计算机是基于电工作的 而电信号只有高低电平两种状态
也就是说计算机只认识两种状态 人为的定义为数字0和1即二进制
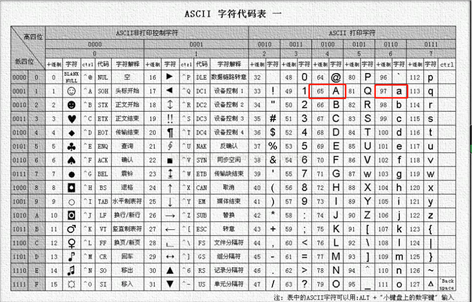
计算机是美国人发明的,想让计算机认识英文,所以发明了ASCII码,内部记录了英文与数字的对应关系。
随着时代的发展,各个国家发明了自己的编码表。如中国,就是GBK码表
为了计算机全球化的推进,解决各个国家之间编码不同,因此推出了unicode码,也就是万国码。
内部记录了各个国家文字与数字的对应关系,作为优化版本,现在一般使用的都是utf-8编码表。
按照指定的编码本将人类的字符编程成计算机能够识别的二进制数据
按照指定的编码本将计算机的二进制数据解析成人类能够读懂的字符
res = "随着全球变暖的影响,我们再也不能在过年放鞭炮了(滑稽)。"
res1 = res.encode(‘gbk‘) print(res1)
res2 = res1.decode(‘gbk‘) print(res2)
以后文本文件如果出现了乱码肯定是因为字符编码选错了,尝试着切换字符编码即可。
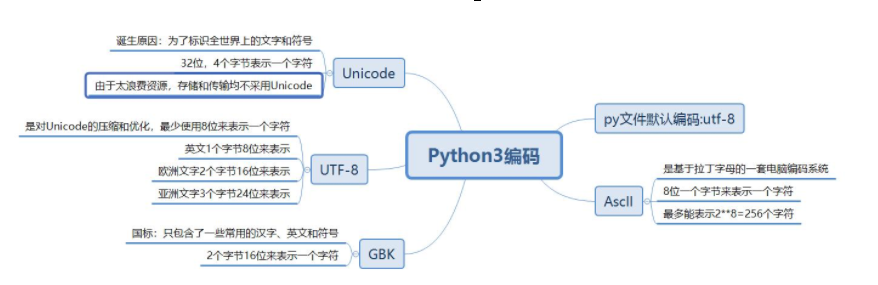
with open(文件路径,读写模式,字符编码) as 变量名:
子代码
变量名 = open(文件路径,读写模式,字符编码)
代码块
变量名.colse()
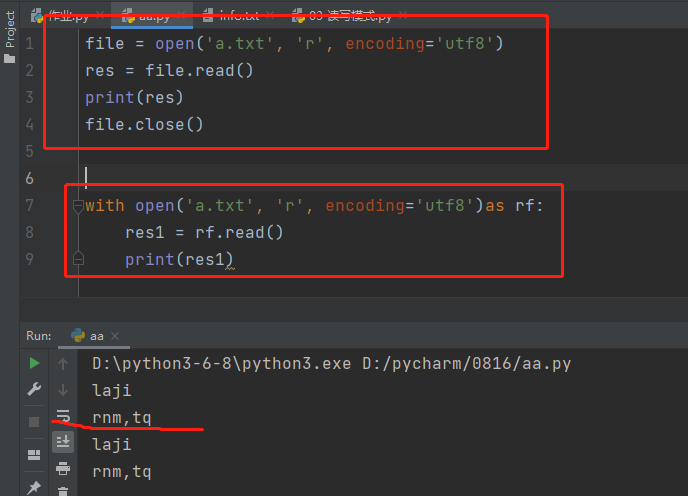
1.文件路径不存在会直接报错
2.文件存在则打开并可读取文件内容
光标在文件开头
with open(r‘aaa.txt‘, ‘r‘, encoding=‘utf8‘) as f: print(f.read()) # 一次性读取文件内容
1.文件路径不存在会自动创建
2.文件路径存在会先清空该文件内容然后再写入
with open(r‘aaa.txt‘, ‘w‘, encoding=‘utf8‘) as f: f.write(‘你好你好你好\n‘)
1.文件路径不存在会自动创建
2.文件路径存在光标会移动到文件末尾再继续写入文本
with open(r‘aaa.txt‘, ‘a‘, encoding=‘utf8‘) as f: f.write(‘你追我 如果你追到我 我就让你...‘)
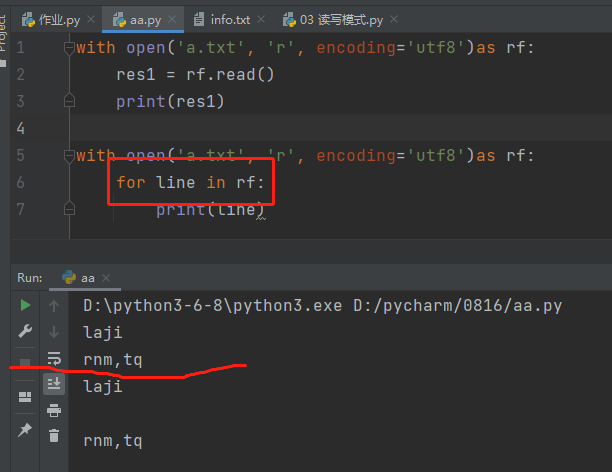
with open(r‘aaa.txt‘, ‘r‘, encoding=‘utf8‘) as f: for line in f: # 一行行读取文件内容 能够避免内存溢出 print(line)
也就是文本模式,是上面三种读写模式的默认模式,用 rt,wt,at,表示。
该模式只能操作文本文件
该模式下必须指定encoding参数
读写都是以字符串为单位
也叫做二进制模式,用rb,wb,ab,表示。
该模式可以操作任意类型的文件
该模式下不需要指定encoding参数
读写都是以bytes(二进制)为单位
原文:https://www.cnblogs.com/wddwyw-jyb/p/15147841.html