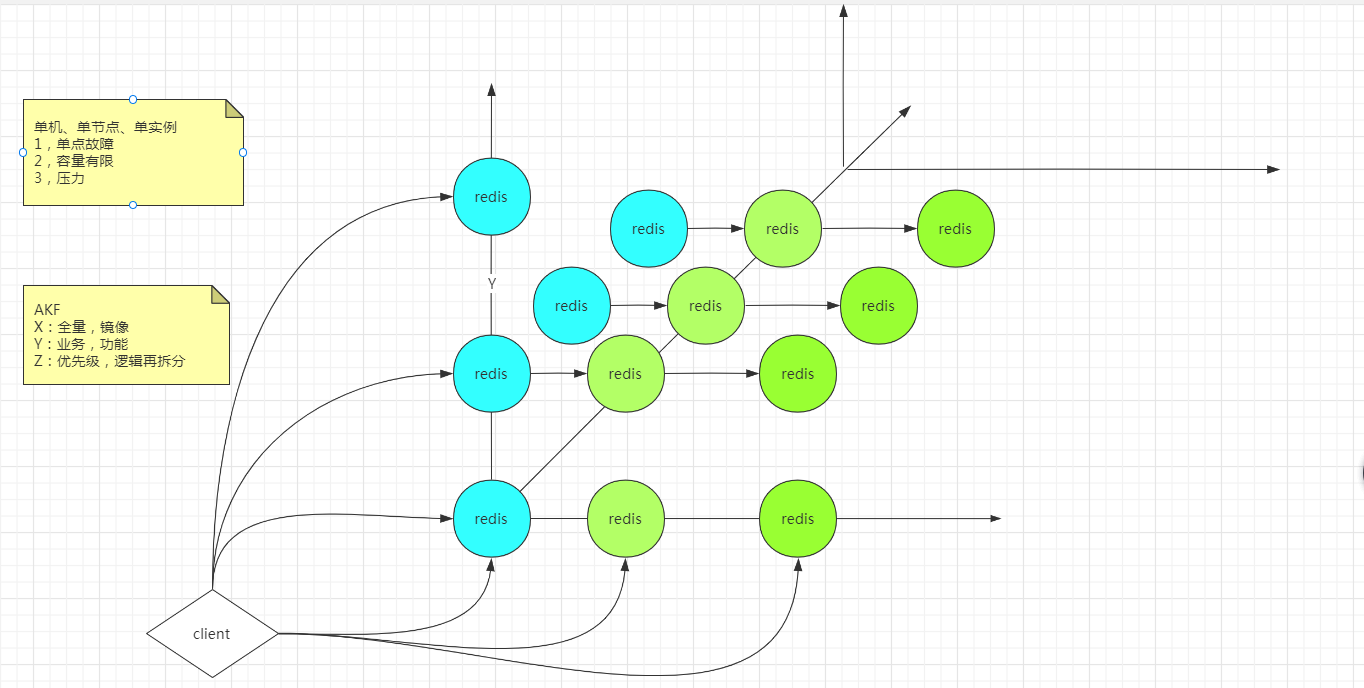
AKF 立方体也叫做scala cube,它在《The Art of Scalability》一书中被首次提出,旨在提供一个系统化的扩展思路。AKF 把系统扩展分为以下三个维度:
- X 轴:直接水平复制应用进程来扩展系统。 Redis示例的副本 解决单点故障的问题
- Y 轴:将功能拆分出来扩展系统。 对要存的数据按照不同的功能业务拆分 解决容量有限的问题
- Z 轴:基于用户信息扩展系统。 基于一定的规则,将一个业务将数据再拆分,存储到不同的库里
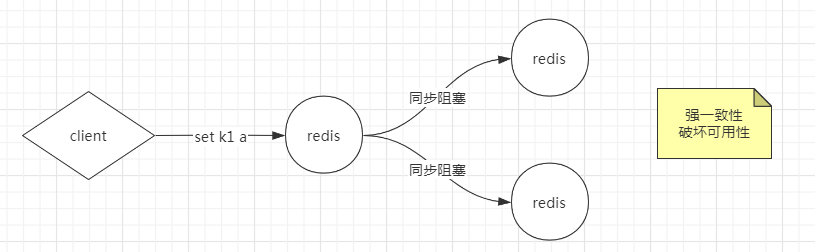
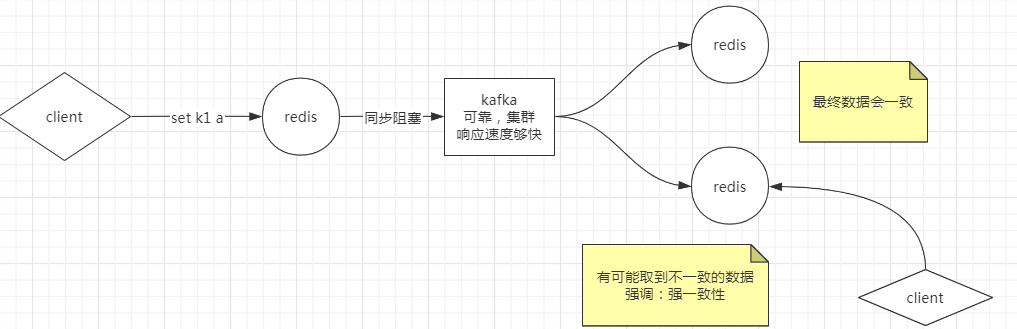
通过AKF实现一边多,产生数据一致性的问题
方案1: 所有节点阻塞,直到数据全部一致 - 强一致性,成本极高,并且难以达到。如果有一个节点因为网络问题挂了,整体就写失败了,对外表现出的是整个服务不可用。强一致性会破坏可用性。而我们将单redis拆分成多redis,本来就是要解决可用性的问题。
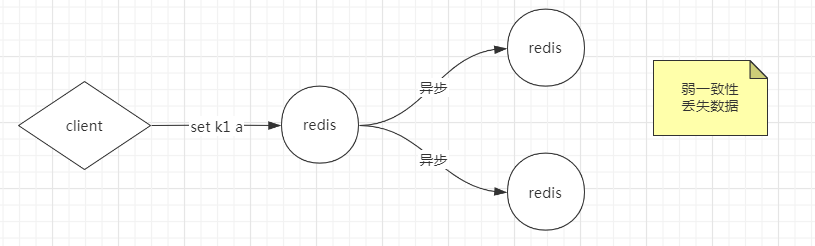
