有这样一个题,用一条SQL语句 查询出每门课都大于80分的学生姓名。
下面是表
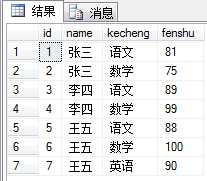
分析,查询每门课程都大于80的学生。SELECT DISTINCT name FROM dbo.student WHERE fenshu<=80查询出来的结果是李四王五张三都有。
小于等于80的语句SELECT name FROM dbo.student WHERE fenshu<=80 只有张三一个。
这个是重复的,值得利用,用not in(不在次语句中的)语句将两句拼写到一块如下:
SELECT DISTINCT name FROM dbo.student WHERE name NOT in(
SELECT name FROM dbo.student WHERE fenshu<=80)
现在只剩下想要的结果了(注意查询出来的结果是三个王五,需要用distinct消除重复行)。
第二个题:删除除了自动编号不同,其他都相同的学生冗余信息,表如下:
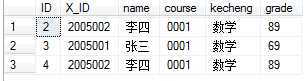
做这道题我们看到ID是不一样的,其他都一样,那么需要分组,语句:SELECT MAX(ID) FROM dbo.student1 GROUP BY grade,kecheng,name,X_ID,course进行分组,并获得最大的ID。在group by语句后的字段必须都一样才会产生一组。
分组后进行删除语句
DELETE FROM dbo.student1 WHERE ID NOT IN(
SELECT MAX(ID) FROM dbo.student1 GROUP BY grade,kecheng,name,X_ID,course)
删除的时候通过Id为条件,不在次条件的语句进行删除,最后得到自己理想的表了。
原文:http://www.cnblogs.com/jiaxuekai/p/4000993.html