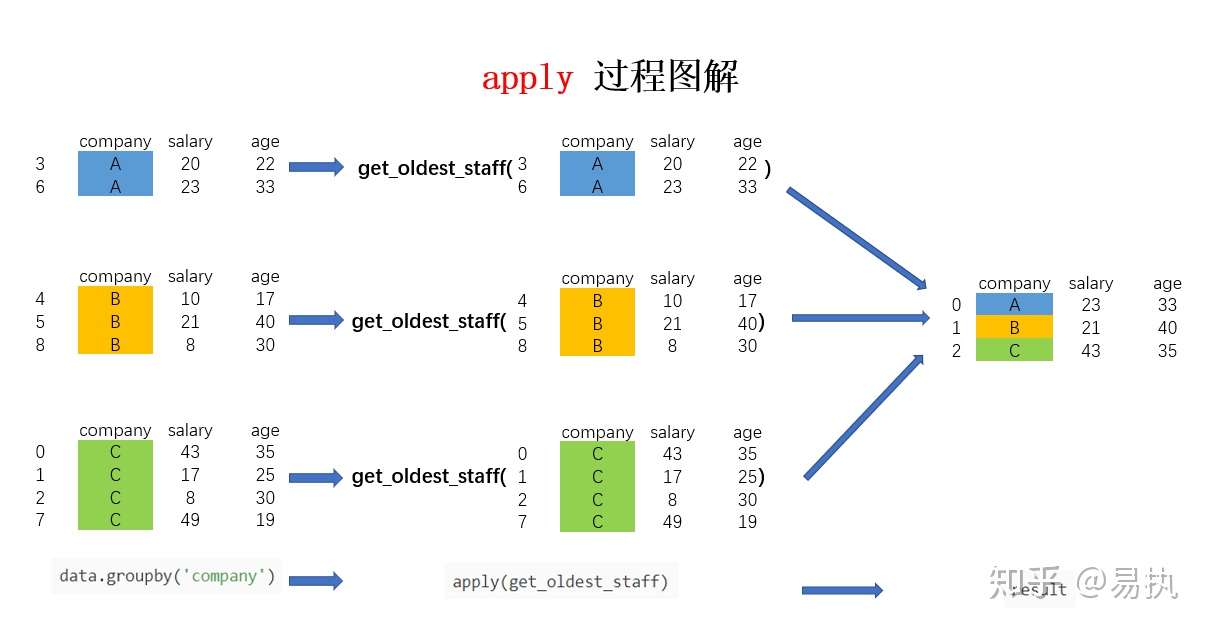
可以看到,此处的apply和上篇文章中所介绍的作用原理基本一致,只是传入函数的参数由Series变为了此处的分组DataFrame。
最后,关于apply的使用,这里有个小建议,虽然说apply拥有更大的灵活性,但apply的运行效率会比agg和transform更慢。所以,groupby之后能用agg和transform解决的问题还是优先使用这两个方法,实在解决不了了才考虑使用apply进行操作。
相关文章:
转自https://zhuanlan.zhihu.com/p/101284491?utm_source=wechat_session
原文:https://www.cnblogs.com/cangqinglang/p/15134463.html