iBatis可以使用xml来作为参数输入以及结果返回;这个功能的优势在于某些特定的场景;还有可以通过DOM方式来作为参数传递;但是这个方式应用的比较少,如果服务器是xml服务器可以采用这种方式;
对于海量数据,如果一次性就加载可能比较麻烦,这里就需要一些技术来对返回信息进行控制,LazyLoad技术大家都比较清楚,只有需要的时候再从DB中取值;iBatis里面支持LazyLoad,但是LazyLoad的设置是全局性质的,groupby的实现则实现了针对单个操作层面上的配置;无论是LazyLoad还是groupby的实现方式都是查询后,将结果缓存,其他深层次查询的时候还是获得这个对象,通过存取这个对象的属性来实现深度查询(所谓深度查询是指相对于父查询的子查询)。但是有一点,对于lazyloader而言,如果想要加载全部数据效率是比普通查询是要低很多的(因为需要多次访问数据库,增加IO);
rowHandler技术和C#里面的DataReader很像了,iBatis里面的实现机制每当取到一条记录后都会走RowHandler的handleRow的方法,如果你实现了这个类的方法,就可以对该数据进行操作;rowhandler的一大优势就是数据操作完之后就释放,不会占用内存,这一点和LazyLoader以及groupby是不一样的;
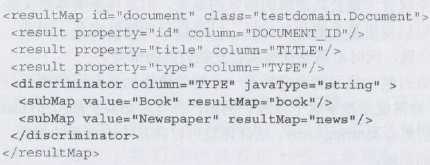
鉴别器的作用在于如果一个查询里面要么是图书类,要么是新闻类,当然作为父容器可能是"书店类"(图书类和新闻类字段不一样),这样可以通过鉴别器的配置自动将字段匹配到对应的类型上面去;如下图所示:

iBatis支持存储过程,以及输入时输出参数,要考虑到存储过程的快捷性。尽管存储过程违背了"一次编译,到处运行",但是在提供性能方面很多时候拥有者绝对优势,比如,有的操作需要通过建立多次交互才能实现,但是使用存储过程一次就搞定了(比如判断是否重复,重复就更新,不重复就插入);
批量更新
iBatis提供了批量更新,批量更新多半都是伴随着事务一起的,批量的优势和存储过程有些类似,操作集中在一次完成;批量更新与一个缺点:无法再insert之后就立即返回自动生成主键,如果主键是自动生成的话;还包括其他的值,比如如果两个操作具有依赖性,后面的操作(sql执行)依赖于前一个操作的返回值(返回到应用层),因为批处理是整合完毕后一次性的提交数据库处理。如果是相互依赖就是用存储过程来处理吧;
处理并发这个专题iBatis并没有做处理,作为数据层一个共同的问题一般都是使用更新操作外带全家桶(时间戳、版本)的方式来进行处理;
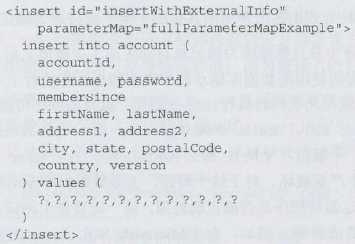
外部参数:

内联参数:就是SQL文中通过#...#或者$...$的方式占位的形式
经过测试外部参数只能是通过有序的"?"来进行,无法在使用声明名称的方式(内联形式),根据iBatis的本意是在insert等操作中内联参数还需要指定类型,通过定义外联方式可以一次性制定好类型,方便重用,但是问题是重用的先决条件是SQL参数次序要保持一致,其次呢,实际应用中,即使不指定类型也是可以顺利插入/更新;所以外部参数被使用的不多。
?
?
?
?
?
?
?
原文:http://www.cnblogs.com/xiashiwendao/p/4280093.html