复制连接是map端的连接。复制连接得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点。复制连接有一个假设前提:在被连接的数据集中,有一个数据集足够小到可以缓存在内存中。
如图4.5所示,MapReduce的复制连接的工作原理如下:
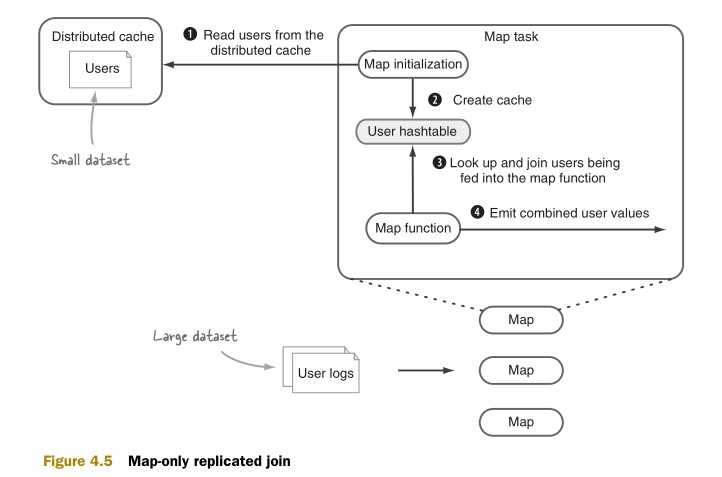
复制连接的实现非常直接明了。更具体的内容可以参考《Hadoop in Action》。附录D提供了一个通用的框架来实现复制连接。这个框架支持任意类型的InputFormat和OutputFormat的数据。(我们将在下一个技术中使用这个框架。)复制连接框架根据内存足迹的大小从分布式缓存的内容和输入块(input split)两者中动态地决定需要缓存的对象。
如果所有的输入数据集都不能够小到可以放到缓存中,那有没有办法来优化map端连接呢?那就到了看半连接(semi-join)的时间了。
复制连接是map端连接,得名于它的具体实现:连接中最小的数据集将会被复制到所有的map主机节点。复制连接的实现非常直接明了。更具体的内容可以参考Chunk Lam的《Hadoop in Action》。
这个部分的目标是:创建一个可以支持任意类型的数据集的通用的复制连接框架。这个框架中同样提供了一个优化的小功能:动态监测分布式缓存内容和输入块的大小,并判断哪个更大。如果输入块较小,那么你就需要将map的输入块放到内存缓冲中,然后在mapper的cleanup方法中执行连接操作了。
图D.4是这个框架的类图,这里我提供了连接类( GenericReplicatedJoin)的具体实现,而不仅仅是一个抽象类。在这个框架外,这个类将和KeyValueTextInputFormat及 TextOutputFormat协作。这里有一个假设前提:每个数据文件的第一个标记是连接键。此外,连接类也可以被继承扩展来和任意类型的输入和输出。
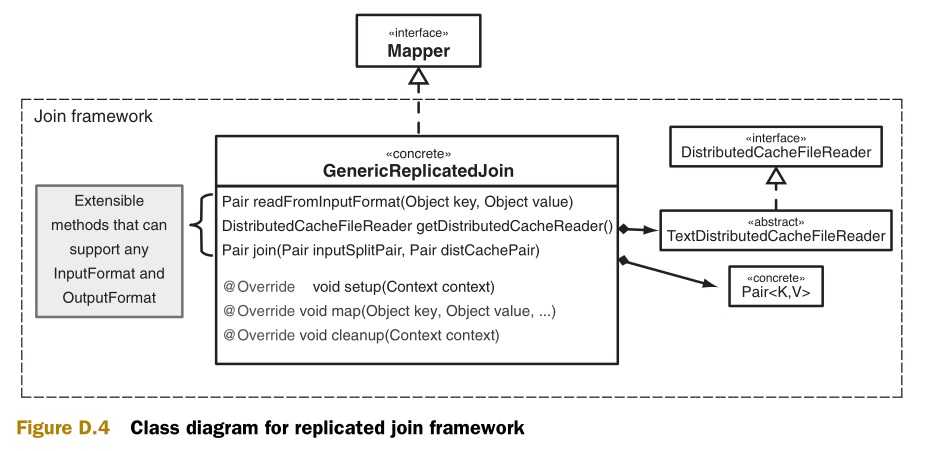
图D.5是连接框架的算法。Mapper的setup方法判断在map的输入块和分布式缓存的内容中哪个大。如果分布式缓存的内容比较小,那么它将被装载到内存缓存中。Map函数开始连接操作。如果输入块比较小,map函数将输入块的键\值对装载到内存缓存中。Map的cleanup方法将从分布式缓存中读取记录,逐条记录和在内存缓存中的键\值对进行连接操作。

以下代码的GenericReplicatedJoin中的setup方法是在map的初始化阶段调用的。这个方法判断分布式缓存中的文件和输入块哪个大。如果文件比较小,则将文件装载到HashMap中。

1 @Override 2 protected void setup(Context context) 3 throws IOException, InterruptedException { 4 5 distributedCacheFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration()); 6 int distCacheSizes = 0; 7 8 for (Path distFile : distributedCacheFiles) { 9 File distributedCacheFile = new File(distFile.toString()); 10 distCacheSizes += distributedCacheFile.length(); 11 } 12 13 if(context.getInputSplit() instanceof FileSplit) { 14 FileSplit split = (FileSplit) context.getInputSplit(); 15 long inputSplitSize = split.getLength(); 16 distributedCacheIsSmaller = (distCacheSizes < inputSplitSize); 17 } else { 18 distributedCacheIsSmaller = true; 19 } 20 21 if (distributedCacheIsSmaller) { 22 for (Path distFile : distributedCacheFiles) { 23 File distributedCacheFile = new File(distFile.toString()); 24 DistributedCacheFileReader reader = getDistributedCacheReader(); 25 reader.init(distributedCacheFile); 26 27 for (Pair p : (Iterable<Pair>) reader) { 28 addToCache(p); 29 } 30 31 reader.close(); 32 } 33 } 34 }
Map方法将会根据setup方法是否将了分布式缓存的内容装载到内存的缓存中来选择行为。如果分布式缓存的内容被装载到内存中,那么map方法就将输入块的记录和内存中的缓存做连接操作。如果分布式缓存的内容没有被装载到内存中,那么map方法就将输入块的记录装载到内存中,然后在cleanup方法中使用。
