?
hashmap是java里面的一种集合,是用来存放多个key-value形式的对象。
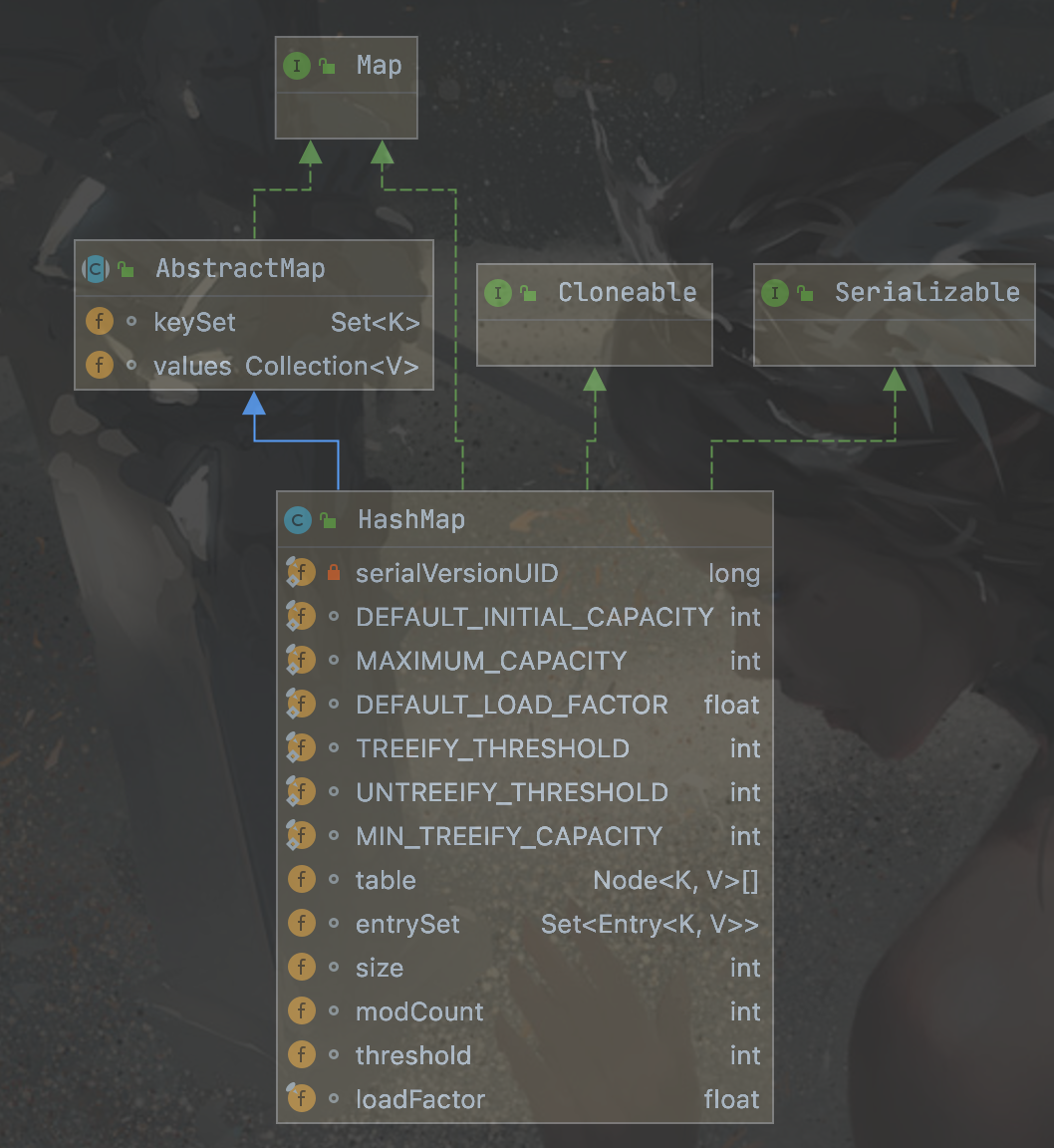
继承图:
 ?
?
