[译+改]最长回文子串(Longest Palindromic Substring) Part II
问题:给定字符串S,求S中的最长回文子串。
在上一篇,我们给出了4种算法,其中包括一个O(N2)时间O(1)空间的算法(中心检测法),已经很不错了。本篇将讨论一个O(N)时间O(N)空间的算法,即著名的Manacher算法,并详细说明其时间复杂度为何是O(N)。
先想想有什么办法能改进中心检测法。
考虑一下最坏的情况。★
最坏的情况就是各个回文相互重叠的时候。例如"aaaaaaaaaa"和" cabcbabcbabcba"。
为什么说有重叠时是最坏的情况?因为会发生重复计算。★(换句话说,没有重叠时,必须要一点一点计算,也就没有可改进的余地了。)
花费一些空间来避免重复计算。★
利用回文的特性避免重复计算。★
首先我们把字符串S改造一下变成T,改造方法是:在S的每个字符之间和S首尾都插入一个"#"。这样做的理由你很快就会知道。
例如,S="abaaba",那么T="#a#b#a#a#b#a#"。
想一下,你必须在以Ti为中心左右扩展才能确定以Ti为中心的回文长度d到底是多少。(就是说这一步是无法避免的)
为了改进最坏的情况,我们把各个Ti处的回文半径存储到数组P,用P[i]表示以Ti为中心的回文长度。那么当我们求出所有的P[i],取其中最大值就能找到最长回文子串了。
对于上文的示例,我们先直接写出所有的P研究一下。
|
i = 0 1 2 3 4 5 6 7 8 9 A B C |
|
T = # a # b # a # a # b # a # |
|
P = 0 1 0 3 0 1 6 1 0 3 0 1 0 |
显然最长子串就是以P[6]为中心的"abaaba"。
你是否发现了,在插入"#"后,长度为奇数和偶数的回文都可以优雅地处理了?这就是其用处。
现在,想象你在"abaaba"中心画一道竖线,你是否注意到数组P围绕此竖线是中心对称的?再试试"aba"的中心,P围绕此中心也是对称的。这当然不是巧合,而是在某个条件下的必然规律。我们将利用此规律减少对数组P中某些元素的重复计算。
我们来看一个重叠得更典型的例子,即S="babcbabcbaccba"。

上图展示了把S转换为T的样子。假设你已经算出了一部分P。竖实线表示回文"abcbabcba"的中心C,两个虚实线表示其左右边界L和R。你下一步要计算P[i],i围绕C的对称点是i’。你有办法高效地计算P[i]吗?
我们先看一下i围绕C的对称点i’(此时i’=9)。

据上图所示,很明显P[i]=P[i’]=1。这是因为i和i’围绕C对称。同理,P[12]=P[10]=0,P[14]=P[8]=0。

现在再看i=15处。此时P[15]=P[7]=7?错了,你逐个字符检测一下会发现此时P[15]应该是5。
为什么此时规则变了?

