相同点:都可以存储多个元素,对外作为一个整体
不同点:
数组的容量固定无法动态改变;集合的容量可以动态改变(扩容)
数组可以存放基本数据类型和引用数据类型;集合只能存引用数据类型(涉及到自动装箱)
数组无法判断实际有多少元素,length只是告诉了数组的容量;集合可以判断实际存有多少元素,而对总容量不关心
数组采用顺序表的结构;集合有多种数据结构(顺序表,链表,哈希表,树等),多种特征(是否有序,是否唯一),不同的适用场合(查询快,便于删除,有序)
集合以类的形式存在,具有封装,继承,多态等类的特性,通过简单的方法和属性的调用即可实现各种复杂操作,提高了开发效率
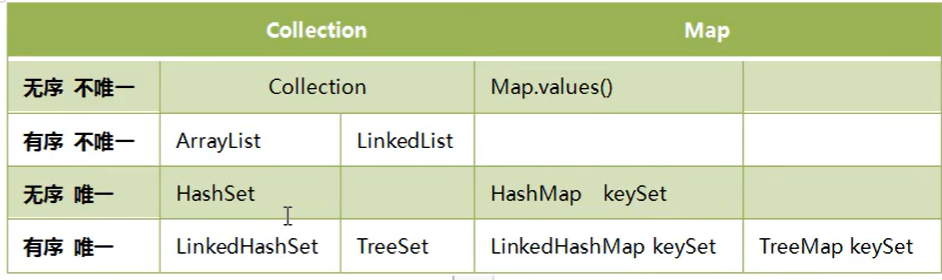
联系:都实现了List接口;有序,不唯一
ArrayList:
? 特点:在内存中分配了连续的空间,实现了长度可变的数组
? 优点:遍历元素,随机访问元素效率高
? 缺点:添加删除需大量移动元素效率低,按照内容查找效率低
LinkedList:
? 特点:采用链表存储方式,底层是双向链表
? 优点:遍历元素,随机访问元素效率低
? 缺点:添加删除效率高,修改指针即可
哈希表的特征:添加快,查询快(三步)
哈希表的结构:
JDK1.7:数组+链表
JDK1.8:数组+链表/红黑树(链表长度大于等于8)

哈希表的添加原理
哈希表的查询原理
同哈希表的添加原理
其他
1.hashCode()和equals()的作用:
hashCode():计算哈希码,是一个整数,根据哈希码可以计算出数据在哈希表中的存储位置
equals():往哈希表添加数据时,出现了冲突,要通过equals()进行比较,判断是否相同;查询时也要通过equals()进行比较,判断是否相同
2.如何减少冲突:
(1)表中记录数和哈希表的长度比例--装填因子
? - 如果哈希表的空间远大于实际存储的记录数,会造成空间的浪费,如果选小了,容易造成冲突。
? - 在实际情况中要根据最终存储的个数和关键字的分布特点来确定哈希表的大小。
? - 事先不知道存储个数时,需动态维护哈希表的容量,此时可能需要重新计算Hash地址
装填因子=表中记录数/哈希表的长度
(2)装填因子越小,表明表中还有很多空单元,发生冲突的可能性小。