其中具有的成员变量为:
DEFAULT_INITIAL_CAPACITY = 1 << 4 默认容量值
MAXIMUM_CAPACITY = 1 << 30 最大容量值,限制数组的最大容量
DEFAULT_LOAD_FACTOR = 0.75f 默认的负载因子值,用来衡量扩容边界
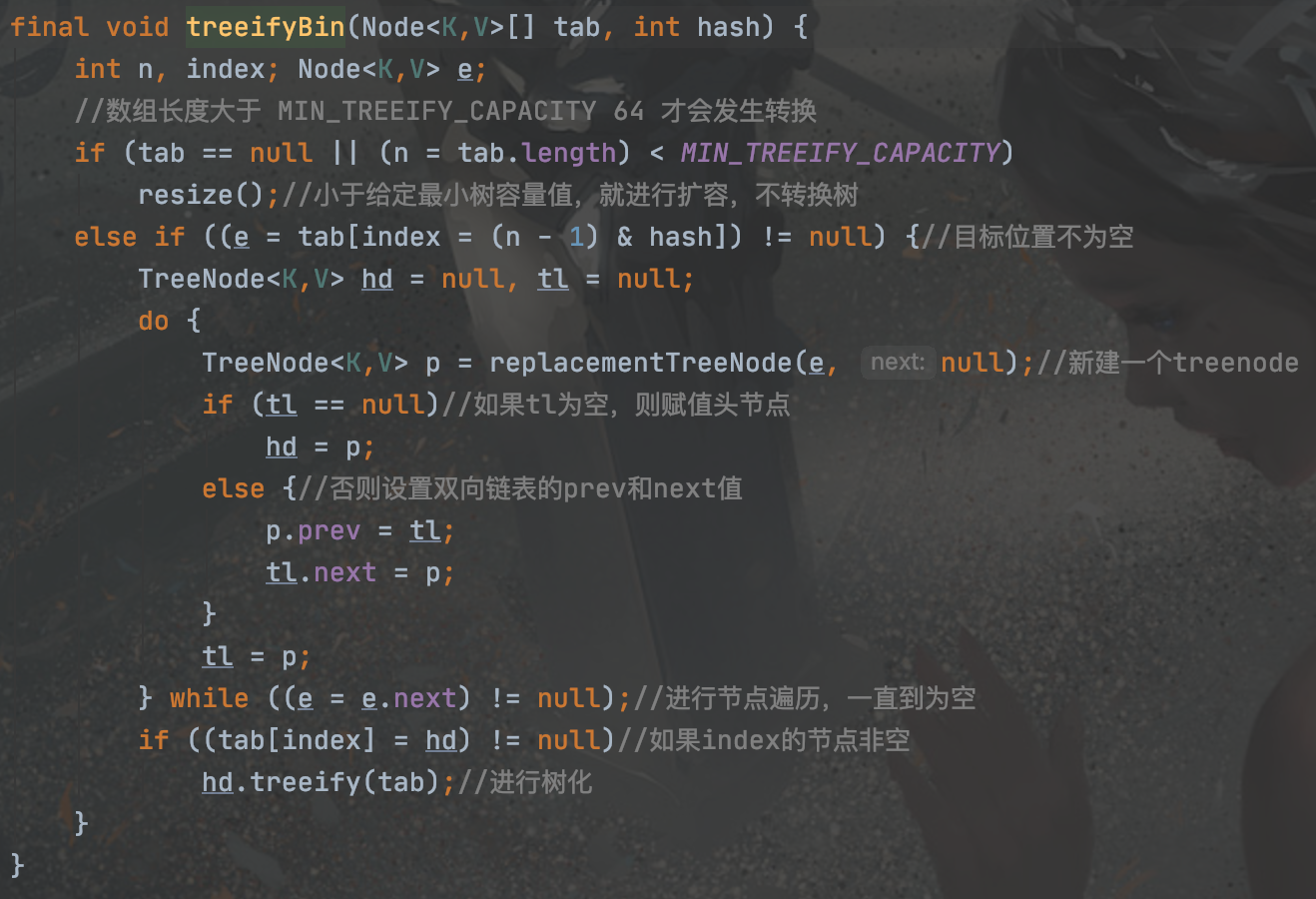
TREEIFY_THRESHOLD = 8 默认的链表长度转化为树的高度边界值
UNTREEIFY_THRESHOLD = 6 默认的树转化为链表的高度边界值
MIN_TREEIFY_CAPACITY = 64 默认的转化为树的数组最小容量值,达到该容量,且满足链表长度,才会进行树的转化
Node<K,V>[] table 数组对象
Set<Map.Entry<K,V>> entrySet 保存所有key和value的set集合
size 键值对的个数
modCount map的结构修改次数,设计到table节点的增删 ,才会进行累加,链表的之内的更改不计入
threshold 扩容边界值,达到该值后才进行扩容
loadFactor 负载因子
静态内部类:
