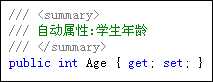
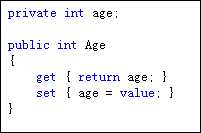
下面两种写法作用相同.前者属于自动属性.在使用自动属性时应该注意:get和set访问器不能有具体的实现.
对于值类型而言,C#规定:在定义变量的同时必须要对其赋初值,否则可能无法通过编译器的编译.但是在某些情况下,用户事先是不知道变量的初始值是多少的.因为可以为空的值类型就显得很重要.
比如,可以为空的int类型:Nullable<int>;可以为空的bool类型:Nullable<bool>
例如:Nullable<int> age = null;
例如: Nullable<int> age = null;等价于int? age = null;
string? name = null; Student? Stu = null;
因为string和Student都是引用类型.
l HasValue:布尔类型,如果字段不为null返回true,否则返回false.
l Value:获取字段的值,如果该字段的值为null,那么调用Value属性会报错
List<T>:T可以指代任何类型,比如:int\bool\string\Student\...
Dictionary<T, K>:字典类,其中T和K可以指代任何类型
KeyValuePair<Tkey, Tvalue>:键值对类型
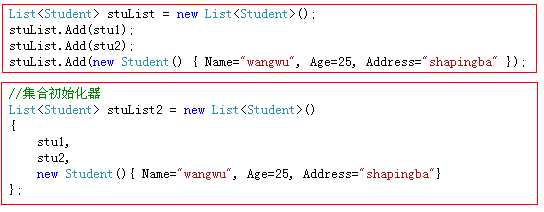
利用对象初始化器,在实例化一个类对象的同时可以为它的属性赋值.

利用集合初始化器,可以在实例化一个集合对象时为它指定元素
var用于定义变量,变量的类型根据值来确定.
var a = 5; 因为5是int类型,所以a的类型也是int
var stu = new Student();因为通过new创建的是Student类型的变量,所以stu是Student类型.
注意1:var b;这种写法是错误的.原因是由var声明的变量,必须在定义的同时就赋初值.
注意2:通过var声明的变量一旦实例化后,就不能再更改它的数据类型.例如下面的代码:
var a = 5; a = “zhangsan”;//a=”zhangsan”报错
在实例化一个类对象时,可以无须事先定义该类,通过new{}即可动态创建类对象.

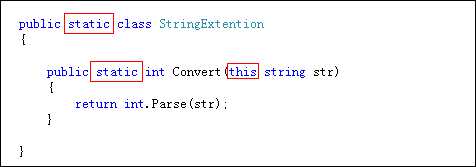
扩展方法是指:为以前定义好的类扩展其他方法.具体步骤如下:
注意: 上面被this关键字修饰的参数的类型就是该扩展方法所扩展的类型
下面的代码演示了如何为string类扩展名称为Convert的无参方法.
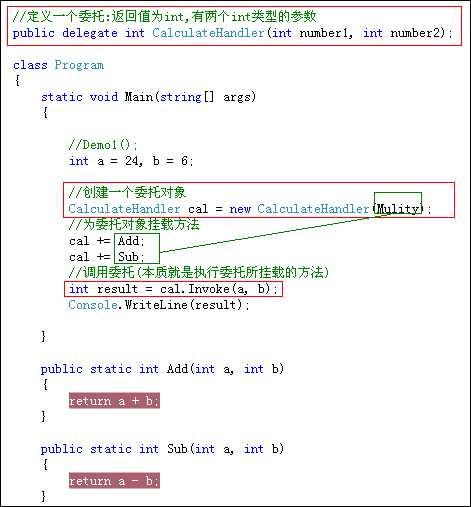
下面的代码演示了如果使用委托计算2个数字的加法\减法\乘法.
委托和挂载的方法:参数个数\参数类型\参数顺序\返回值类型必须要一致.
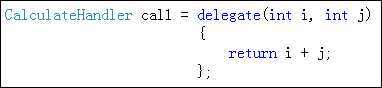
2.但是上述方式,使用很复杂.我们可以通过匿名方法来简写上述功能.=符号右侧的就是匿名方法.
3.Lambda表达式也是匿名方法的一种.并且它的语法更加简洁明了.
Lambda表达式分3部分 : 参数 | => | 表达式
下面的代码演示了如果使用Lambda表达式改写委托的示例.其中3个粉色的线框就是Lambda的3部分.

