极大似然估计和朴素贝叶斯都是运用概率的思想对参数进行估计去解决问题的,二者具有一定的相似性,在初学时经常会搞不清二者的,在这里首先对二者的分类原理进行介绍,然后比较一下二者的异同点。
事件A和事件B,事件A发生的概率记为P(A),事件B发生的概率记为P(B),事件A发生的情况下B发生的概率记为:P(B|A),事件B发生的情况下A发生的概率记为P(A|B),那么:
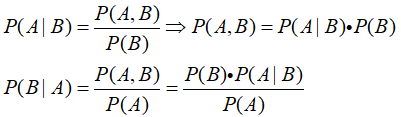
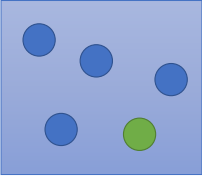
如下图,有两个箱子装有小球,第一个箱子有4颗蓝球和1颗绿球,第二个箱子有2颗蓝球和3颗绿球,已知选第一个箱子的概率是?,选第二个箱子的概率是?,随机从两个箱子取出一颗球,若取出的是一颗蓝球,问它从第一个箱子取出的概率是多大?
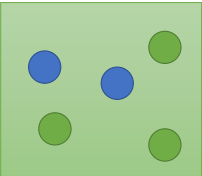
根据上述问题,假设两个箱子记为B1,B2,蓝球记为b,绿球记为g,那么p(B1)=?,P(B2)=?,从B1中取出一颗蓝球的概率P(b|B1)=0.8,取出一个绿球的概率为P(g|B1)=0.2,同理从B2中取出一颗蓝球的概率P(b|B2)=0.4,取出一个绿球的概率为P(g|B2)=0.6。那么问题及时求P(B1|b),根据贝叶斯公式:
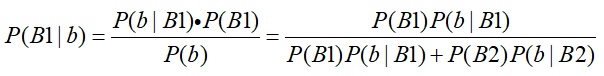 代入上式概率值,即可求得P(B1|b)。
代入上式概率值,即可求得P(B1|b)。
当把上述问题转化为二分类问题,对于训练样本,样本特征用X表示,样本类别分别为Class1和Class2,那么给定一个样本x,x属于Class1的概率表示为P(C1|x),它可以表示为:
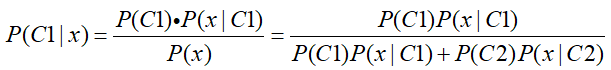
因此需要通过训练样本分别求解出P(C1)、P(C2)、P(x|C1)、P(x|C2)。
在监督学习中P(C1)、P(C2)可以通过样本标签计算得到,而对于P(x|C1)和P(x|C2)可以理解为分别从Class1和Class2中产生一个x的概率,也就是说知道了Class1和Class2的样本的分布,就可以根据概率密度函数求得P(x|C1)和P(x|C2)。
那么我们假设Class1和Class2都服从高斯分布(其他任何分布都可以),高斯分布的概率密度函数可以表示为:
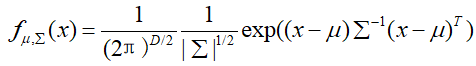
假设Class1的参数为μ1、Σ1,Class2的样本分布参数为μ2、Σ2。那么对于样本的分类,分类的正确率越高越好,即每个样本属于对应类别的概率越大越好,因此:
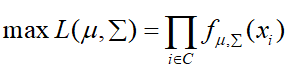
那么通过求解使得L最大的参数值,即为最优解,即:
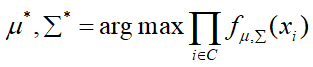
通过求解上式(求偏导,令其等于0),可以求得:
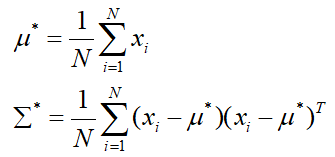
上述即为极大似然估计的过程,根据估计得到的参数,即可计算P(x|C1)、P(x|C2),即:
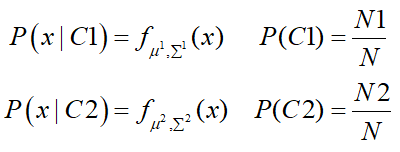
代回原式即可求得P(C1|x),此为利用极大似然估计进行分类的算法过程,而在实际应用中,考虑到计算速度和算法的准确性,往往将两个类别的样本分类共用一个方差Σ,那么原似然函数变为:
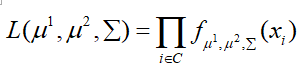
同样最终求得:
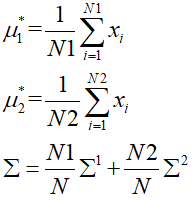
至此,极大似然估计的内容已基本完毕,极大似然估计与Logistic Regression和linear Model存在一定的关系,在后面回顾到这一部分会进一步说明。
朴素贝叶斯是基于各个条件相互独立的假设,当上述x存在多个特征时,用X表示特征集合,当每个特征相互独立时,则就变成了朴素贝叶斯:
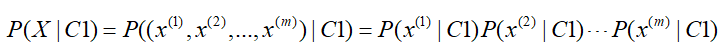
而在朴素贝叶斯中,贝叶斯派认为参数并非固定不变的,参数也是随机变量的观点,根据给定的样本数据使用极大似然估计估计先验概率和条件概率,即:
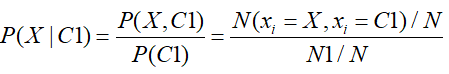
若变量是离散变量,则根据高斯分布(或其他分布)直接估计样本参数,即
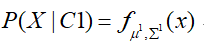
那么对于预测样本x‘,分别计算其属于每一类的概率,取概率最大者,即:
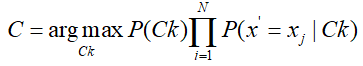
其中C即为x‘所属类别。上述即为朴素贝叶斯的分类算法过程。
原文:https://www.cnblogs.com/501731wyb/p/15149456.html