本文介绍了Redis复制的主要流程和设计思想。通过本文的阅读,您大致能理解复制在软件架构方面的通用思想。在阅读本文之前,希望读者首先对Redis有一定的认识,对Redis的事件类型、和事件处理器有个基本的了解。因为本文主要讲复制的流程,所以很多额外的知识点只是一笔带过、想要更多的了解,自行参考网上资料。话不多说、进入主题。
在redis复制的过程中,参与者主要就是redis的主从架构。复制是从一方复制数据到另一方,所以两台Redis机器是必不可少的参与对象。一台主机、一台从机!参考Redis复制的主要流程,我将它分为以下几个小模块来分析。
Redis使用状态机的策略来把以上流程给串接起来。即在每个阶段都配置一个状态码、及每个状态码下执行的代码流程!
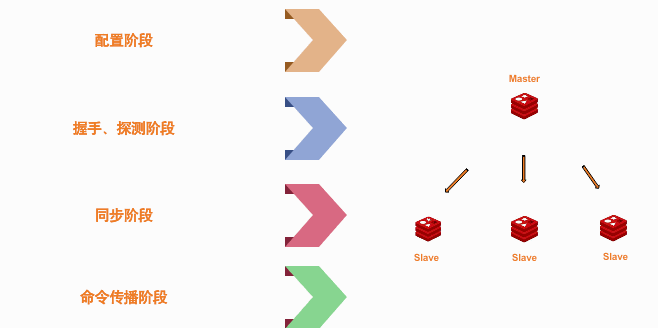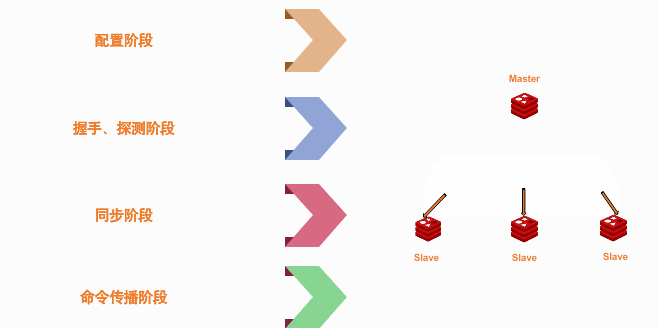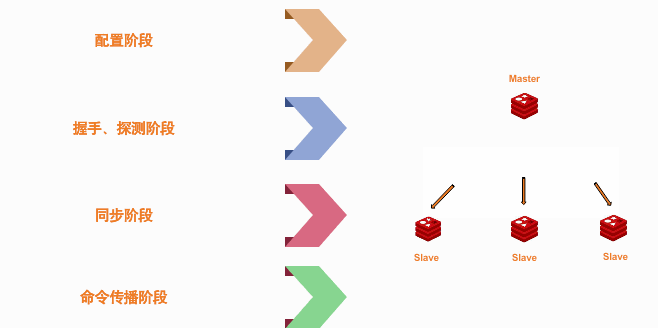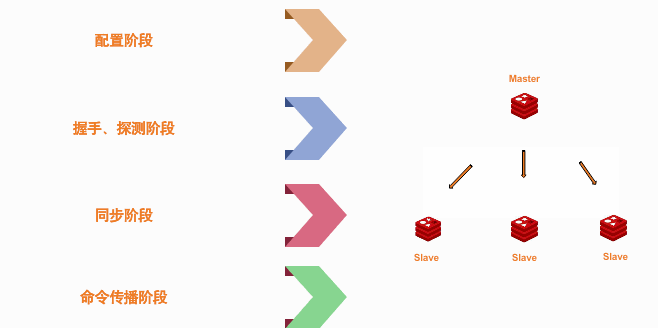
主从机是通过TCP协议来进行数据传输。所以它们首先就要建立一个安全的链接通道,以便可以通信!那么我们就要在从机启动的时候配置个,它要向谁要数据,认哪个主机为自己的Master! 配置有以下几种方法
1、 通过配置文件配置
在Redis.conf时添加要建立链接的主机信息、
echo slaveof masterIp masterPort >> redis.conf
2、通过客户端
我们可以通过终端链接到从机
//链接到从机
redis-cli -p <从机port>
//执行
slaveof masterIp masterPort
3、通过启动时指定参数
也可以在启动从机的时候带上指定参数
redis-server redis.conf --slaveof masterIp masterPort
那么以上三种方法都可以让当前启动的从机保存既然要链接到主机的地址、和端口号!这三种方法有一定的区别,通过配置文件保存的启动方式比较靠普一些。当配置好主机信息后,那么接下来就要链接到主机!
