在经济学中,技术效率是指在既定的投入下产出可增加的能力或在既定的产出下投入可减少的能力。常用度量技术效率的方法是生产前沿分析方法。所谓生产前沿是指在一定的技术水平下,各种比例投入所对应的最大产出集合。而生产前沿通常用生产函数表示。前沿分析方法根据是否已知生产函数的具体的形式分为参数方法和非参数方法,前者以随机前沿分析(StochasticFrontierAnalysis,下文简称SFA)为代表,后者以数据包络分析(DataEnvelopeAnalysis,下文简称DEA)为代表。
本文在R软件中实现SFA、DEA与自由处置包分析FDH模型。
1.按照p=0.2的二项分布,随机生成一个大小为100的向量。
其他分布。泊松P(λ)(函数rpois)等。
2. 数字变量 按照高斯分布N(μ=1,σ=1)随机生成一个大小为100的向量。
> x hist(x, main = "")其他分布。Uniform U[a,b](函数runif)等等。
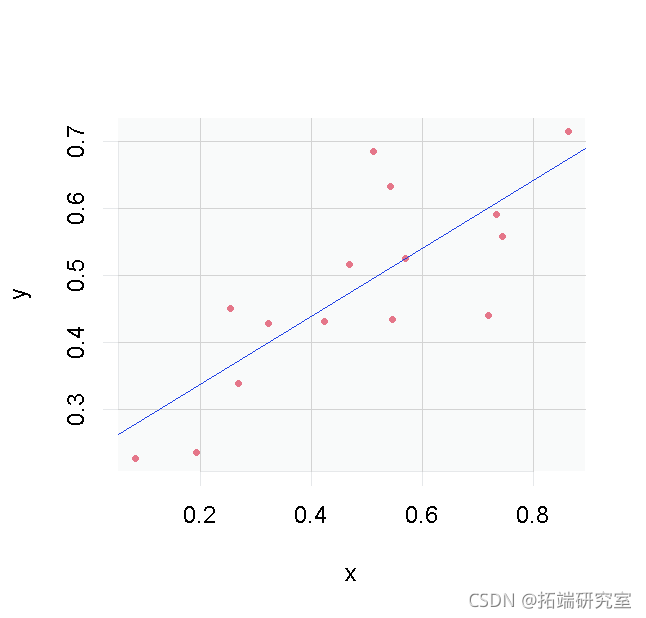
输出y和输入x都是n=15的大小
真正的前沿是由函数定义的。
![]()
为了模拟数据:
1. 定义输入的矢量为x~U[0,1]
2. 定义一个向量u~N+(μ = 0.25, σ = 0.2)
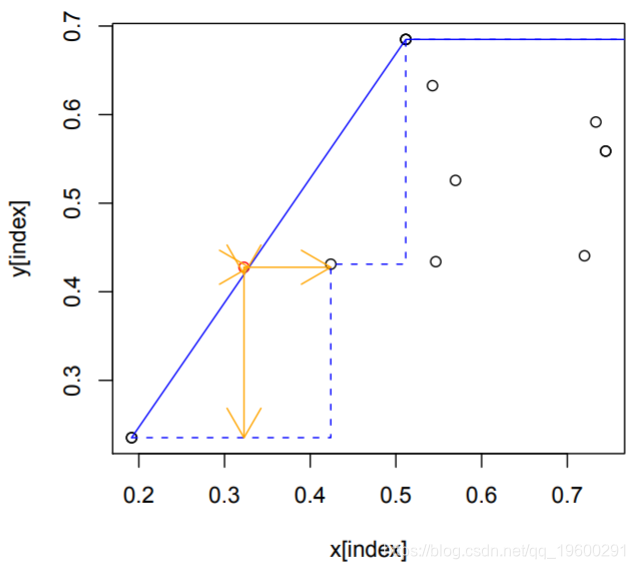