方案2: 容忍数据丢失一部分,主redis直接返回ok,通过异步方式让两个从库同步。存在的问题是,如果两个从库都写失败,别人在查询的时候,会发现丢失了这个数据。
方案3:使用足够可靠的kafka,达到数据的最终一致性。如果客户端要取数据的话,有多种可能:在达到最终一致性之前,可能会取到不一致的数据
主备:客户端不参与业务,只作备用机
主从:主从复制,可以在从库取数据
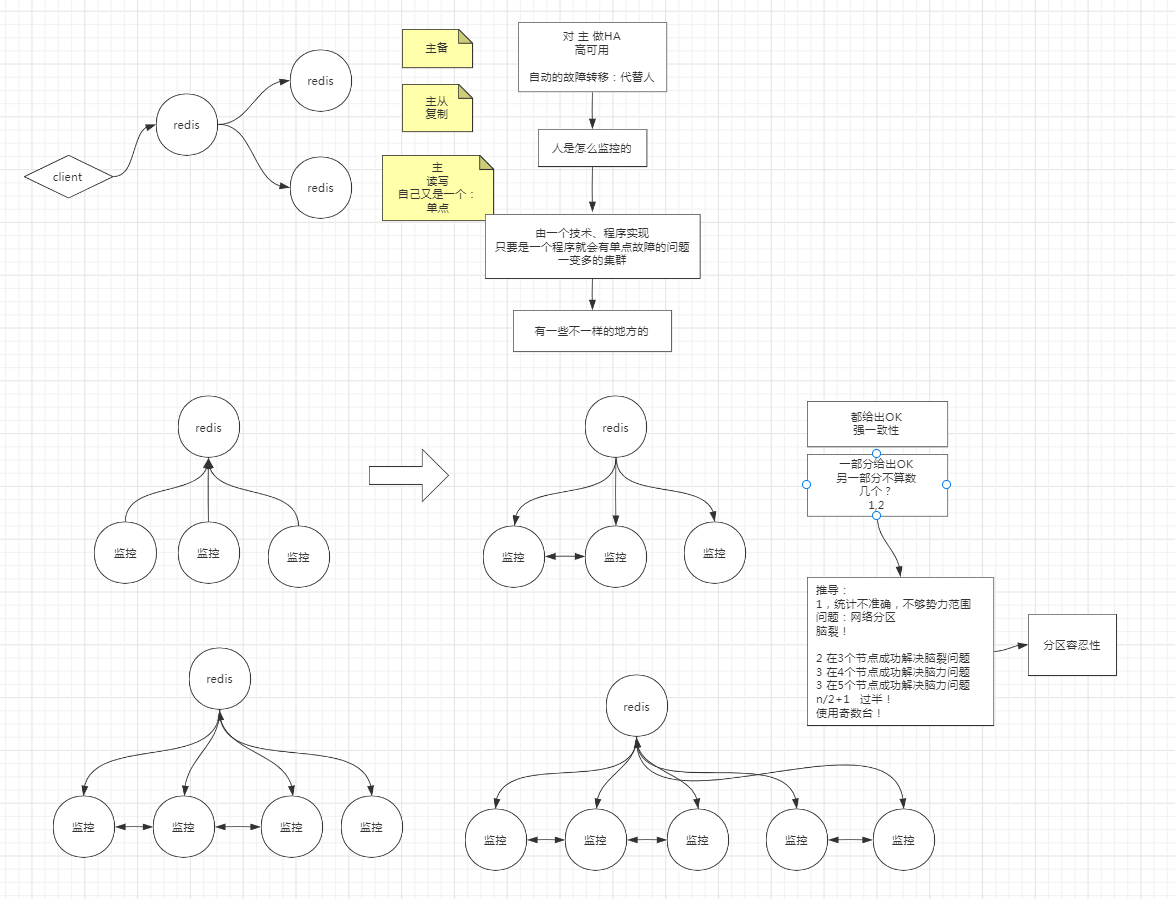
不论是哪一种,都只有一个主的概念,主自己就是一个单点,如果主挂了,立刻就是单点故障。
因此我们一般对主做HA(高可用),如果主挂了,刻会有一个节点来顶替它。对外的表现是从来没有出现过问题。
用多个节点去监控一个 redis 进程,是否会存在什么问题
假设三个监控程序,去监控一个 redis 进程,它们要怎样才能确定,这个 redis 进程状态?
为什么是过半
少数节点的监控结果情况就有可能统计不准确
因为不过半的话,就会有可能不同势力范围的结点,给出不同的结论,会产生一个问题:网络分区(脑裂)
由于网络分区,产生了至少两个以上集合,不包含主节点的集合、会出现检测不到主节点的情况,从而产生新的主节点。这样,整个集群就有了两个以上的主节点,从而产生不一致。
