【参数化索引及域索引】
考虑查询“ 寻找由WilliamShakespeare于1601年撰写、其中包含短语alaspoorYorick的文 档” 。和通常一样,查询的处理过程需要进行倒排记录表的合并操作,但是不同的是,这里在处 理上述查询时还会涉及到参数化索引(parametric index)上的合并操作。 (每每一个可搜索的参数分别制作一份倒排索引)
域(zone)和字段很相似,只是它的内容可以是任意的自由文本。字段通常的取值可能性 相对较小,而域可以由任意的、数目无限制的文本构成。
参数化索引及域索引的意思是把参数、域直接加入token的倒排索引,如下:
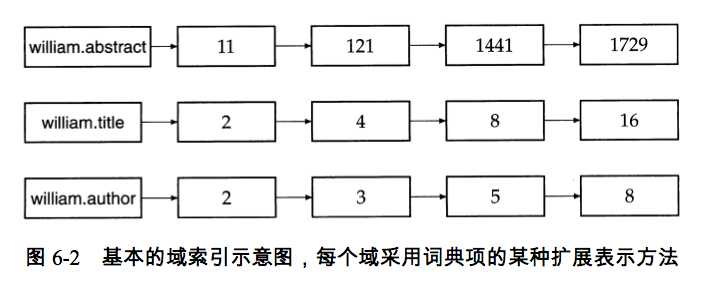
但更普遍的方法是把信息记录在文档属性中。
问题:
1、目前架构中是否支持参数化索引。
【域加权评分】
假定每篇文档有 l 个域,其对应的权重分别是 g1, . . . , gl ∈[0, 1],它们满足 ∑l gi = 1 。令 si 为查询和文档的第 i 个域的匹配得分(1 和 0 分别表示匹配上 i=1
和没匹配上)。例如,在 AND 查询下,如果所有查询词项都出现在某个域中,则这个域的对应得分为 1;否则为 0。实际上,域中查询词项到{0,1}集合的出现关系映射可以是其他任何布尔函数而不只是 AND 函数。于是,域加权评分方法可以定义为:
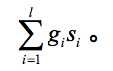
该方法有时也称为排序式布尔检索(ranked Boolean retrieval)。

【权重学习】
人们越来越倾向于从人工标注好的训练数据中学习到这些权重。这种方法属于信息检索中一类被称为机器学习相关性(machine-learned relevance)评分及排序方法的范畴。
1. 给定一批训练样本(training example),每个样本可以表示成一个三元组<查询 q, 文档 d, q 和 d 的相关性判断>。最简单的情况下,相关性判断的结果要么是相关(relevant) 要么是不 相关(nonrelevant)。更细致的方法在实现时会利用更多级别的相关性判断结果。
2.利用上述训练样本集合学习到权重 gi,使得利用这些权重在训练集中计算到的每篇文档 的得分尽量接近事先给出的相关性判断结果。
对于域加权评分来说,上述过程实际上是在学习一个线性函数,它能够组合不同域的布尔 得分结果。这种学习方法中的较高代价主要来自人工进行的相关性判断,这些判断需要消耗大 量人力,尤其在文档集(如 Web)频繁变化的情况下这种代价更大。
【词项频率及权重计算】
首先,我们对于词项 t,根据其在文档 d 中的权重来计算它的得分。最简单的方式是将权重设置 为 t 在文档中的出现次数。这种权重计算的结果称为词项频率(term frequencey),记为 tft,d,其 中的两个下标分别对应词项和文档。
【逆文档频率】
某些词项对于相关度计算来说几乎没有或很少有区分能力。 例如,在一个有关汽车工业的文档集中,几乎所有的文档都会包含 auto,此时,auto就没有区分能力。为此,下面我们提出一种机制来降低这些出现次数过多的词项在相关性计算中的重要 性。一个很直接的想法就是给文档集频率(collection frequency)较高的词项赋予较低的权重, 其中文档集频率指的是词项在文档集中出现的次数。这样,便可以降低具有较高文档集频率的 词项的权重。
原文:http://www.cnblogs.com/tekkaman/p/3575785.html