Node<K,V>
HashMapSpliterator<K,V>
KeySpliterator<K,V>
ValueSpliterator<K,V>
EntrySpliterator<K,V>
TreeNode<K,V>
final 内部类:
KeySet
Values
EntrySet
KeyIterator
ValueIterator
EntryIterator
抽象内部类:
HashIterator
数据结构:
数组+链表+红黑树
table成员变量为 Node[] 数组,如果hash碰撞相同,但是key不一样,则放置在数组的同一位置,形成链表。如果链表不断变长,满足限定条件后,将会变成红黑树,红黑树的节点是双端链表
构造函数:
可以指定初始化容量,负载因子,或者传入另一个Map
主要的几个方法:
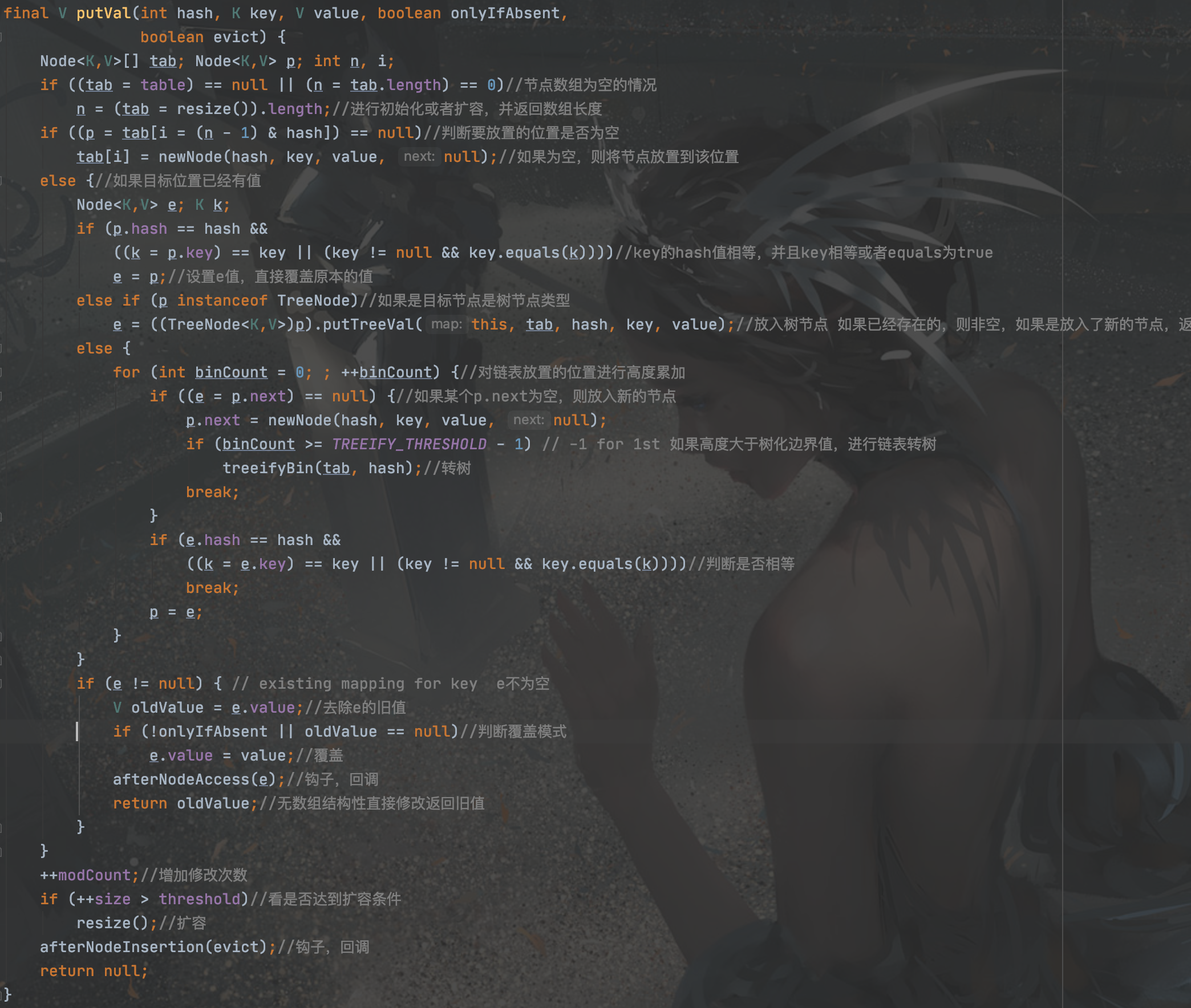
put:
调用putVal方法:
分三种情况:1)数组为空 2)数组非空,目标节点为空 3)目标节点有值
1)进行初始化
2)直接在目标位置置值
3)判断链表,是否为空,加入新值后是否满足树的转化,或者目标节点本就是树节点。
 ?