3. 输入的矢量定义为 ![]()
函数set.seed允许我们保持相同的模拟数据
模拟数据。
> plot(y ~ x绘制真正的边界。
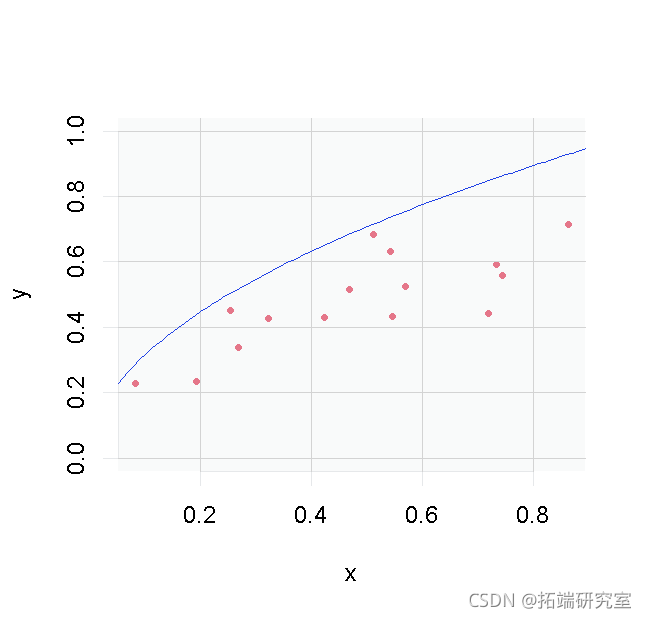
以产出为导向的测算。
![]()
输入导向的方法:
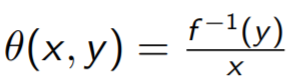
Shepard 方法:
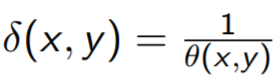
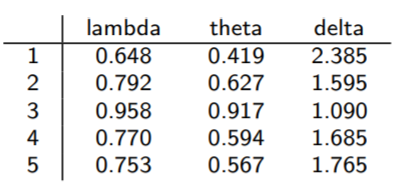
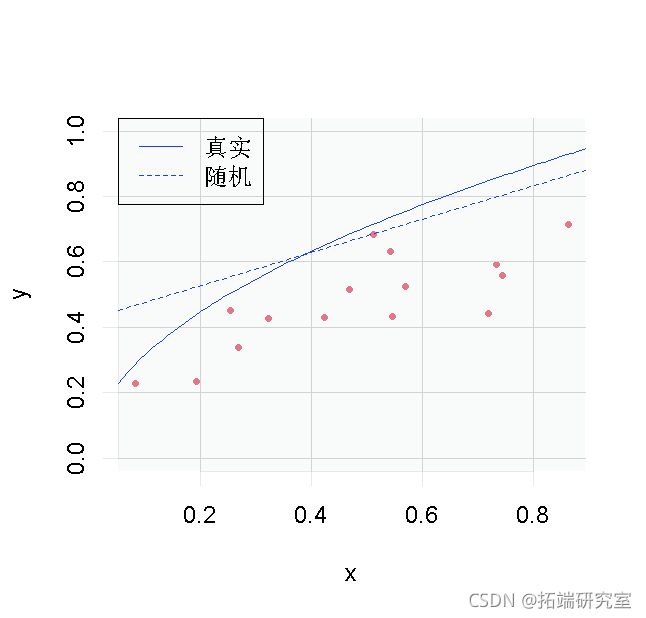
表:真实前沿效率
1.用函数lm调整一个线性模型,并保留回归线的系数β:y = α + βx
2. 找到能使(yi-y?i)最大化的公司k,i=1,...,n。注意,公司k可以通过函数识别来手动找到和检测
3. 计算α 0,使回归线y = α 0 + βx穿过企业k,并代表随机前沿。
> res.lm <- lm(y ~ x)
让我们定义f1 : x → α 0 + βx
> f1 = function(x) alpha2 + beta.lm[2] * x
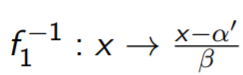
> f1.inv = function(x) (x - alpha2)/beta.lm[2]面向产出的方法。