经过以上三种方式的配置,状态机里的状态码配置成REPL_STATE_CONNECT
/* Set replication to the specified master address and port. */
void replicationSetMaster(char *ip, int port) {
int was_master = server.masterhost == NULL;
//其他代码.....
//配置状态机为 REPL_STATE_CONNECT
server.repl_state = REPL_STATE_CONNECT;
}
上面说到从机配置好了主机的地址和端口,那么如何触发链接呢?这就是Redis的时间事件函数serverCron, 它做了很多事情。其中它做了一件事就是:维护主从机数据同步。
/* Replication cron function -- used to reconnect to master,
* detect transfer failures, start background RDB transfers and so forth. */
/* 1000ms执行一次 replicationCron这个函数 */
run_with_period(1000) replicationCron();
这个replicationCron函数会去检测状态机的状态码、上回我们的状态码是REPL_STATE_CONNECT
void replicationCron(void) {
//.....
/* Check if we should connect to a MASTER */
if (server.repl_state == REPL_STATE_CONNECT) {
serverLog(LL_NOTICE,"Connecting to MASTER %s:%d",
server.masterhost, server.masterport);
if (connectWithMaster() == C_OK) {
serverLog(LL_NOTICE,"MASTER <-> REPLICA sync started");
}
}
//....
}
小学英文水准也能看的懂是吧、检测是否去链接Master!!!判断条件很简单、就是那个状态码!!接下来看下connectWithMaster链接主机的函数
int connectWithMaster(void) {
int fd;
//采用了NonBlock的方式 可以参考《UNIX网络编程》-卷1(16节)的非阻塞I/O部分
fd = anetTcpNonBlockBestEffortBindConnect(NULL,
server.masterhost,server.masterport,NET_FIRST_BIND_ADDR);
if (fd == -1) {
serverLog(LL_WARNING,"Unable to connect to MASTER: %s",
strerror(errno));
return C_ERR;
}
//文件事件、大致思想参考《UNIX网络编程》-卷1(6节)I/O复用
if (aeCreateFileEvent(server.el,fd,AE_READABLE|AE_WRITABLE,syncWithMaster,NULL) ==
AE_ERR)
{
close(fd);
serverLog(LL_WARNING,"Can‘t create readable event for SYNC");
return C_ERR;
}
server.repl_transfer_lastio = server.unixtime;
//保存链接套节字
server.repl_transfer_s = fd;
server.repl_state = REPL_STATE_CONNECTING;
return C_OK;
}
这就和Master建立TCP链接、使得状态变成REPL_STATE_CONNECTING模式。
当我们从机链接到主机后、也不是立马进行数据发送,进行同步。它和那一样、也要做足了前戏!过程相当的多,但都很简单!没有什么重点可讲的,我们大致过下

if (server.repl_state == REPL_STATE_RECEIVE_CAPA) {
//读取回复
err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
/* Ignore the error if any, not all the Redis versions support
* REPLCONF capa. */
if (err[0] == ‘-‘) {
serverLog(LL_NOTICE,"(Non critical) Master does not understand "
"REPLCONF capa: %s", err);
}
sdsfree(err);
server.repl_state = REPL_STATE_SEND_PSYNC;
}
经过上面那一系列的"互相认识"阶段,最终让状态变成REPL_STATE_SEND_PSYNC
那么到这里就可以真正的同步数据了,万事具备了!上回说状态到了REPL_STATE_SEND_PSYNC,且看源码:
if (server.repl_state == REPL_STATE_SEND_PSYNC) {
if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR) {
err = sdsnew("Write error sending the PSYNC command.");
goto write_error;
}
server.repl_state = REPL_STATE_RECEIVE_PSYNC;
return;
}
主要函数slaveTryPartialResynchronization 小学水平翻译下:“从机尝试部分同步”。这里为为什么要尝试部分同步呢?之前咱们说到:Redis早期的版本不支持部分同步,后来才支持的。函数名我估计是:如果当前这台机器同步过数据,那么走部分同步,如果没有就走全部同步,所以起了个slaveTryPartialResynchronization 这也是我的猜想啊、看源码很累,有时候猜也能帮助你顺着往下看,如果你每个函数都看一下,会累死的!猜函数的大致用法也是看源码的方法之一!
