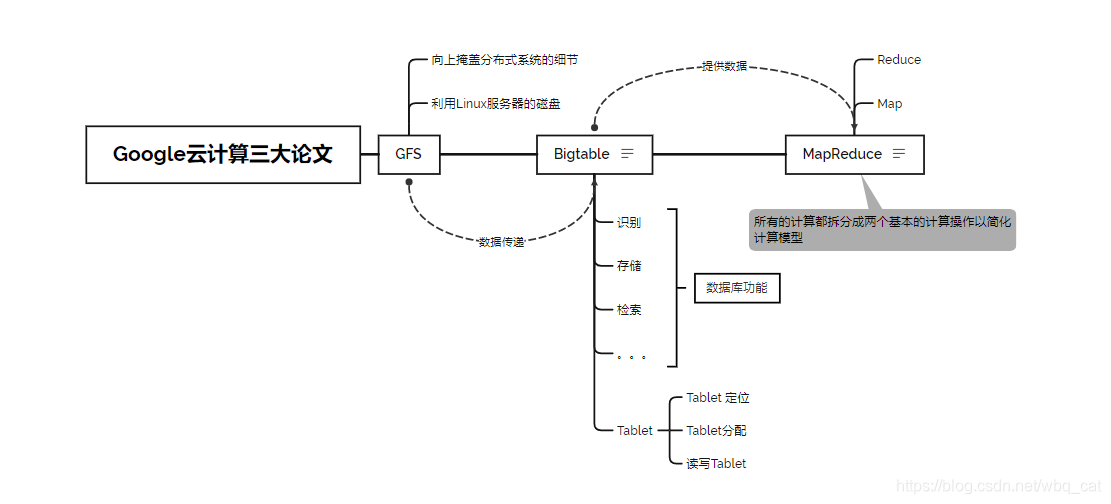
谷歌在2003到2006年间发表了三篇论文,《MapReduce: Simplified Data Processing on Large Clusters》,《Bigtable: A Distributed Storage System for Structured Data》和《The Google File System》介绍了Google如何对大规模数据进行存储和分析。这三篇论文开启了工业界的大数据时代。本文简单谈谈自己对于这几篇论文的理解。
本质是由于在21世纪的数据巨量增加,Google的单机或简单的分布式方案满足不了用户需求,所以出现的新的数据处理方案,其产物就是GFS(Google File System)。但GFS只负责文件的存储而不能提供数据库服务(基于内容的检索功能),所以进而Google开发了Bigtable作为数据库,向上层服务提供基于内容的各种功能。他们还开发了对于的数据处理工具MapReduce,在读取了Bigtable数据的技术上,根据业务需求,对数据内容进行运算。
题外:GFS论文一定程度催生了HDFS
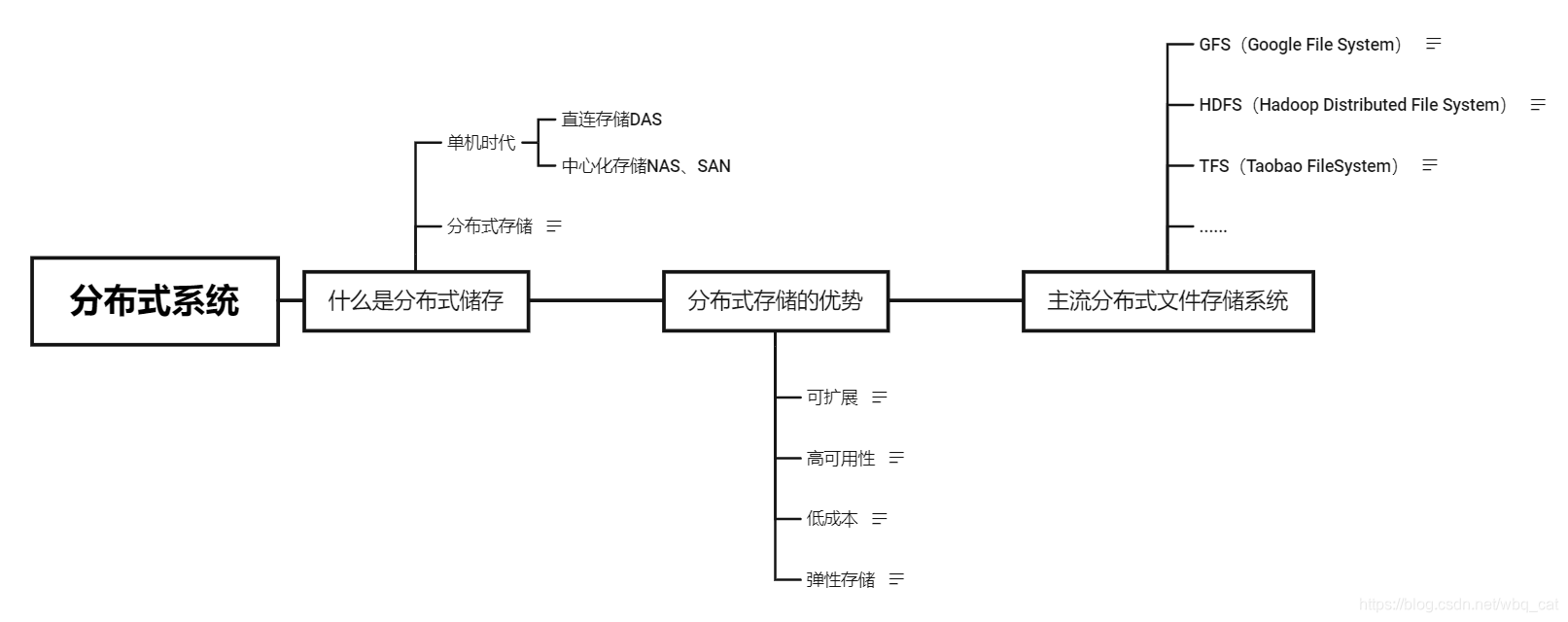
文件系统是负责管理和存储文件的系统软件,它是操作系统和硬件驱动之间的桥梁,操作系统通过文件系统提供的接口去存取文件,用户通过操作系统访问磁盘上的文件。
分布式文件系统(Distributed File System)是一种允许文件通过网络在多台主机上共享的文件系统,可以让多机器上的多用户进行文件分享和存储。 在这样的文件系统中,客户端并非直接访问底层的数据存储区块,而是通过网络,以特定的通信协议和服务器沟通
通过网络使用企业中的每台机器上的磁盘空间,并将这些分散的存储资源构成一个虚拟的存储设备,数据分散的存储在企业的各个角落。
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,通过软件的方式自动容错,它将服务器故障视为正常现象,通过软件的方式自动容错,在保证系统可靠性和可用性的同时,大大降低系统的成本。另一方面,它拥有着数据完整性,用于大型的、分布式的、对大量数据进行访问的应用。它又有着有效的诊断工具,广泛而细致的诊断日志以微小的代价换取了在问题隔离、诊断、性能分析方面起到了重大的作用。