Zookeeper脑裂问题选用的为:选举法(过半概念),ZAB(zookeeper atomic broadcast)
分区容忍性
有时候我们可能不需要全量数据的一致,比如一共有50台订单管理微服务注册到注册中心(Eruka),注册中心是一个集群,注册中心有的注册到了50台,有的时候注册到了40台,这时候不管注册了多少台,只要订单管理能用就行,不一致这个问题会被我们包容。这就是分区容忍性。
CAP原则
CAP原则又称CAP定理,指的是在一个分布式系统中,[一致性](Consistency)、[可用性](Availability)、[分区容错性](Partition tolerance)。CAP 原则指的是,这三个[要素]最多只能同时实现两点,不可能三者兼顾。
HBase的网络一致性和分区容错度
ZooKeeper保证的是CP
https://baike.baidu.com/item/CAP原则/5712863?fr=aladdin
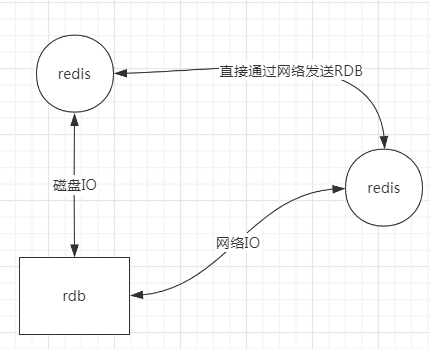
Redis使用默认的异步复制,其特点是低延迟和高性能,没有使用强一致性。
REPLICAOF 127.0.0.1 6379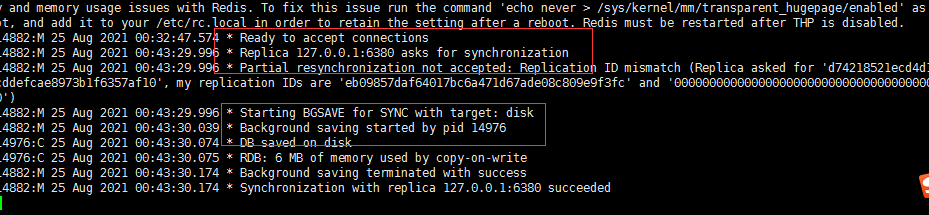