?
 ?
?
进行树化及自平衡,自平衡会判断三级节点,进行红黑的设定,左旋右旋的操作。
tab[index = (n - 1) & hash] 进行的是位与操作,获得的下标值不可能大于n-1,不会产生数组越界的情况
remove方法:
移除的时候,判断是否有值,判断是否是树节点,然后进行移除,如果是树的情况,将会判断是否达到转化成链表的边界值。
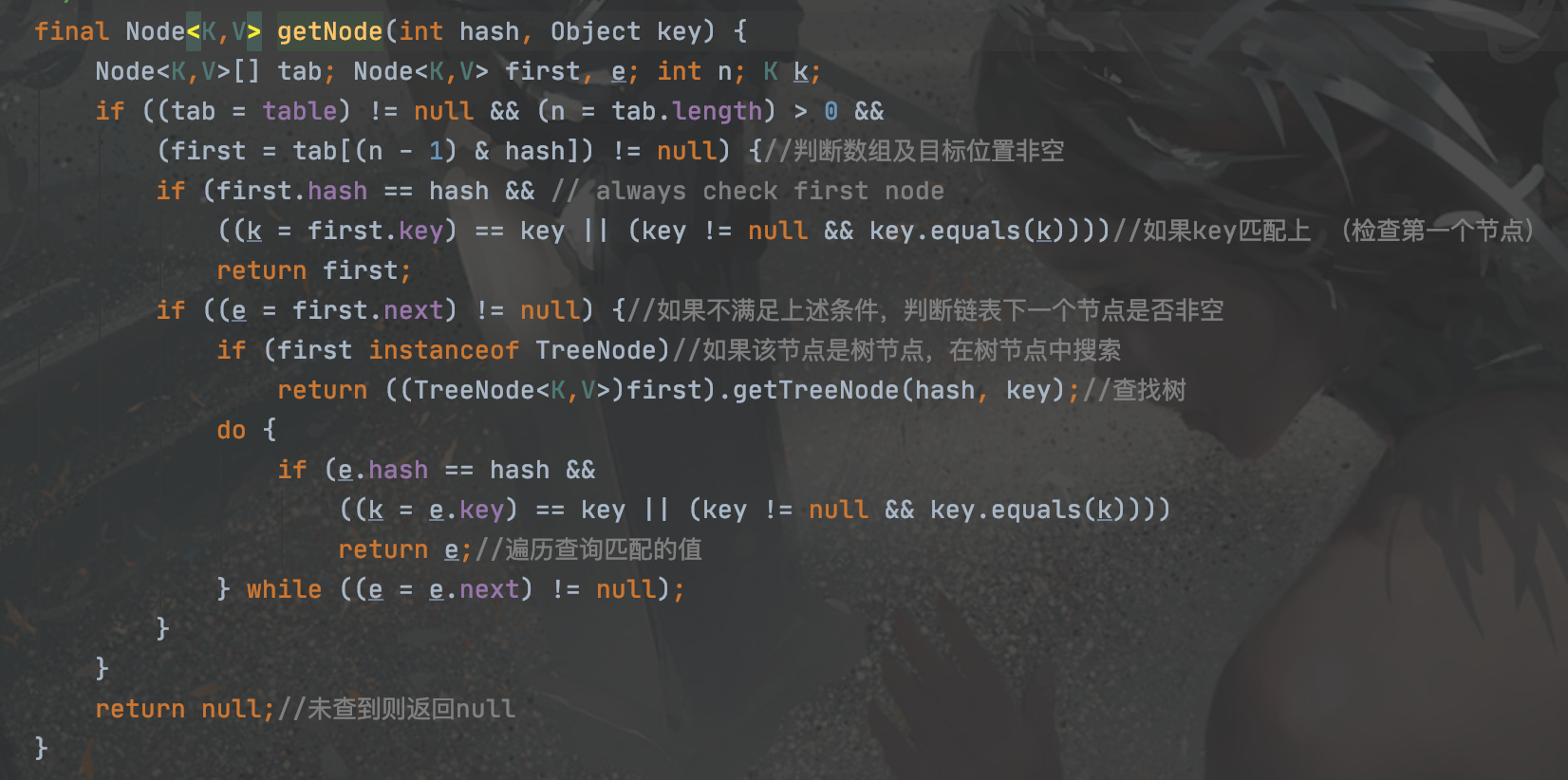
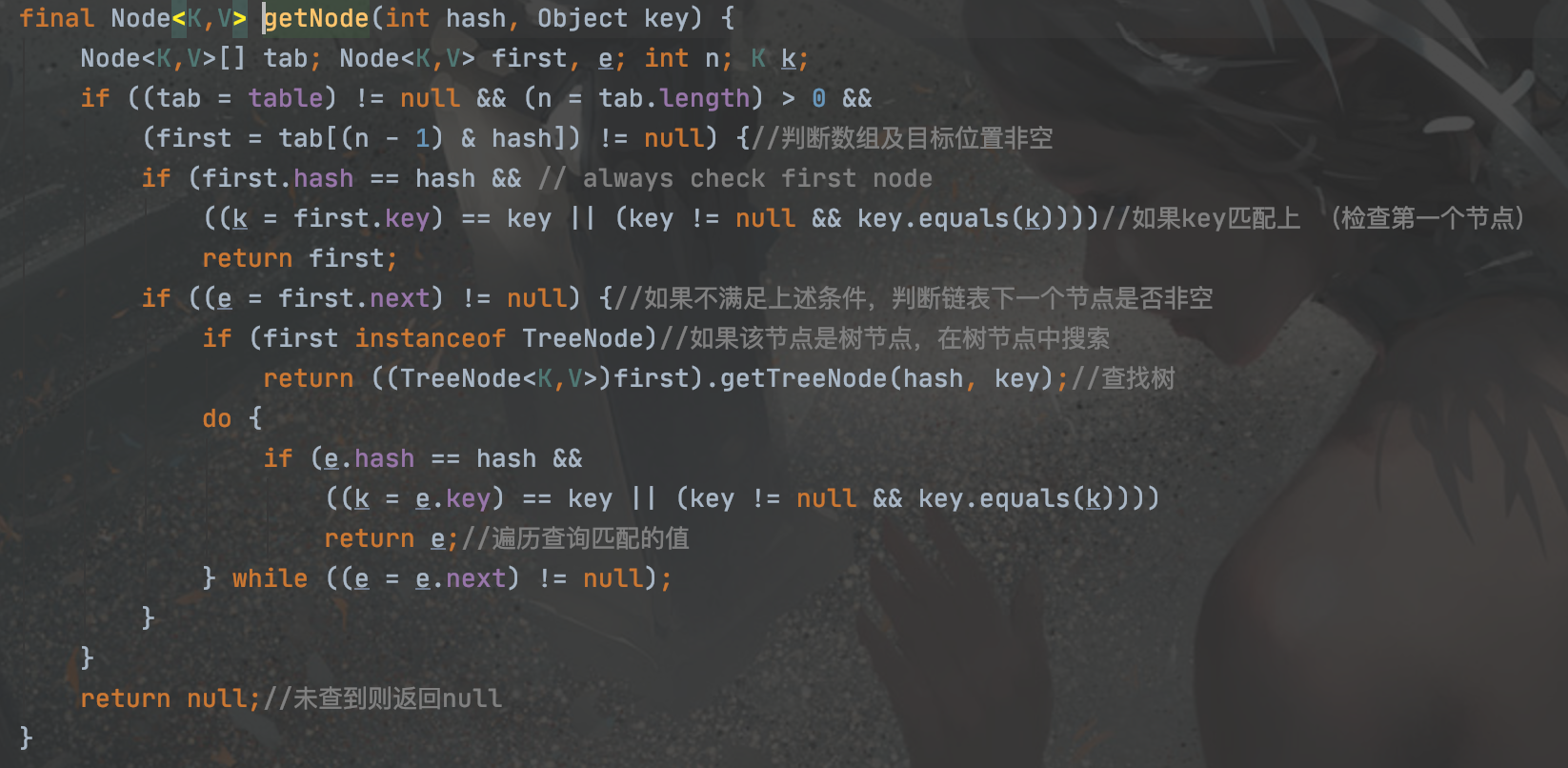
get方法:
 ?
?