既然来了还是带看下源码吧!
/**
* fd :链接套节字,你就认为中 socekt里 socket_accpet 那返回的玩意儿,用于相互同信的!
* read_reply: 这个函数分为两个部分、用这个值来区分,通俗了说也就是、传递1干什么、传递0干什么、
* 我们看下源码里
*/
int slaveTryPartialResynchronization(int fd, int read_reply) {
/* Writing half */
if (!read_reply) {
/*
* 当不可读的时候,取就是写的时候,即往fd里写数据。即向对方发送数据!
*/
return 状态常量
}
/* Reading half */
/**
* 上面是发送数据,下面就是读取数据的源码咯!
*/
}
很显示、上面这函数分了两大块,由read_reply参数来决定,是发送数据,还是读取数据!就两件事
0:发送数据
1:读取数据
接下来看一张图吧、单独用文字来解释有点绕

上面这张图大致的来表示了一个干净的从机,第一次向主机同步数据的过程,下面解释下这张图
psync ? -1我们还是来看下源码、回到 slaveTryPartialResynchronization函数:
int slaveTryPartialResynchronization(int fd, int read_reply) {
char *psync_replid;
char psync_offset[32];
sds reply;
/* Writing half */
if (!read_reply) {
server.master_initial_offset = -1;
//如果有主机的数据、
if (server.cached_master) {
psync_replid = server.cached_master->replid;
snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1);
serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset);
} else {
//没有情况
serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)");
psync_replid = "?";
memcpy(psync_offset,"-1",3);
}
//发送 PSYNC 指令
/* Issue the PSYNC command */
reply = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC",psync_replid,psync_offset,NULL);
if (reply != NULL) {
serverLog(LL_WARNING,"Unable to send PSYNC to master: %s",reply);
sdsfree(reply);
aeDeleteFileEvent(server.el,fd,AE_READABLE);
return PSYNC_WRITE_ERROR;
}
return PSYNC_WAIT_REPLY;
}
// 读的部分...省略
}
PSYNC指令有两个参数、
从上面的逻辑可以看出来、当有同步过的时候,psync_replid和psync_offset会取出相对就的值、如果没有则用"?"和“-1”来给值。通常情况下,我们是一个新机器,所以没有同步过主机信息,即cached_master为false所以:
// psync_replid = ?
// psync_offset = -1
sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC", "?", -1, NULL);
接下来把状态变更为PSYNC_WAIT_REPLY等待主机的回复!