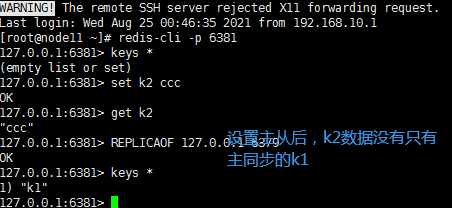
127.0.0.1:6380> set k2 aaa
(error) READONLY You can‘t write against a read only replica.
#从不能写数据,可以设置模式
从挂掉后,进程重启怎么处理数据
执行命令redis-server ./6381.conf --replicaof 127.0.0.1 6379重启
从主中同步数据到6381
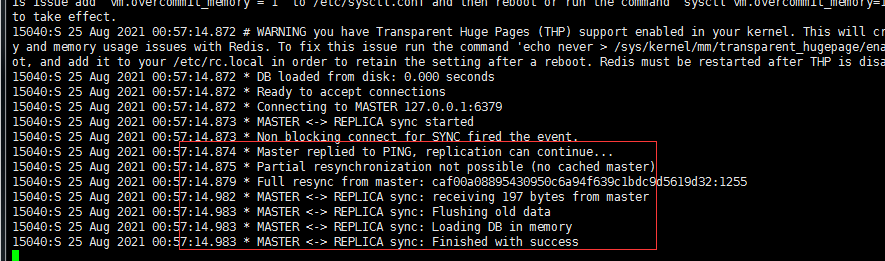
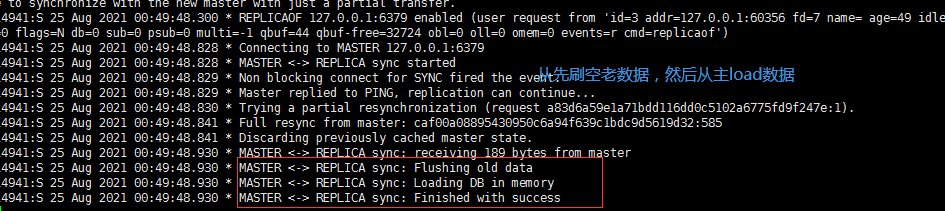
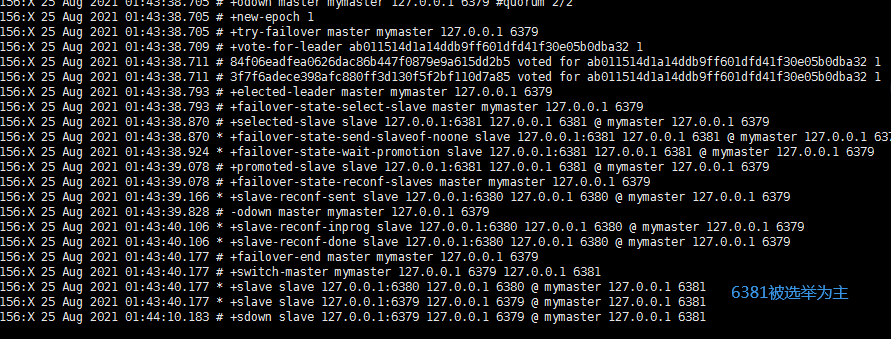
主挂掉后,从设置为主
执行命令REPLICAOF no one 设置6380为主,6381追随6380
127.0.0.1:6380> REPLICAOF no one
OK
127.0.0.1:6381> REPLICAOF 127.0.0.1 6380
OK
15069:M 25 Aug 2021 01:13:55.044 * Discarding previously cached master state.