注意1:如果Lambda表达式只有1个参数,那么参数部分可以不用()包裹
注意2:Lambda表达式部分可以使用{}包裹,也可以不包裹.如果有多行代码,必须要使用{}包裹起来.
4. 在出现委托(Func参数)的地方,我们就可以写Lambda表达式.
Func<T, K>是一个泛型委托.该委托的参数类型为T,返回值类型为K.

Lambda表达式的参数arg的类型为T,Lambda的表达式部分返回值类型为K.
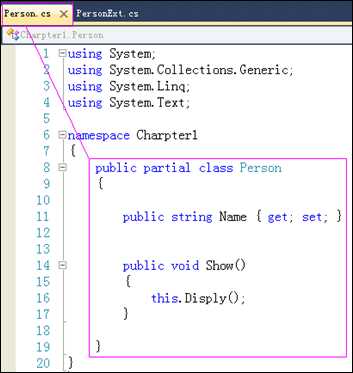
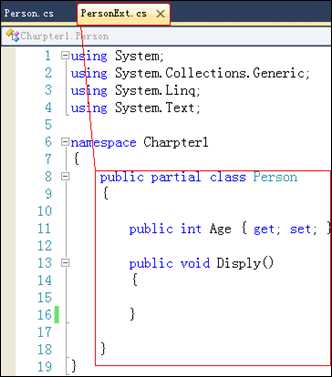
分部类允许将一个类的定义拆分到多个文件中.Winform应用程序和ASP.NET Webform应用程序中的每一个窗体所对应的后台类就采用了分部类技术.
分部类的语法就是:在类声明时,在关键字class前添加partial关键字.
下面的代码将名称为Person的类拆分到了2个类文件中,分别是:Person.cs文件和PersonExt.cs文件.
var data = from 变量 in 集合对象
where 布尔表达式
orderby 排序字段 descending|ascending
select 变量;
解释:
select:提取要查询的数据 where:筛选满足条件的元素
from 变量:该变量指代集合中的单个元素 in:从哪里筛选元素
orderby:排序 descending:降序 ascending:升序
注意:where是可选的,如果不加where则表示筛选所有元素.
示例代码:

数据源(in 后面的集合对象)必须直接或间接继承自IEnumerable<T>
或者说:只要数据源继承自IEnumerable<T>,我们就可以使用Linq从它里面检索数据
筛选满足条件的元素,where关键字后面一定要跟布尔表达式
Where后面的布尔表达式可以很简单,也可以是复杂的表达式.
注意:
注意from关键字后面可以出现多个where表达式,这些表达式之间是并且的关系
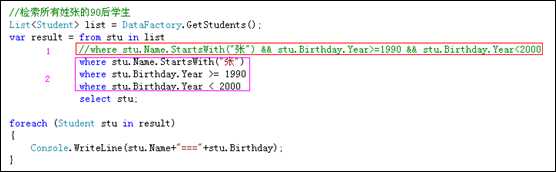
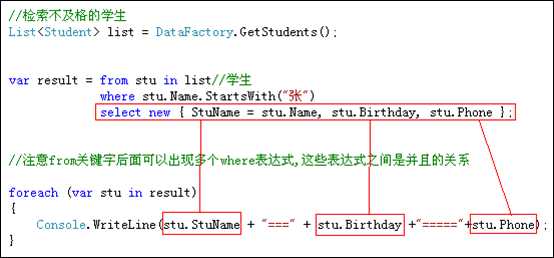
Select关键字用于提取要查询的数据.
Select后面可以直接跟from后面的变量;也可以跟一个匿名类型.
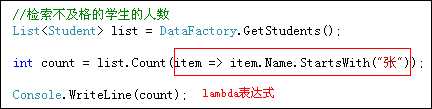
Count(expression<Func<T, bool>>)
解释:T代表Lambda表达式中的参数部分,bool代表Lambda表达式部分为布尔类型
Count方法用于获取满足条件的记录数量(有多少个满足条件的记录)
Max(Expression<Func<T, K>>)和Min(Expression<Func<T, K>>)
Max:求最大值 Min:求最小值