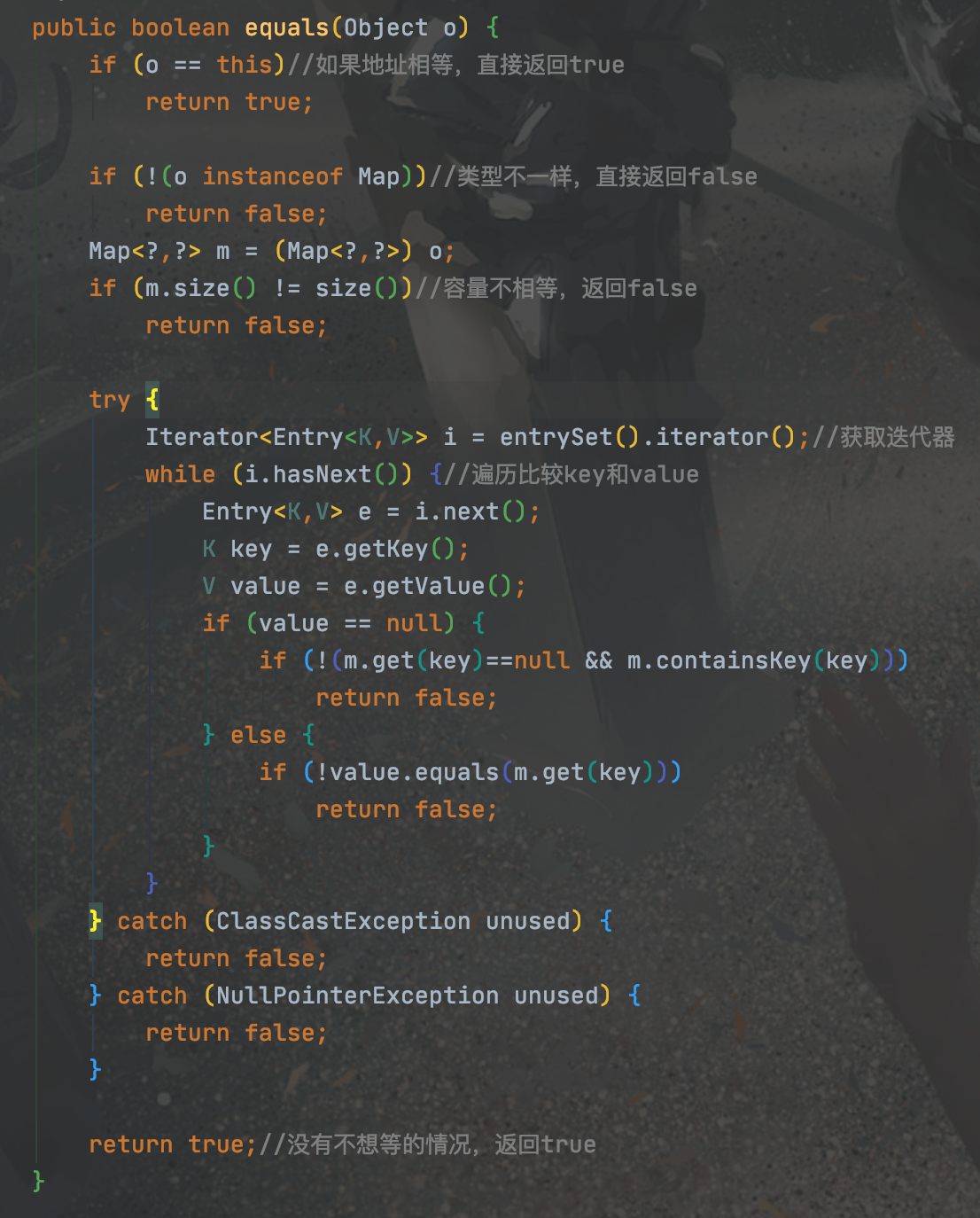
equals方法:
 ?
?
containsKey方法:
 ?
?
 ?
?
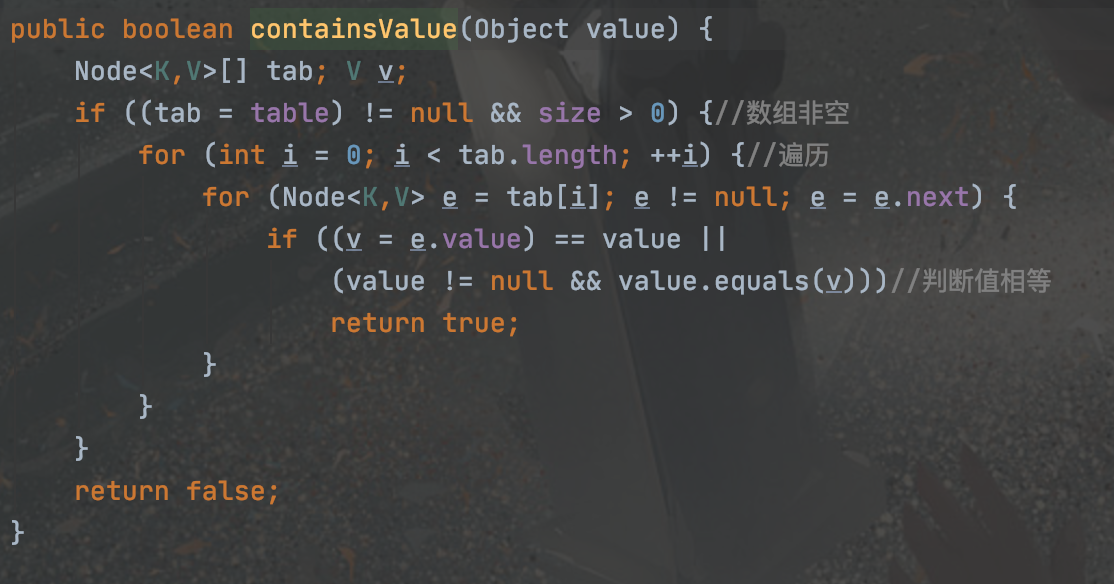
containsValue:
 ?