GFS服务器用日志来记录显著的事件,如服务器停机和启动和远程的应答。远程日志记录机器之间的请求和应答,通过收集不同机器上的日志记录,对它们进行分析恢复,就可以完整地重现活动的场景,并用此来进行错误分析。这些都给用户提供了总体性能较高的服务,比较方便快捷。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。
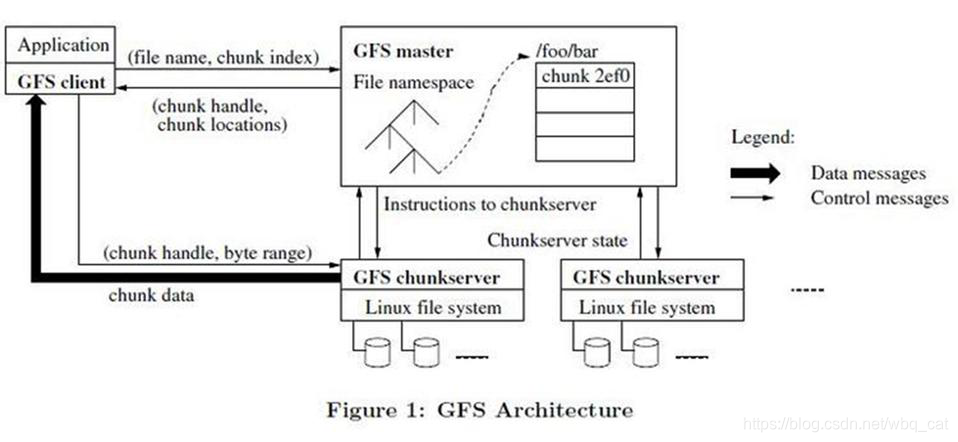
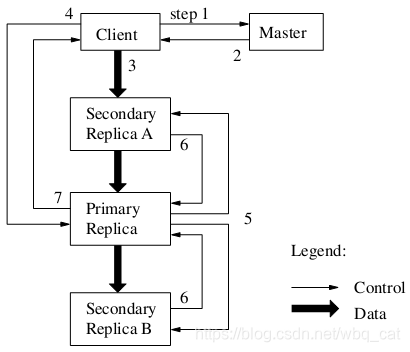
在GFS chunkserver中,文件都是分成固定大小的chunk来存储的,每个chunk通过全局唯一的64位的chunk handle来标识,chunk handle在chunk创建的时候由GFS master分配。GFS chunkserver把文件存储在本地磁盘中,读或写的时候需要指定文件名和字节范围,然后定位到对应的chunk。为了保证数据的可靠性,一个chunk一般会在多台GFS chunkserver上存储,默认为3份,但用户也可以根据自己的需要修改这个值。
GFS master管理所有的元数据信息,包括namespaces,访问控制信息,文件到chunk的映射信息,以及chunk的地址信息(即chunk存放在哪台GFS chunkserver上)。
GFS client是GFS应用端使用的API接口,client和GFS master交互来获取元数据信息,但是所有和数据相关的信息都是直接和GFS chunkserver来交互的
Application为使用gfs的应用,应用通过GFS client于gfs后端(GFS master和GFS chunkserver)打交道。
最小化所有操作和Master节点的交互
写入操作流程图
关于指定数据集合的一个完全可用拷贝,该拷贝包括相应数据在某个时间点(拷贝开始的时间点)的映像。快照可以是其所表示的数据的一个副本(duplicate),也可以是数据的一个复制品(replicate)。
论文原文引用:
快照操作几乎可以瞬间完成对一个文件或者目录树(“源”)做一个拷贝,并且几乎不会对正在进行的其它操作造成任何干扰。我们的用户可以使用快照迅速的创建一个巨大的数据集的分支拷贝(而且经常是递归的拷贝拷贝),或者是在做实验性的数据操作之前,使用快照操作备份当前状态,这样之后就可以轻松的提交或者回滚到备份时的状态。