如上图所示,两条绿色实线划定的范围必定是对称的,两条绿色虚线划定的范围必定也是对称的。此时请注意P[i’]=7,超过了左边界L。超出的部分就不对称了。此时我们只知道P[i]>=5,至于P[i]还能否扩展,只有通过逐个字符检测才能判定了。
在此例中,P[21]≠P[9],所以P[i]=P[15]=5。
我们总结一下上述分析过程,就是这个算法的关键部分了。
|
if P[ i‘ ] < R – i, then P[ i ] ← P[ i‘ ] else P[ i ] ≥ R - i. (此时要穿过R逐个字符判定P[i]). |
(注:原作者的写法在逻辑上欠妥,我作了修正)
是不是很优雅?如果你能理解到这里,你已经搞定了这个算法最困难也最精华的部分了。
很明显C的位置也是需要移动的,这个很容易:
|
如果i处的回文超过了R,那么就C=i,同时相应改变L和R即可。 |
每次求P[i],都有两种可能。如果P[i‘] < R – i,我们就P[i] = P[i’]。否则,就从R开始逐个字符求P[i],并更新C及其R。此时扩展R(逐个字符求P[i])最多用N步,而求每个C也总共需要N步。所以时间复杂度是2*N,即O(N)。
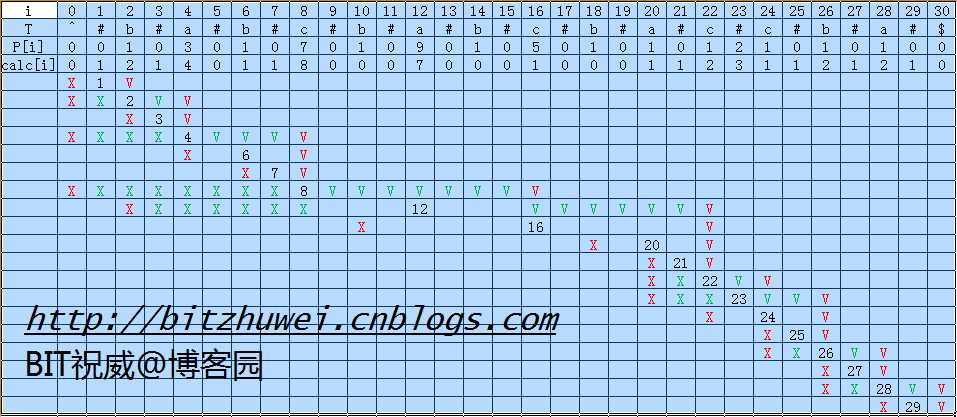
(注:原作者计算时间复杂度的这句话我没看懂。我自己想办法理解了,详情见下图。
图中i为索引,T为加入"#"、"^"和"$"后的字符串,P[i]就是算法里的p[i],calc[i]是为了求出P[i]而需要执行比较的次数。
"V"表示此列的字符与其左侧的字符进行了比较,在左侧用"X"对应。绿色的表示比较结果为两个字符相同(即比较结果为成功),红色的表示不同(即比较结果为失败)。
很显然"X"和"V"的数量是相等的。
你可以看到,所需的成功比较的次数(绿色的"V",表现为横向增长)不超过N,失败的次数(红色的"V",表现为纵向增长)也不超过N,所以这个算法的时间复杂度就是2N,即O(N)。
)
原作者的程序不便于理解,我贴上我的代码。

1 public class Solution { 2 // Transform S into T. 3 // For example, S = "abba", T = "^#a#b#b#a#$". 4 // ^ and $ signs are sentinels appended to each end to avoid bounds checking 5 String preProcess(String s) { 6 int n = s.length(); 7 if (n == 0) return "^$"; 8 9 String ret = "^"; 10 for (int i = 0; i < n; i++) 11 { 12 ret += "#" + s.substring(i, i + 1); 13 } 14 15 ret += "#$"; 16 return ret; 17 } 18 public String longestPalindrome(String s) { 19 String T = preProcess(s); 20 int length = T.length(); 21 int[] p = new int[length]; 22 int C = 0, R = 0; 23 24 for (int i = 1; i < length - 1; i++) 25 { 26 int i_mirror = C - (i - C); 27 int diff = R - i; 28 if (diff >= 0)//当前i在C和R之间,可以利用回文的对称属性 29 { 30 if (p[i_mirror] < diff)//i的对称点的回文长度在C的大回文范围内部 31 { p[i] = p[i_mirror]; } 32 else 33 { 34 p[i] = diff; 35 //i处的回文可能超出C的大回文范围了 36 while (T.charAt(i + p[i] + 1) == T.charAt(i - p[i] - 1)) 37 { p[i]++; } 38 C = i; 39 R = i + p[i]; 40 } 41 } 42 else 43 { 44 p[i] = 0; 45 while (T.charAt(i + p[i] + 1) == T.charAt(i - p[i] - 1)) 46 { p[i]++; } 47 C = i; 48 R = i + p[i]; 49 } 50 } 51 52 int maxLen = 0; 53 int centerIndex = 0; 54 for (int i = 1; i < length - 1; i++) { 55 if (p[i] > maxLen) { 56 maxLen = p[i]; 57 centerIndex = i; 58 } 59 } 60 return s.substring((centerIndex - 1 - maxLen) / 2, (centerIndex - 1 - maxLen) / 2 + maxLen); 61 } 62 }
这个算法是non-trivial的,没人会在面试时要求你给出这么霸气的东西。不过,如果你能读到这里并理解到这里,值得给自己一个大大的奖励了!
实际上还有第六种解决方法:后缀树(suffix tree)。不过其复杂度为O(N log N),构建后缀树也比较费劲,算法实现还比这个复杂。当然它也有其优势:能解决很多类似的问题。我们下回分解。
你可以考虑一下:如何求最长回文子序列(subsequence)?
[译]最长回文子串(Longest Palindromic Substring) Part II
原文:http://www.cnblogs.com/bitzhuwei/p/Longest-Palindromic-Substring-Part-II.html