![]()
面向输入的方法:
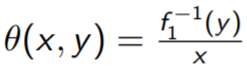
Shepard 方法:
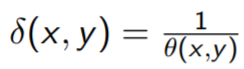
手动检测位于两个边界上的公司
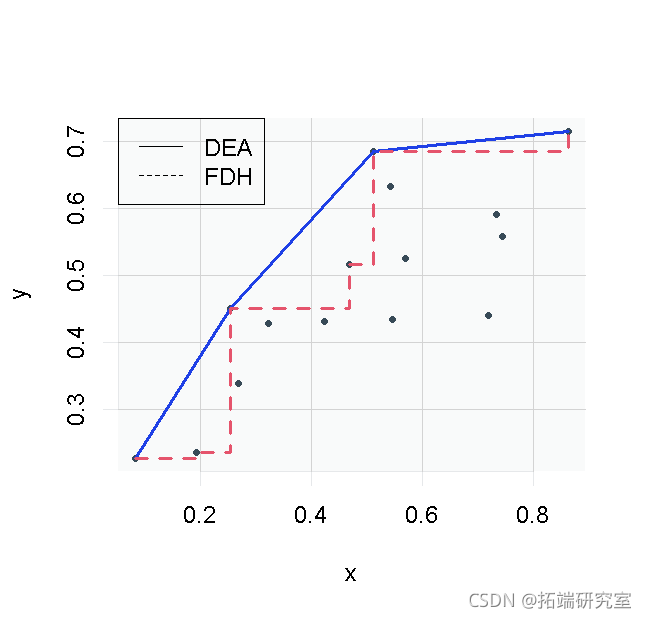
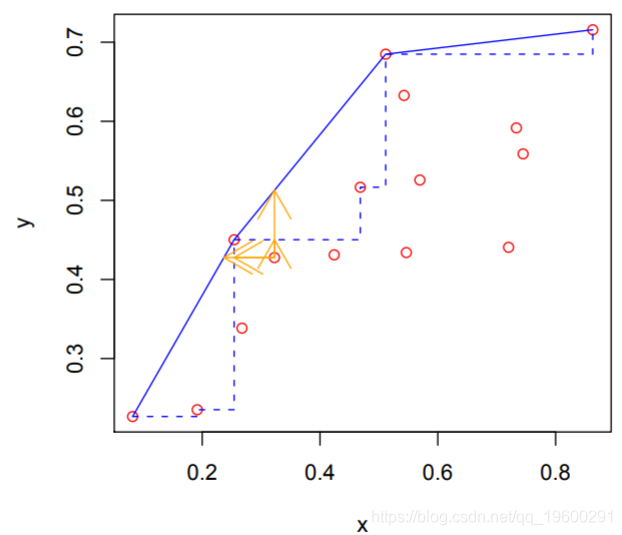
让我们考虑5号公司
1. 如果该公司在输出方向上是有效的,它将位于前沿线的哪一部分? 在输入方向上?
2. 利用这个估计前沿的位置,计算出效率的衡量标准
重复B次(用循环的方式)
1.用函数样本在15个观测值中取样
2.计算前沿的新估计值
3.计算新的效率方法
4. 储存结果,计算偏差, 方差, 置信区间
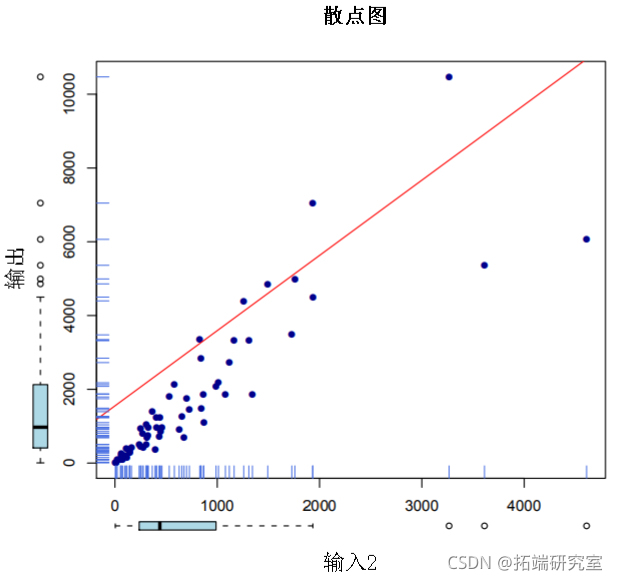
在62个农场观察到一个输出变量和三个输入变量
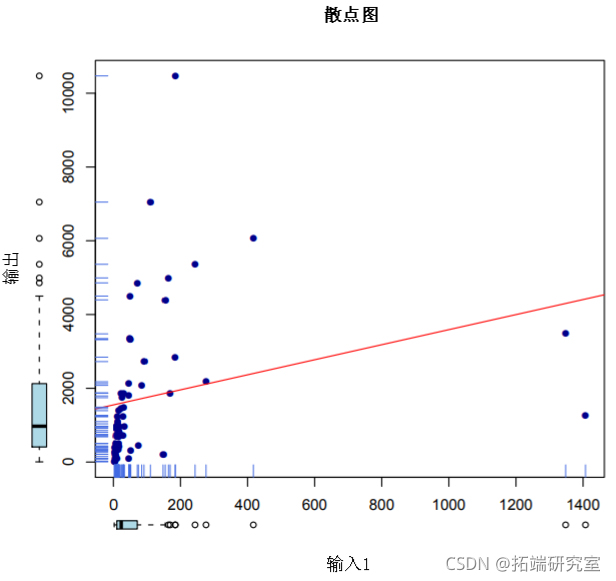
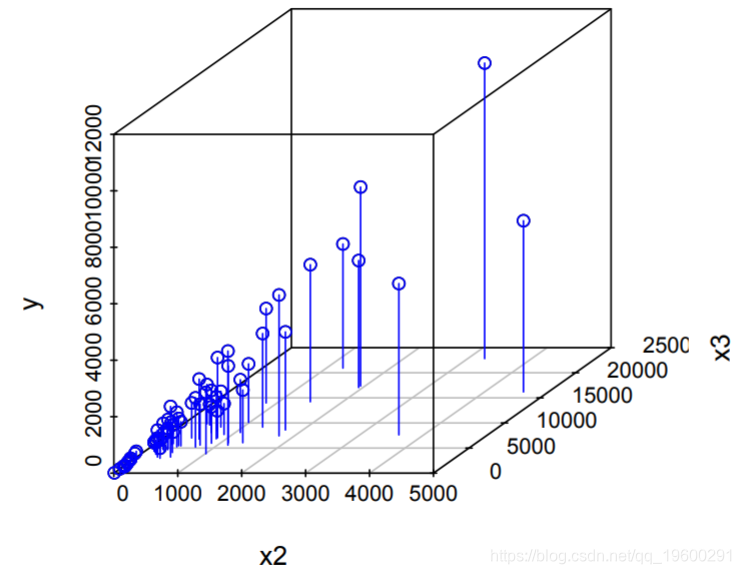
p个输入包含在一个p×n的矩阵中
> input <- t(cbind(spain$x1, spain$x2, spain$x3))
q个输出包含在一个q×n的矩阵中