个人理解:快照可以在一个副本损坏时,从Primary Replica或者其他副本复制数据,然后用新的节点代替损坏的节点。
快照是数据存储的某一时刻的状态记录;备份则是数据存储的某一个时刻的副本。这是两种完全不同的概念。
[关于快照:](快照与备份有什么区别?快照是备份的其中一种么?还是两种不同的概念? - 木头龙的回答 - 知乎 https://www.zhihu.com/question/20374919/answer/499376887)
2004年公布的 MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
将大数据由集中式计算过渡到分布式计算,以前提升算力的思路是让服务器越来越强,而分布式只需要增加服务器节点的数量,就能处理更大的数据量。
谷歌发布于2006年的Bigtable,其启发了无数的NoSQL数据库,比如:Cassandra、HBase等等。Cassandra架构中有一半是模仿Bigtable,包括了数据模型、SSTables以及提前写日志(另一半是模仿Amazon的Dynamo数据库,使用点对点集群模式)。
说到此,另两个产品Map Reduce和Big Table,它们则是基于GFS研发的。这三大基础核心技术构建出了完整的分布式运算架构。像Map Reduce,它是一种编程模型,用于大规模数据集的并行运算。Map(映射)和Reduce(归约),是它们的主要思想概念,这是从函数式编程语言借鉴的,并且还有矢量编程语言里的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将其程序运行在分布式系统上。 目前软件实现是指定一个Map函数,把一组键值对映射成一组新的键值对,指定并发的Reduce函数,用来保证所有映射的键值对中的每一个共享相同的键组。而Big Table则是分布式数据存储系统,用来处理海量的数据的一种非关系型的数据库。Bigtable是非关系型数据库,是一个稀疏的、分布式的和持久化存储的多维度排序Map。它适用于廉价设备,适合大规模海量数据以及分布式、并发数据处理,易于扩展,效率极高,支持动态伸缩。
Above the Clouds: A Berkeley View of Cloud
Computing
原文:https://www.cnblogs.com/whitea/p/GFS_essay.html