First(Expression<Func<T, bool>>)
FirstOrDefault(Expression<Func<T, bool>>)
两个方法都是从集合中筛选满足条件的第一个元素.
区别:当没有从集合中筛选到满足的条件的元素时,First将会报错,FirstOrDefault则不会报错.

该方法用于计算平均值
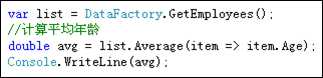
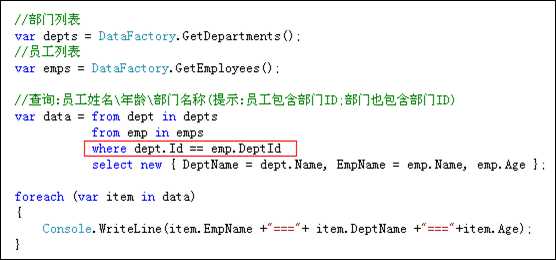
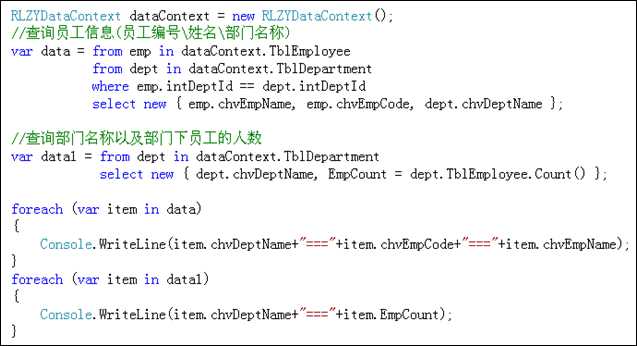
将两个集合进行关联,然后从这两个集合中提取所需要的数据.
语法格式:
var data = from 变量1 in 集合1
from 变量2 in 集合2
where 变量1.属性 == 变量2.属性
select new { ... ...}
提示:可以将N个集合进行关联(N>=2)
示例代码:
Sum(Func<T, K>)
其中T为参数的类型,K为返回值的类型.
Sum()方法用于对数据进行求和运算.
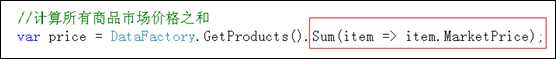
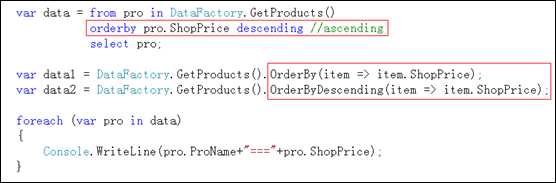
这两个方法用于实现对数据进行排序(升序和降序)
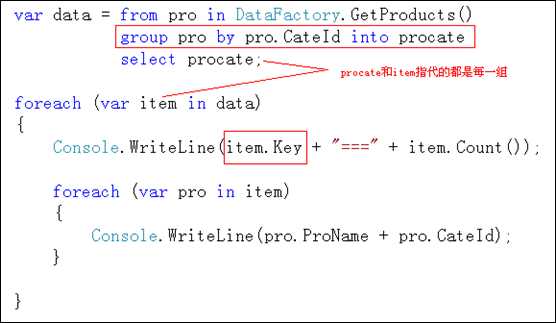
分组的标准语法:
var data = from 变量1 in 集合对象
group 变量1 by 变量1.属性 into 变量2
select 变量2;
注意:使用group by分组后,将不能使用之前的变量1,需要通过into关键字定义一个新的变量2.新的变量指代的是分组后的每一组.
关于分组的示例