> output <- t(matrix(spain$y))
计算 DEA 效率估计值
计算 FDH 效率估计值
计算m阶效率估计值
计算非参数的条件和非条件的α-量化估计(默认情况下,α=0.95
你可以使用函数order或sort来计算企业的排名,排名根据效率测算。
> plot(density(res.dea)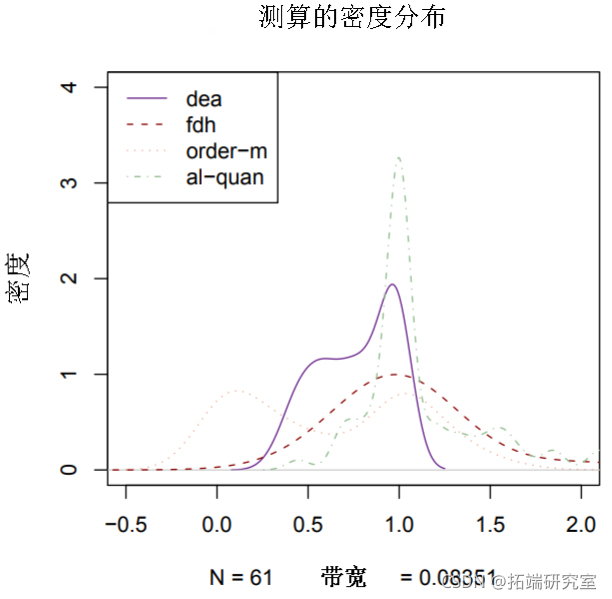
函数boot实现了Simar和Wilson(1998)的bootstrap方法,用于估计Shepard(1970)输入和输出距离函数的置信区间。
> boot(input, output)

最受欢迎的见解
3.matlab中的偏最小二乘回归(PLSR)和主成分回归(PCR)
6.r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
7.R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
9.R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
拓端tecdat|R语言实现随机前沿分析SFA、数据包络分析DEA、自由处置包分析FDH和BOOTSTRAP方法
原文:https://www.cnblogs.com/tecdat/p/15250683.html