15069:M 25 Aug 2021 01:13:55.044 * MASTER MODE enabled (user request from ‘id=4 addr=127.0.0.1:60896 fd=7 name= age=71 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=36 qbuf-free=32732 obl=0 oll=0 omem=0 events=r cmd=replicaof‘)
主从配置文件

两种不同的主从同步的方式
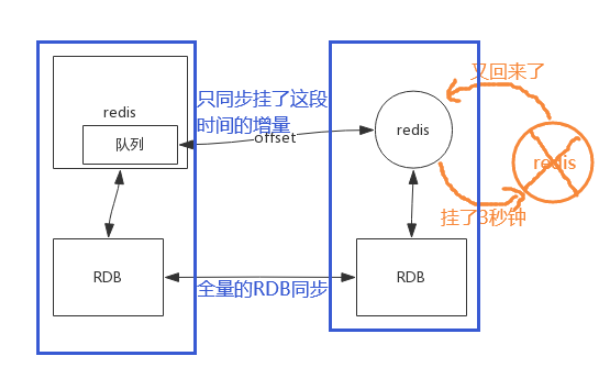
配置文件中的repl-backlog-size 1mb 是增量复制的设置
如果这个队列设置的太小了,假设 从redis 就挂了3秒钟,结果 主redis 1秒钟就把队列写满了,数据会挤出,这时候就要触发全量的RDB了。所以要根据业务,调整合适的队列大小。
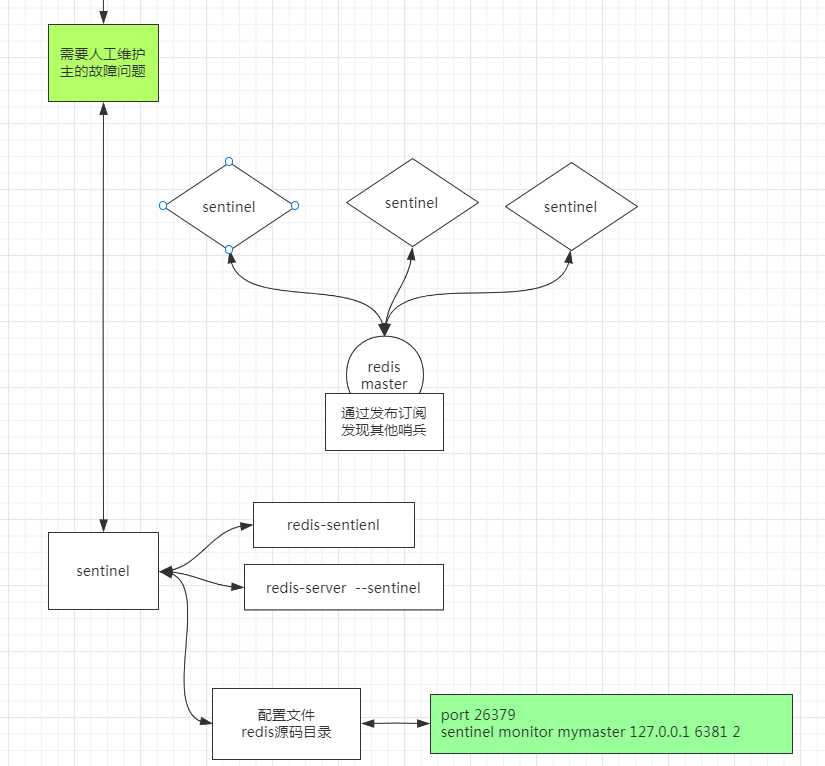
主从复制需要人工维护单点故障的问题,因此我们引入哨兵机制
http://redis.cn/topics/sentinel.html

命令
sentinel monitor mymaster 127.0.0.1 6379 2
启动哨兵进程
redis-server ./26379.conf --sentinel
原文:https://www.cnblogs.com/zhoum/p/15187626.html