一种是使用标准的linq查询语法=>
(from\in\select\where\orderby\ascdening\descending\group\by\into\join);
另一种方案是使用扩展方法=>
(Where\Select\FirstOrDefault\Count\Sum\Average\Max\Min\OrderBy\OrderByDescending\GroupBy\Last\LastOrDefault)
当然,我们也可以将2种混合起来使用.
Intersect:取两个集合的交集 Union:取两个集合的并集
Except:去两个集合的差集 Reverse:反转序列中元素的顺序
ForEach:遍历集合中的元素
Linq是一种数据查询语言(它能够从多种数据源中查询数据). 现在基于Linq的扩展有:
Linq To Sql是一个微软在.NET Framework 3.5中推出的一款ORM(Object Relation Model)实体框架.一个好的实体框架除了能够将数据表映射为实体类,还应该支持使用面向的思想去操纵关系型数据库.现在比较流行的ORM框架包括:Linq To Sql\Entity Framework\Nhibernate等.
我们在使用Linq To Sql的过程中,很少去手写SQL语句就能实现常见的数据增删改差操作.但是它的底层实现仍然是Ado.net.那么如何检测Linq To Sql生成的SQL语句呢?通过DataContext的Log属性即可实现检测功能.
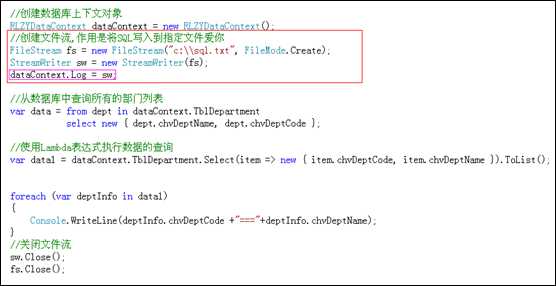
在服务器资源管理器中通过拖拽的方式,将数据表放置到Linq To Sql的设计器区域后,VS会自动将这些数据表生成N+1(N为数据表的个数)个类.这些类大致可以分为2种:一种是数据库上下文,另一种是实体类.数据库上下文类就是名称以DataContext结尾的类,它继承自Sytem.Data.Linq.DataContext.
他们的作用分别是:DataContext类用于和数据库交互(增删改查),每次进行数据库操作时,都应该先创建该类对象;
而每一个实体类则和数据表相对应.
DataContext的特性标记为Database,表示与数据库相关

实体类的特性标记是Table,表示与数据表相关

实体类中属性的特性标记是Column,表示与数据列相关

CreateDatabase():创建数据库
DeleteDatabase():删除数据库
DatabaseExits():判断数据库是否存在
Log:该属性用于检测和写入LINQ TO SQL生成的SQL语句
void InsertOnSubmit():实现每次新增1条记录
void InsertAllOnSubmit():实现一次新增多条记录
注意:调用InsertOnSubmit后,一定要再调用DataContext.SubmitChanges();

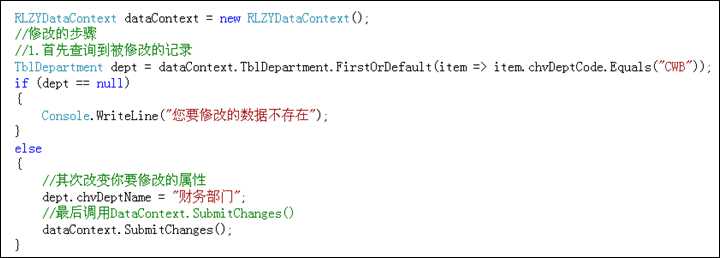
首先,查询到要修改的元素
其次,改变元素相应的属性
最后,调用dataContext.SubmitChanges()
首先,查询到要删除的元素
其次,调用void DeleteOnSubmit()删除单个元素,如果要删除多个可以调用void DelteAllOnSubmit()
最后,调用dataContext.SubmitChanges();