主机在接收到从机发来的PSYNC命令时大致的流程是会去fock一个子进程出来做bgSave的事情、有关于Redis持久化的过程不在本文描述、可以自寻资料观看。当主机接收到PSYNC指令的时候,解析指令,我们转到主机视角看如何解析!我们主要分析下关键代码~
void syncCommand(client *c) {
// 一系列的判断代码、略过
//因为我们是第一次同步、所以 尝试部分同步会失败、 走到下面的 else 里 stat_sync_partial_err++
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
} else {
char *master_replid = c->argv[1]->ptr;
/* Increment stats for failed PSYNCs, but only if the
* replid is not "?", as this is used by slaves to force a full
* resync on purpose when they are not albe to partially
* resync. */
if (master_replid[0] != ‘?‘) server.stat_sync_partial_err++;
}
} else {
/* If a slave uses SYNC, we are dealing with an old implementation
* of the replication protocol (like redis-cli --slave). Flag the client
* so that we don‘t expect to receive REPLCONF ACK feedbacks. */
c->flags |= CLIENT_PRE_PSYNC;
}
//以主机的视角来看的话,这里很多代码是做一些 数据保存、主要把从机的信息保存下来、
/* Setup the slave as one waiting for BGSAVE to start. The following code
* paths will change the state if we handle the slave differently. */
//标识当前这个从机的同步状态、标识从机为CLIENT_SLAVE身份、加入从机列表、
c->replstate = SLAVE_STATE_WAIT_BGSAVE_START;//这个打个flag ,下面将会用到。先标识状态
if (server.repl_disable_tcp_nodelay)
anetDisableTcpNoDelay(NULL, c->fd); /* Non critical if it fails. */
c->repldbfd = -1;
c->flags |= CLIENT_SLAVE;
listAddNodeTail(server.slaves,c);
//这里创建一个复制积压缓冲区,用于部分同步,稍后讲到、这里打个flag
/* Create the replication backlog if needed. */
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) {
/* When we create the backlog from scratch, we always use a new
* replication ID and clear the ID2, since there is no valid
* past history. */
changeReplicationId();
clearReplicationId2();
createReplicationBacklog();
}
//下面有三个case 因为我们是第一次请求主机同步。所以没有任务bgsave progress(这里假设,方便我们阅读代码,和顺应场景)
/* CASE 1: BGSAVE is in progress, with disk target. */
if (server.rdb_child_pid != -1 &&
server.rdb_child_type == RDB_CHILD_TYPE_DISK)
{
/* CASE 2: BGSAVE is in progress, with socket target. */
} else if (server.rdb_child_pid != -1 &&
server.rdb_child_type == RDB_CHILD_TYPE_SOCKET)
{
/* There is an RDB child process but it is writing directly to
* children sockets. We need to wait for the next BGSAVE
* in order to synchronize. */
serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
/* CASE 3: There is no BGSAVE is progress. */
} else {
if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF)) {
/* Diskless replication RDB child is created inside
* replicationCron() since we want to delay its start a
* few seconds to wait for more slaves to arrive. */
if (server.repl_diskless_sync_delay)
serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC");
} else {
/* Target is disk (or the slave is not capable of supporting
* diskless replication) and we don‘t have a BGSAVE in progress,
* let‘s start one. */
if (server.aof_child_pid == -1) {
//开始为同步进行Bgsave操作
startBgsaveForReplication(c->slave_capa);
} else {
serverLog(LL_NOTICE,
"No BGSAVE in progress, but an AOF rewrite is active. "
"BGSAVE for replication delayed");
}
}
}