1 @Override 2 protected void map(Object key, Object value, Context context) 3 throws IOException, InterruptedException { 4 Pair pair = readFromInputFormat(key, value); 5 6 if (distributedCacheIsSmaller) { 7 joinAndCollect(pair, context); 8 } else { 9 addToCache(pair); 10 } 11 } 12 13 public void joinAndCollect(Pair p, Context context) 14 throws IOException, InterruptedException { 15 List<Pair> cached = cachedRecords.get(p.getKey()); 16 17 if (cached != null) { 18 for (Pair cp : cached) { 19 Pair result; 20 21 if (distributedCacheIsSmaller) { 22 result = join(p, cp); 23 } else { 24 result = join(cp, p); 25 } 26 27 if (result != null) { 28 context.write(result.getKey(), result.getData()); 29 } 30 } 31 } 32 } 33 34 public Pair join(Pair inputSplitPair, Pair distCachePair) { 35 StringBuilder sb = new StringBuilder(); 36 37 if (inputSplitPair.getData() != null) { 38 sb.append(inputSplitPair.getData()); 39 } 40 41 sb.append("\t"); 42 43 if (distCachePair.getData() != null) { 44 sb.append(distCachePair.getData()); 45 } 46 47 return new Pair<Text, Text>( 48 new Text(inputSplitPair.getKey().toString()), 49 new Text(sb.toString())); 50 }
当所有的记录都被传输给map方法,MapReduce将会调用cleanup方法。如果分布式缓存的内容比输入块大,连接将会在cleanup中进行。连接的对象是map函数的缓存中的输入块的记录和分布式缓存中的记录。
1 @Override 2 protected void cleanup(Context context) 3 throws IOException, InterruptedException { 4 5 if (!distributedCacheIsSmaller) { 6 7 for (Path distFile : distributedCacheFiles) { 8 File distributedCacheFile = new File(distFile.toString()); 9 DistributedCacheFileReader reader = getDistributedCacheReader(); 10 reader.init(distributedCacheFile); 11 12 for (Pair p : (Iterable<Pair>) reader) { 13 joinAndCollect(p, context); 14 } 15 16 reader.close(); 17 } 18 } 19 }
最后,任务的驱动代码必须指定需要装载到分布式缓存中的文件。以下的代码可以处理一个文件,也可以处理MapReduce输入结果的一个目录。
1 Configuration conf = new Configuration(); 2 3 FileSystem fs = smallFilePath.getFileSystem(conf); 4 FileStatus smallFilePathStatus = fs.getFileStatus(smallFilePath); 5 6 if(smallFilePathStatus.isDir()) { 7 for(FileStatus f: fs.listStatus(smallFilePath)) { 8 if(f.getPath().getName().startsWith("part")) { 9 DistributedCache.addCacheFile(f.getPath().toUri(), conf); 10 } 11 } 12 } else { 13 DistributedCache.addCacheFile(smallFilePath.toUri(), conf); 14 }
这个框架假设分布式缓存的内容和输入块的内容都可以被装载到内存中。这个框架的优点在于它只会将两者之中较小的装载到内存中。
在论文《A Comparison of Join Algorithms for Log Processing in MapReduce》中,你可以看到这个方法对于分布式缓存内容较大时的更进一步的优化。在他们的优化中,他们将分布式缓存分成N个分区,并将输入块放入N个哈希表。这样在cleanup方法中的优化就更加高效。
在map端的复制连接的问题在于,map任务必须在启动时读取分布式缓存。上述论文提到的另一个优化方案是重载FileInputFormat的splitting。将存在于同一个主机上的输入块合并成一个块。然后就可以减少需要装载分布式缓存的map任务的个数了。
最后一个说明,Hadoop在org.apache.hadoop.mapred.join包中自带了map端的连接。但是它需要有序的待连接的数据集的输入文件,并要求将其分发到相同的分区中。这样就造成了繁重的预处理工作。
[大牛翻译系列]Hadoop Mapreduce 连接(Join)之二:复制连接(Replication join),布布扣,bubuko.com
[大牛翻译系列]Hadoop Mapreduce 连接(Join)之二:复制连接(Replication join)
原文:http://www.cnblogs.com/datacloud/p/3579333.html