?
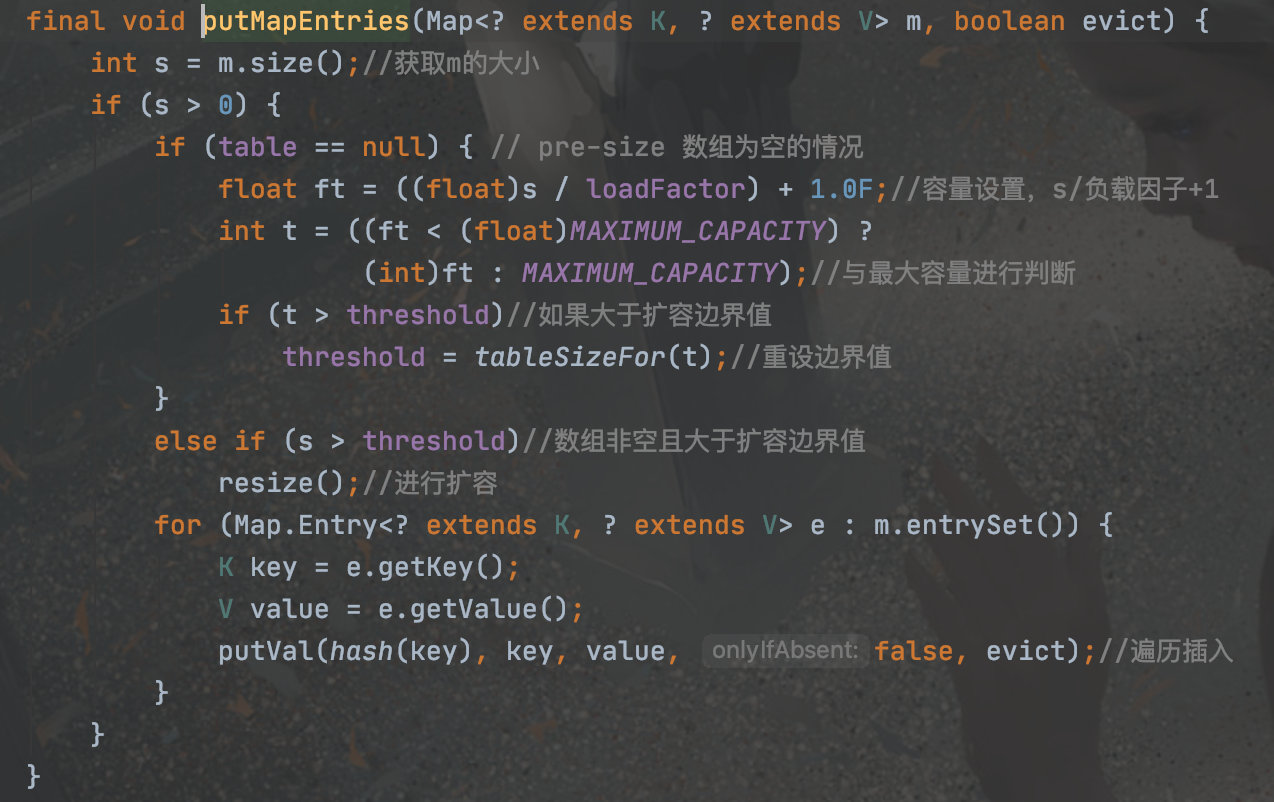
putAll:
 ?
?
 ?