return;
}
如果都没出错的知识(主机默认支持无磁化同步),那么开始startBgsaveForReplication 再接着往下看
int startBgsaveForReplication(int mincapa) {
int retval;
int socket_target = server.repl_diskless_sync && (mincapa & SLAVE_CAPA_EOF);
listIter li;
listNode *ln;
//开始bgsave为同步准备, socket_target 为复制到socket还是磁盘的判断
serverLog(LL_NOTICE,"Starting BGSAVE for SYNC with target: %s",
socket_target ? "replicas sockets" : "disk");
//准备RDB文件 开始
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* Only do rdbSave* when rsiptr is not NULL,
* otherwise slave will miss repl-stream-db. */
if (rsiptr) {
if (socket_target)
//保存到socket
retval = rdbSaveToSlavesSockets(rsiptr);
else
///保存到disk
retval = rdbSaveBackground(server.rdb_filename,rsiptr);
} else {
serverLog(LL_WARNING,"BGSAVE for replication: replication information not available, can‘t generate the RDB file right now. Try later.");
retval = C_ERR;
}
//准备RDB文件 结束
//如果错误 那么采取的应对方法、找到等待同步的从机,
if (retval == C_ERR) {
serverLog(LL_WARNING,"BGSAVE for replication failed");
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
//找到等待同步的从机,
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) {
slave->replstate = REPL_STATE_NONE;
slave->flags &= ~CLIENT_SLAVE;
//删除节点、看样子从列表中删除当前这个从机
listDelNode(server.slaves,ln);
//向从机发送日志、
addReplyError(slave,
"BGSAVE failed, replication can‘t continue");
//标识为close状态
slave->flags |= CLIENT_CLOSE_AFTER_REPLY;
}
}
return retval;
}
/* If the target is socket, rdbSaveToSlavesSockets() already setup
* the salves for a full resync. Otherwise for disk target do it now.*/
//走到这里、socket_tartget = false
if (!socket_target) {
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
//找在等待同步开始的从机、这个状态在上面设置过的,
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) {
replicationSetupSlaveForFullResync(slave,
getPsyncInitialOffset());
}
}
}
/* Flush the script cache, since we need that slave differences are
* accumulated without requiring slaves to match our cached scripts. */
if (retval == C_OK) replicationScriptCacheFlush();
return retval;
}
经过上面很流程,终于走到了函数replicationSetupSlaveForFullResync、这里再次提醒下大家在看源码的时候,不要多看,顺着主流程往下看,每个函数的分支比较多,看多了容易看不回来。切记!
int replicationSetupSlaveForFullResync(client *slave, long long offset) {
char buf[128];
int buflen;
//这个函数很简单了、配置从机和复制偏移量、配置从机的复制状态、
slave->psync_initial_offset = offset;
slave->replstate = SLAVE_STATE_WAIT_BGSAVE_END;
/* We are going to accumulate the incremental changes for this
* slave as well. Set slaveseldb to -1 in order to force to re-emit
* a SELECT statement in the replication stream. */
server.slaveseldb = -1;
/* Don‘t send this reply to slaves that approached us with
* the old SYNC command. */
if (!(slave->flags & CLIENT_PRE_PSYNC)) {
buflen = snprintf(buf,sizeof(buf),"+FULLRESYNC %s %lld\r\n",
server.replid,offset);
//写入数据、 FULLRESYNC replid offset
if (write(slave->fd,buf,buflen) != buflen) {
freeClientAsync(slave);
return C_ERR;
}
}
return C_OK;
}
好了、到这里从机发送 psync ? -1的流程就完整了,最后主机把自己的replid和offset发送给了从机!至于replid和offset的作用和含意我们下文说到! 源码链路不算太长,沿着主线看就行,抛开那些不是很重要的代码!
