搭建hadoop源代码调试环境
本文介绍以下在hadoop伪分布式环境下如何利用Eclipse调试hadoop源代码
1、安装搭建hadoop伪分布式
笔者在上一篇博文中介绍过如果搭建hadoop伪分布式,这一步可以参考上文。
2、下载配置ant
可以到http://ant.apache.org/bindownload.cgi下载最新版本的ant,下载解压后,需要将ant的bin目录添加到PATH的环境变量上。
在ubuntu下可以:
root@ubuntu:#nano /etc/profile
在打开的文件末尾添加ant的bin目录:
export ANT_HOME=/usr/local/ant
然后保存退出后执行以下命令使之立即生效:
root@ubuntu:#. /etc/profile
(注意.后面有空格)
3、利用ant下载依赖和编译文件
进入到hadoop的安装目录下执行$ant
root@ubuntu:#cd $HADOOP_HOME
root@ubuntu:/usr/local/hadoop/hadoop-0.20.2/# ant
此时,ant开始下载依赖和编译文件。
在编译的时候可能遇到编译错误的情况。经查,是$hadoop_home/src/saveVersion.sh生成的package-info.java有问题,导致无法编译过去。将saveVersion.sh修改一下:

nset LANG unset LC_CTYPE version=$1 user=`whoami` #此处修改成固定值,如jbm3072 date=`date` if [ -d .git ]; then revision=`git log -1 --pretty=format:"%H"` hostname=`hostname` branch=`git branch | sed -n -e ‘s/^* //p‘` url="git://$hostname/$cwd on branch $branch" else revision=`svn info | sed -n -e ‘s/Last Changed Rev: \(.*\)/\1/p‘` url=`svn info | sed -n -e ‘s/URL: \(.*\)/\1/p‘` fi mkdir -p build/src/org/apache/hadoop cat << EOF | \ sed -e "s/VERSION/$version/" -e "s/USER/$user/" -e "s/DATE/$date/" \ -e "s|URL|$url|" -e "s/REV/$revision/" \ > build/src/org/apache/hadoop/package-info.java /* * Generated by src/saveVersion.sh */ @HadoopVersionAnnotation(version="VERSION", revision="REV", user="USER", date="DATE", url="URL") package org.apache.hadoop; EOF