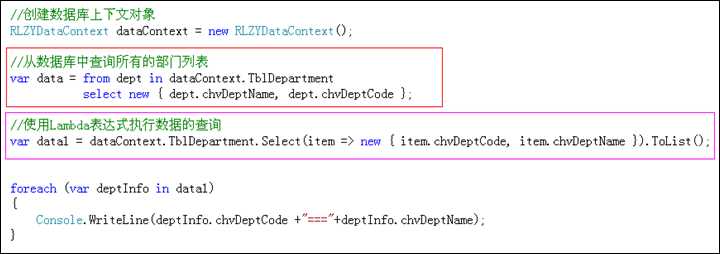
数据查询时,有2种常用的使用方式.一种是使用linq的标准语法;一种是使用Lambda表达式扩展方法.
做法一:
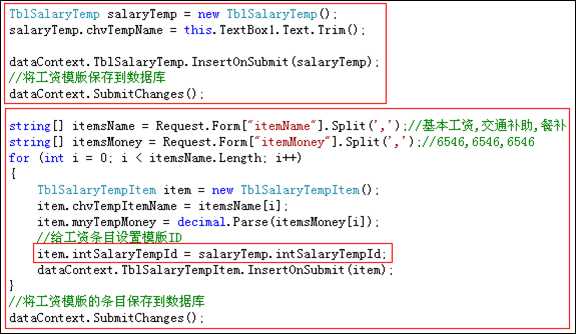
做法二:
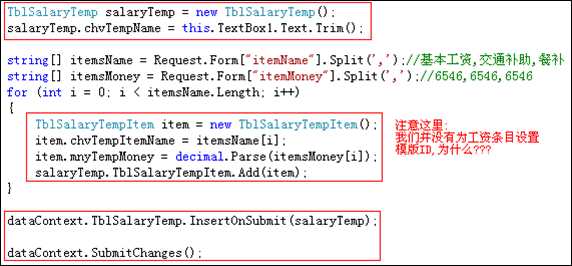
上述两种做法都可以实现功能.做法一是先实现工资模版的新增,然后再新增工资条目.做法二是向工资模版对象中添加多个工资条目,然后向数据库提交工资模版.
需要注意的是,做法一中为工资条目对象设置了工资模版ID,而做法二并没有为工资条目设置工资模版ID.但为什么最后效果却是一样的呢?
因为我们将工资条目添加到工资模版对象中时,linq to sql会自动将主外键关系的字段赋值.
分页功能需要使用两个函数进行组合:Skip()和Take()
Skip(int count):跳过count条数据
Take(int count):从开始位置提取count条记录
分页查询: dataContext.XXX.Skip(pageIndex * pageSize).Take(pageSize)
pageIndex是要提取的第几页记录.pageIndex >= 0
pageSize是每页显示的记录条数
Linq To Sql是ADO.NET的一种替代方案,而ADO.NET属于数据层的范畴,因此应该将Linq To Sql添加到数据层.又因为Linq To Sql生成的类既包括了DataContext,又包括了实体类,所以如果要利用Linq To Sql生成的实体类,就需要将这些实体类剪切到实体层中,然后在向DataContext中添加实体层的引用即可.
当然,我们也可以不将Linq To Sql生成的实体类剪切到实体层中,那么这样我们就需要额外重新编写实体层需要的实体类.
因为InsertOnSubmit方法和DataContext.SubmitChanges()方法都没有任何返回值,所以无法通过他们判断出是否操作成功.判断的标准就是:如果不抛出异常就成功,抛出异常肯定就失败了.
原文:http://www.cnblogs.com/lixunxun/p/4096094.html