首先要知道一个概念selectivit--选择性。选择性是一个row source中可能返回的row的多少。比如一个100行的表,经过查询返回48行,那么selectivity就是0.48。 selectivity对CBO的判断非常重要,简单的说,如果selectivity很大,返回的row占row source的大部分,CBO就倾向于用全表扫描来访问表,反之则倾向于index扫描。
为了计算selectivity,CBO需要提前知道一些统计信息以及设置一些初始化参数。相对表的一列来说,CBO需要以下statistics来计算selectivity:
如果没有histogram信息,CBO就用前三种信息来判断选择性,这时候CBO会认为该列的值的分布是均匀的。也就是在low 和 high值之间,所有的distinct值都是相等的。我们来看一个例子:(这里的10000是字符 正常的测试应该是数字。但是字符和数字的表现不一样。这个值得研究)

SQL> create table test as select rownum all_distinct, ‘10000‘ skew from dual connect by level <= 10000; SQL> update test set skew=all_distinct+10 where rownum<=10; SQL> select * from test where rownum<12; ALL_DISTINCT SKEW ------------ --------------- 1 11 2 12 3 13 4 14 5 15 6 16 7 17 8 18 9 19 10 20 11 10000 11 rows selected.
然后我们手机一下统计信息,要注意的是这里没有收集histogram的信息
exec dbms_stats.gather_table_stats(‘SYS‘,‘TEST‘, method_opt=>‘for all columns size 1‘);
然后我们看一下收集到的统计信息
SQL> select column_name,num_distinct,LOW_VALUE,HIGH_VALUE,NUM_NULLS,density from user_tab_col_statistics where table_name=‘TEST‘; COLUMN_NAME NUM_DISTINCT LOW_VALUE HIGH_VALUE NUM_NULLS DENSITY ------------------ ------------ ------------------ ------------------ ---------- ---------- ALL_DISTINCT 10000 C102 C302 0 .0001 SKEW 11 3130303030 3230202020 0 .090909091
因为我们没有收集histogram信息,所以这里的density的计算方式就是1/NUM_DISTINCT。
让我们看一下这种情况下CBO做出的执行计划
SQL> select /*+ gather_plan_statistics */ * from test where skew=12; ALL_DISTINCT SKEW ------------ --------------- 2 12 SQL> select * from TABLE(dbms_xplan.display_cursor(null,null,‘iostats last‘)); ------------------------------------------------------------------------------------ | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------ | 0 | SELECT STATEMENT | | 1 | | 1 |00:00:00.01 | 25 | |* 1 | TABLE ACCESS FULL| TEST | 1 | 909 | 1 |00:00:00.01 | 25 |
E-Rows是CBO认为会返回的rows数量,因为没有收集直方图信息,oracle认为数据是均匀分布的。所以cardinality = density * 10000 = 909.09 rows。 再看一个执行计划。
SQL> explain plan for select * from test where skew=10000; Explained. SQL> select * from table(dbms_xplan.display()); -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 909 | 8181 | 7 (15)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TEST | 909 | 8181 | 7 (15)| 00:00:01 | --------------------------------------------------------------------------
这里也是一样,即使是skew=10000,oracle也认为会返回909条row。所以如果有索引,oracle就不能正确的使用索引。比如:
SQL> create index test_indx on test(skew); SQL> exec dbms_stats.gather_index_stats(‘SYS‘,‘TEST_INDX‘); SQL> explain plan for select * from test where skew=10000; SQL> select * from table(dbms_xplan.display()); -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 909 | 8181 | 7 (15)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TEST | 909 | 8181 | 7 (15)| 00:00:01 | -------------------------------------------------------------------------- SQL> explain plan for select * from test where skew=11; SQL> select * from table(dbms_xplan.display()); -------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 909 | 8181 | 7 (15)| 00:00:01 | |* 1 | TABLE ACCESS FULL| TEST | 909 | 8181 | 7 (15)| 00:00:01 | --------------------------------------------------------------------------
所以,没有histogram的时候,oracle会认为一列中的数据是均匀分布的。很难做出正确的选择。
那么在有histogram的情况下会是什么样呢?oracle的histogram会告诉CBO一列长数据的真正分布。比如在上面的例子中,histogram会告诉CBO,skew=11只有一条,而skew=10000有9990条。这样oracle就能够做出正确的选择了。
oracle的histogram有两种,一种叫宽度平衡直方图(频率直方图),另一种叫高度均衡直方图。我们来仔细看一下这两种直方图。
width-blanced or frequence histogram
这种直方图的x轴是distinct value,y轴是对应distinc value在列中出现的次数。这种直方图的前提就是x轴能够涵盖所有的distinct value。oracle histogram的bucket最大值是254.也就是说一个column如果它的distinct值不超过254个,我们就可以使用这种直方图。下图是我们例子的频率直方图
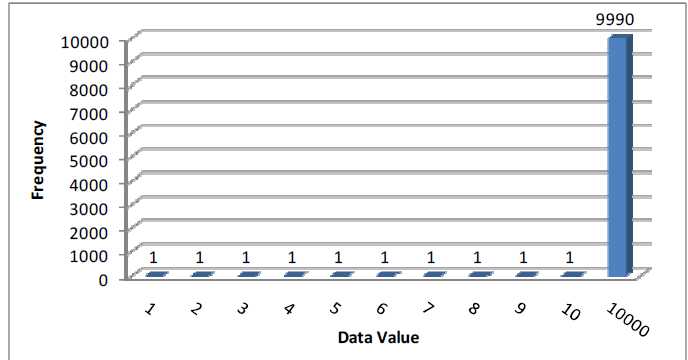
我们先创建一个频率直方图然后看一下这个直方图在数据字典中是怎样存储的。
exec dbms_stats.gather_table_stats(‘SYS‘,‘TEST‘,method_opt=>‘for columns skew size 11‘);
原文:http://www.cnblogs.com/kramer/p/3578521.html