接着我们回到从机的视角
因为有数据回来,Redis的文件事件会自动触发syncWithMaster回到slaveTryPartialResynchronization函数、参数是1
psync_result = slaveTryPartialResynchronization(fd,1);
if (psync_result == PSYNC_CONTINUE) {
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization.");
return;
}
int slaveTryPartialResynchronization(int fd, int read_reply) {
/* Reading half */
//读取数据
reply = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
if (sdslen(reply) == 0) {
/* The master may send empty newlines after it receives PSYNC
* and before to reply, just to keep the connection alive. */
sdsfree(reply);
return PSYNC_WAIT_REPLY;
}
aeDeleteFileEvent(server.el,fd,AE_READABLE);
//如果是FULLRESYNC
if (!strncmp(reply,"+FULLRESYNC",11)) {
char *replid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the run id
* and the replication offset. */
replid = strchr(reply,‘ ‘);
if (replid) {
replid++;
offset = strchr(replid,‘ ‘);
if (offset) offset++;
}
if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) {
serverLog(LL_WARNING,
"Master replied with wrong +FULLRESYNC syntax.");
/* This is an unexpected condition, actually the +FULLRESYNC
* reply means that the master supports PSYNC, but the reply
* format seems wrong. To stay safe we blank the master
* replid to make sure next PSYNCs will fail. */
memset(server.master_replid,0,CONFIG_RUN_ID_SIZE+1);
} else {
//记录返回来的replid 和 offset
memcpy(server.master_replid, replid, offset-replid-1);
server.master_replid[CONFIG_RUN_ID_SIZE] = ‘\0‘;
server.master_initial_offset = strtoll(offset,NULL,10);
serverLog(LL_NOTICE,"Full resync from master: %s:%lld",
server.master_replid,
server.master_initial_offset);
}
/* We are going to full resync, discard the cached master structure. */
//清空已经存在的主机信息
replicationDiscardCachedMaster();
sdsfree(reply);
return PSYNC_FULLRESYNC;
}
}
从机读取到了从主机发来的FULLRESYNC信息后、保存了一些返回来的信息、接下来回到syncWithMaster下面的代码
/* Prepare a suitable temp file for bulk transfer */
//准备一个临时文件、来放主机传递过来的RDB文件、
while(maxtries--) {
snprintf(tmpfile,256,
"temp-%d.%ld.rdb",(int)server.unixtime,(long int)getpid());
dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644);
if (dfd != -1) break;
sleep(1);
}
if (dfd == -1) {
serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno));
goto error;
}
/* Setup the non blocking download of the bulk file. */
//监听事件、回调函数 readSyncBulkPayload、 用来接收RDB文件!!
if (aeCreateFileEvent(server.el,fd, AE_READABLE,readSyncBulkPayload,NULL)
== AE_ERR)
{
serverLog(LL_WARNING,
"Can‘t create readable event for SYNC: %s (fd=%d)",
strerror(errno),fd);
goto error;
}
//配置状态为等着接收RDB、初始一些初始化数据
server.repl_state = REPL_STATE_TRANSFER;
server.repl_transfer_size = -1;
server.repl_transfer_read = 0;
server.repl_transfer_last_fsync_off = 0;
server.repl_transfer_fd = dfd;
server.repl_transfer_lastio = server.unixtime;
server.repl_transfer_tmpfile = zstrdup(tmpfile);
return;
到这里、syncWithMaster这个函数就结束了最终把状态机变更为REPL_STATE_TRANSFER,配置回调函数为readSyncBulkPayload来处理RDB文件!!!
readSyncBulkPayload这个函数就不分析了,太长了、主要就是把接收到RDB文件写到临时文件、清空数据、然后加载到数据库、释放各种资源!
当主机和从机建立链接后,其实就可以正常的复制数据了,当主机准备RDB的时候,也会有正常的命令打进来,这时候因为从机状态是等待同步,所以这些命令会被打入到缓存区,等RDB文件同步完,主机会把缓冲区的数据打到从机,更新数据、这部分就不说了。到这里,同步就算完成了!!!
结过上面那些流程,总算能让主从机达到数据的一致性、但是我们服务器是一直运行的,所以我们需要把主机的命令及时的同步到从机上面、但总不是每次都是同步RDB文件、那代价也太大了!

一个需求产生就有一个相对应的应对方法!命令传播程序!主机在接收到数据的,经过命令传播程序会把数据发送给自己的小从机们、有达到数据的一致性!因为考虑到Redis的高效性,命令传播是异步进行的,所以在数据一致性上还是有点差异的,鱼和熊掌不可兼得。作者也做了很多的弥补工作、后面再说!关于命令传播的源码就不放出来了replicationFeedSlaves可以自行观看、就是把数据写到从机的 replcation buffer里。同时也写到backLog buffer(下文说)
自此主从整个复制流程已经结束!主机机器已经能够正常的同步数据了!