? 装填因子越大,发生冲突的可能性越大,查找时耗费的时间越多。
? 相关资料证明,装填因子在0.5左右时,Hash性能能达到最优。
? 所以装填因子一般取0.5
(3)哈希函数的选择
? 直接定址法 平方取中法 折叠法 除留取余法(y=x%11)
(4)处理冲突的方法
? 链地址法 开放地址法 再散列法 建立一个公共溢出区
3.如何产生不同数据类型的哈希码
int 取自身。可看Integer源码
public int hashCode() {
return Integer.hashCode(value);
}
public static int hashCode(int value) {
return value;
}
double 3.24 ,4.67 取整不可以。可看Double源码
public int hashCode() {
return Double.hashCode(value);
}
public static int hashCode(double value) {
long bits = doubleToLongBits(value);//转为long型
return (int)(bits ^ (bits >>> 32));
}
String 将各个字符的码值相加不可以。可看String 源码
abc:31 X (31 X(31 X 0+97)+98)+99
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
Student 先计算各个属性的哈希码,再进行某些相加相乘的运算
String name; int age;
基本特征:
? 二叉树,二叉查找树,二叉平衡树,红黑树
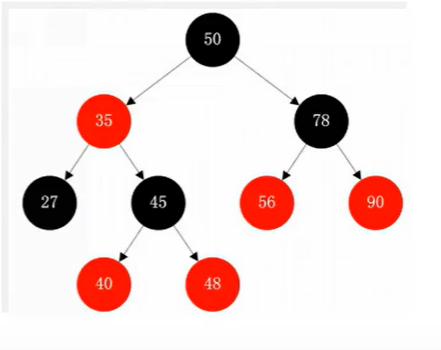
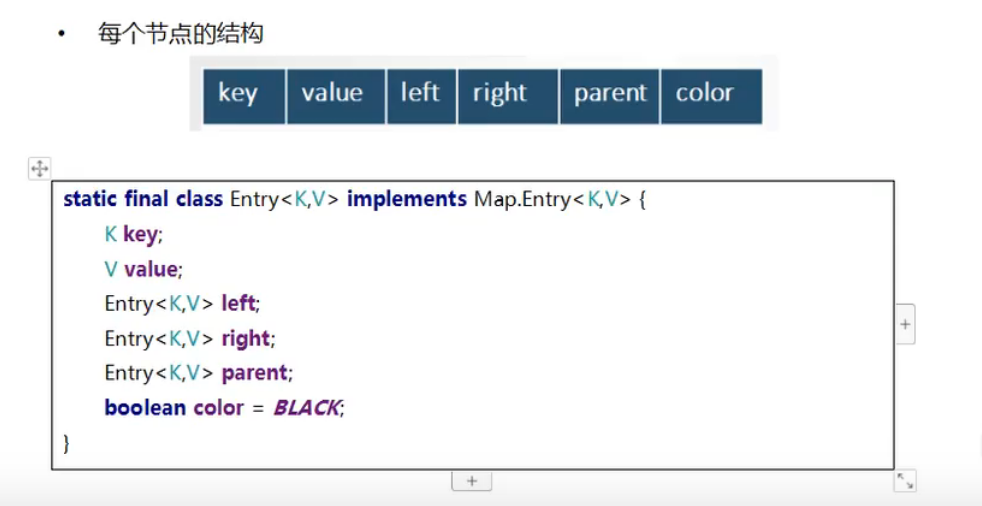
每个节点的结构
添加原理:
查询原理基本同添加
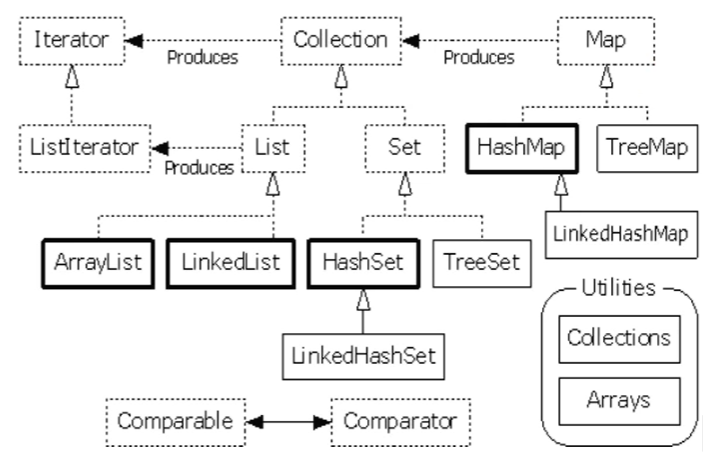
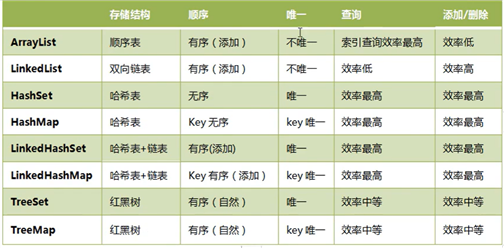
原文:https://www.cnblogs.com/zhangyaru/p/15151819.html