在爬虫系统中,在内存中维护着两个关于URL的队列,ToDo队列和Visited队列,ToDo队列存放的是爬虫从已经爬取的网页中解析出来的即将爬取的URL,但是网页是互联的,很可能解析出来的URL是已经爬取到的,因此需要VIsited队列来存放已经爬取过的URL。当爬虫从ToDo队列中取出一个URL的时候,先和Visited队列中的URL进行对比,确认此URL没有被爬取后就可以下载分析来。否则舍弃此URL,从Todo队列取出下一个URL继续工作。
然后,我们知道爬虫在爬取网页时,网页的量是比较大的,直接将所有的URL直接放入Visited队列是很浪费空间的。因此引入bloom filter!
我们把bloom filer设置为m个bit,全部初始为0。
对每一个URL,进行K(K<m)次相互独立的哈希,一共得到K个值,将这K个值在bloom filter中对应的bit位置1。
经过上述处理的bloom filter实际上构成了我们所说的Visited队列,当我们从ToDo队列中取出一个新的URL时,同样,进行相同的K次哈希,每进行一次哈希,查看bloom filter中对应位,只要发现某位是0,就可以确定这个URL是没有处理过的,可以继续下载处理。
那么,原理清楚之后,还有几个问题没有解决。
1、bloom filter是有可能发生错误的,因为不处理碰撞,也就是说,有可能把不属于这个集合的元素误认为属于这个集合
错误率的计算:
在n个URL都进行k次散列加入之后,bloomfilter中某位是0的概率
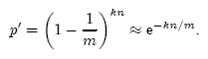
错误率(即一个新的URL恰好k次散列的值对应的位都已经是1的概率)
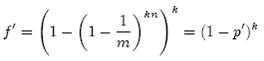
2、哈希函数个数K的确定
k = ln2· (m/n)时(具体数学分析见http://blog.csdn.net/jiaomeng/article/details/1495500)
3、bloomfilter位数M的确定
我们可以想到,M的大小越大,错误率就会越小,但是数学证明给出了一个下界。即M = log2 e N = 1.44N。
爬虫技术之——bloom filter,布布扣,bubuko.com
原文:http://www.cnblogs.com/qingdu/p/3583417.html