等一等!!
从机也有断网断电的时候啊、不能我再次链接上来的时候又准备RDB文件吧。所以作者又再一次进行了优化,我也支持你批量同步!

部分同步的三个点~
这个很容易理解,图上已经说明、不再描述。
那么通过下面这个图来理解下offset和backlogbuffer。在命令传播阶段、主机不仅把命令传递到从机、还把接收到命令按字节数写到backlogbuffer区,就是为了怕从机没有接收到传递的数据,备份一下! 每次接收到新数据,主机和从机都会更新自己的 offset值,以达到两边保持一致!

首先backlogbuffer什么时候是创建的呢?
void syncCommand(client *c) {
//主机在解析从机发来 PSYNC 命令时、
//当有一个从机的时候、并且 back_log为null的时候
/* Create the replication backlog if needed. */
if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) {
/* When we create the backlog from scratch, we always use a new
* replication ID and clear the ID2, since there is no valid
* past history. */
changeReplicationId();
clearReplicationId2();
//创建 backlogBuffer
createReplicationBacklog();
}
}
//创建复制积压缓冲区
void createReplicationBacklog(void) {
serverAssert(server.repl_backlog == NULL);
//配置文件配置大小、defult 1M
server.repl_backlog = zmalloc(server.repl_backlog_size);
//实际数据长度
server.repl_backlog_histlen = 0;
//下一次写入命令的的位置
server.repl_backlog_idx = 0;
/* We don‘t have any data inside our buffer, but virtually the first
* byte we have is the next byte that will be generated for the
* replication stream. */
server.repl_backlog_off = server.master_repl_offset+1;
}
即当有一个从机链接到主机的时候,并且发送PSYNC的时候。并且是所有从机共享的一个数据构建。
那么有了这三个要素,再来看下,如果断网了从机是怎么批量同步的、注意这里是断网即断开了和主机的链接、但是数据已然还在!

当从机再次链接上来的时候、发现自己是有主机的信息的、所以发送命令带上runId和offset 上面的代码也是有的!可以回头看下从机发送PSYNC命令的那个代码!
那么主机是如何判断支持部分同步的呢?
回到syncCommand
void syncCommand(client *c) {
//其他代码...
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
// 在这里、这个函数看函数名!
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
} else {
char *master_replid = c->argv[1]->ptr;
/* Increment stats for failed PSYNCs, but only if the
* replid is not "?", as this is used by slaves to force a full
* resync on purpose when they are not albe to partially
* resync. */
if (master_replid[0] != ‘?‘) server.stat_sync_partial_err++;
}
}
//其他代码...
}
int masterTryPartialResynchronization(client *c) {
//其他代码...
/* We still have the data our slave is asking for? */
//这个翻译就是 。我们有从机要的数据!。。。。意思就是我有备份、不用生成RDB!
//backlogBuffer不存在
//或者、传递过来的偏移量 < 当前主机的偏移量 (意思是主机跑的太快了、覆盖了一些数据)
//或者是当前从机比主机跑的还数据还要多
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
{
serverLog(LL_NOTICE,
"Unable to partial resync with replica %s for lack of backlog (Replica request was: %lld).", replicationGetSlaveName(c), psync_offset);
if (psync_offset > server.master_repl_offset) {
serverLog(LL_WARNING,
"Warning: replica %s tried to PSYNC with an offset that is greater than the master replication offset.", replicationGetSlaveName(c));
}
//否则就走全量同步
goto need_full_resync;
}
//其他代码...
//发送在缓冲区的数据
psync_len = addReplyReplicationBacklog(c,psync_offset);
}
我们只看重点代码、一些其他干扰的就去掉了!上面代码可以看了,只在数据还在复制积压缓冲区就不用走全量同步!从机等着接收数据更新Offset即可。
上面修复了断网的情况下~现在又有新情况下!