?
keySet是在抽象方法中设置的
其中,设定hashmap数组大小的方法为:
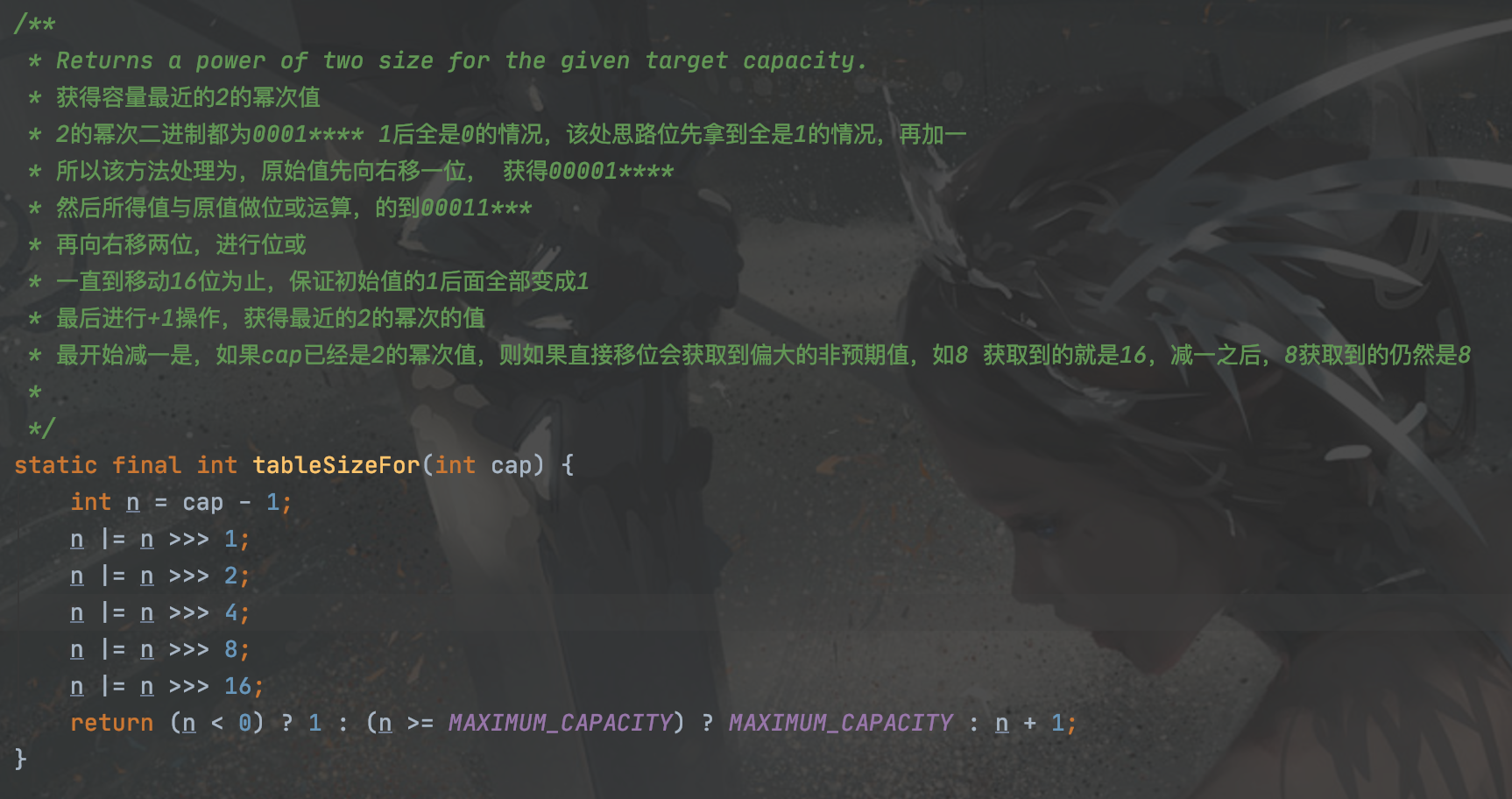 ?
?
为什么容量要是2的幂次
因为HashMap在存储元素时会根据元素的HashCode值运算出该元素应该被存在哪个位置,我们可以通过取模运算计算元素的存储位置h=hash%length,但是模运算效率极低,所以采取&运算,h=(length-1)&hash,length代表数组长度,hash代表hashCode值,h为计算出来的位置,当数组长度是2的次幂时,两种方式算出来的下标是一样的,但是&运算效率比%运算要高得多,所以容量总为2的次幂
hashmap数组加了transient关键字,在序列化时不参与,但是hashmap覆写了writeObject方法,所以序列化时,会写出table的数据
?
原文:https://www.cnblogs.com/sewell/p/15212269.html