也没关系~后来作者也针对这种情况做了优化!看图

当从机关机重新的时候、会把当前同步的信息保存到RDB文件中、持久化到磁盘中。等下次重新启动的时候,再给拿回去!这样保证了cached_master数据不会丢失。

当主机变为从机的时候、从机(6380)会做了一件下面有意义的事情即”把原来的repl_id 和 offset 保存到 备份、到replid2和scond_offset“
当之前下线的主机(6379)上线后,变为(6380)的从机。当6379再向6380请求同步数据的时候,带上自己的(原来当主机时候的数据)repliid和offset,再看是主机是如果支持指同步的.再回到函数masterTryPartialResynchronization
void masterTryPartialResynchronization(client *c) {
//其他代码
/* Is the replication ID of this master the same advertised by the wannabe
* slave via PSYNC? If the replication ID changed this master has a
* different replication history, and there is no way to continue.
*
* Note that there are two potentially valid replication IDs: the ID1
* and the ID2. The ID2 however is only valid up to a specific offset. */
//我们说了,当6380被选为主机的时候,备份了原来的 replid 和 offset! 这一点至关重要
if (strcasecmp(master_replid, server.replid) &&
// 因为这里支持了对 replid2的判断,即我还记得你,你之前是我爸爸,但是,你不能比我跑的快、
//不然不好意思、去全量同步我的!
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
/* Run id "?" is used by slaves that want to force a full resync. */
if (master_replid[0] != ‘?‘) {
if (strcasecmp(master_replid, server.replid) &&
strcasecmp(master_replid, server.replid2))
{
serverLog(LL_NOTICE,"Partial resynchronization not accepted: "
"Replication ID mismatch (Replica asked for ‘%s‘, my "
"replication IDs are ‘%s‘ and ‘%s‘)",
master_replid, server.replid, server.replid2);
} else {
serverLog(LL_NOTICE,"Partial resynchronization not accepted: "
"Requested offset for second ID was %lld, but I can reply "
"up to %lld", psync_offset, server.second_replid_offset);
}
} else {
serverLog(LL_NOTICE,"Full resync requested by replica %s",
replicationGetSlaveName(c));
}
goto need_full_resync;
}
}
所以通过以上代码可以得知,从机变主机,为了不忘记原来的主机,保留主机的信息!以便下次来的时候,还能认得你!
所以到这里同步就真的完了!!没有然后了!从上看下来,主机同步做的工作真的很多,每一步走错了都是致命的。本次分析的只是部分代码,还有60%的代码没有分析到!最后还有一个心跳机制要说下!
在命令传播阶段呢,从服务器会以1秒的频率向主机发送 Replication ACK <offset>

作者设计这个目的也是会了增强主从之间的数据一致性、Redis被称为高可用、高性能的服务器,那么对它的加强措施是一点儿也不能松懈!换名话说:如果你能和我一块友好的工作,那么就OK,否则Kill掉你,如果你的网络状态不好,那么不好意思,主机也拒绝写命令!那么这样看来:数据的一致性在这块设计还是赢了一回!
就总结两个点吧、其他还有很多,网上都能找到。那么通过本文的学习我们可以一起考虑以下两点。
Reids尽最大可能保持数据不要丢失。比如:持久化。但在我们刚才讲的换主的情况下 、如果主机执行一个数据,因为命令传播民异步的,那么就有可能失败!如果从机真的失败了,刚好主机又下线了!当失败的从机被选为主机,下线的主机又被配置为从机,那么在同步的时候刚才那条命令就会丢失!因为Reids在保持数据的一致性!
所以Redis最好只能用来做缓存,不要当作真的数据库来用
从上面可以看出来,数据同步是异步的,所以就有可能读写不一致!
那么避免这种情况,网络要好、机器要好、同时Redis的的配置项也能配置的6
本文参考资料redis源码5.0.9
原文:https://www.cnblogs.com/m78-seven/p/15310512.html