修改后,应该就可以编译通过了。
4、将eclipse-files copy到工程目录下。
执行命令:
ant eclipse-files
就可以将eclipse-files copy到工程目录下。
5、创建eclipse项目
打开Eclipse的Fiile->New->Java Project,创建一个新的Java项目,选择项目的位置为Hadoop的安装目录,然后Finish就完成了Eclipse的hadoop源码项目。
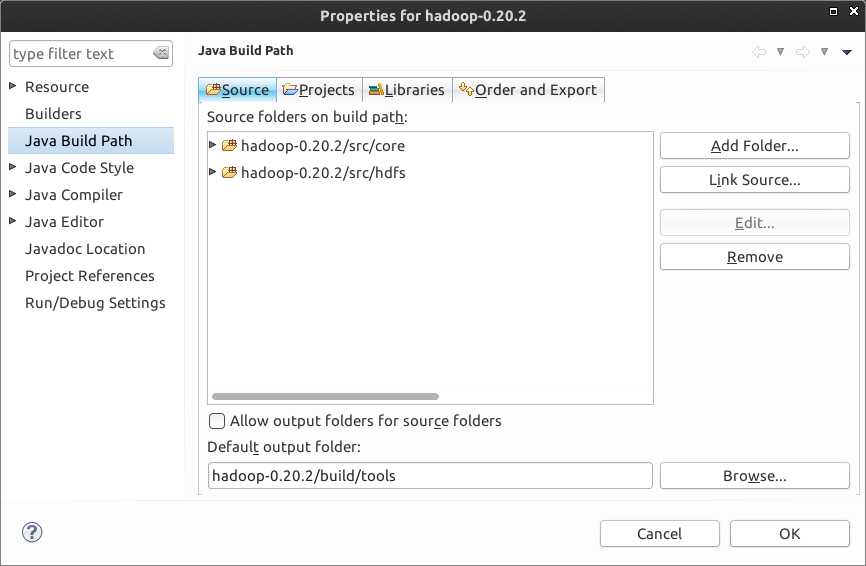
整个hadoop项目代码量太大,有时候,你只关心hadoop的某几个模块,则可以在Build
Path配置下的Source页删除不需要的模块,只保留自己需要的模块,例如笔者 只需要分析Common和HDFS两个模块,则仅需要保留core和hdfs目录就可以了。
6、远程调试Hadoop源代码
(1)
为了不影响原文件,将hadoop/bin目录下的hadoop脚本复制一份
root@ubuntu:/usr/local/hadoop/hadoop-0.20.2/bin# cp
hadoop hadoop-debug
(2)
在hadoop-debug脚本最后一行进行如下改动:
#exec "$JAVA" $JAVA_HEAP_MAX $HADOOP_OPTS -classpath "$CLASSPATH" $CLASS "$@" exec "$JAVA" -Xdebug -Xrunjdwp:transport=dt_socket,address=9090,server=y,suspend=y $JAVA_HEAP_MAX $HADOOP_OPTS -classpath "$CLASSPATH" $CLASS "$@"
以后在需要调试hadoop的某个操作的时候,使用hadoop-debug进行操作,此时该操作会挂起,等待调试连接9090端口。在不需要调试时,使用hadoop操作则不会在 9090端口挂起
(3)例子
以上传文件到hdfs文件系统命令为例
root@ubuntu:/usr/local/hadoop/hadoop-0.20.2/bin#
sh hadoop-debug fs -put /home/tmp.avi /home/
Listening for
transport dt_socket at address:
9090
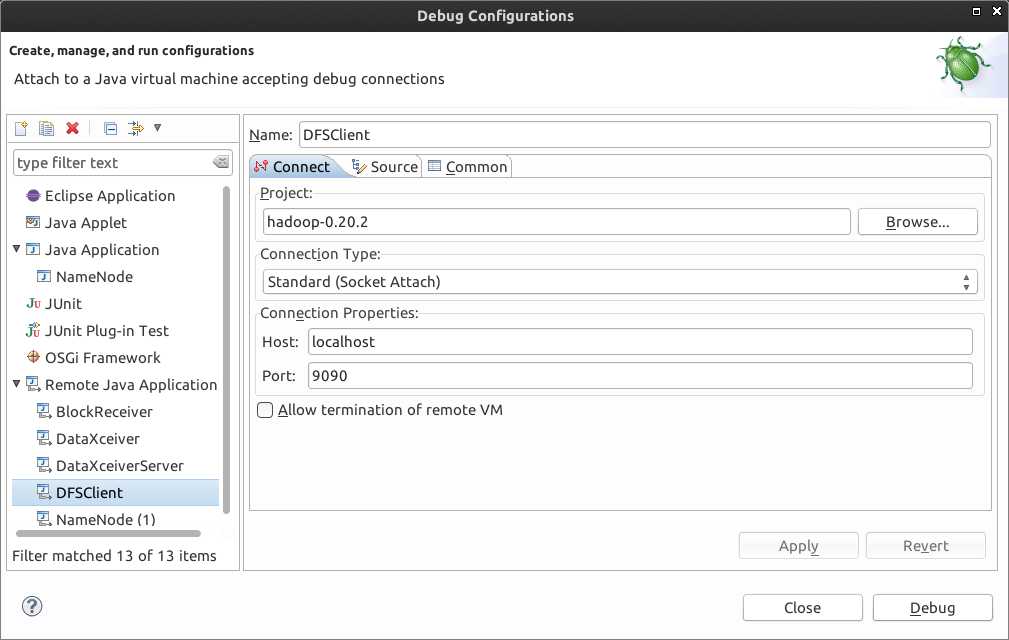
该命令此时在9090端口等待调试连接,这时候打开eclipse的hadoop项目,选中org.apache.hadoop.hdfs包的DFSClient.java文件右键->debug
as ->debug
configrue进入调试配置窗口,填入如下信息:
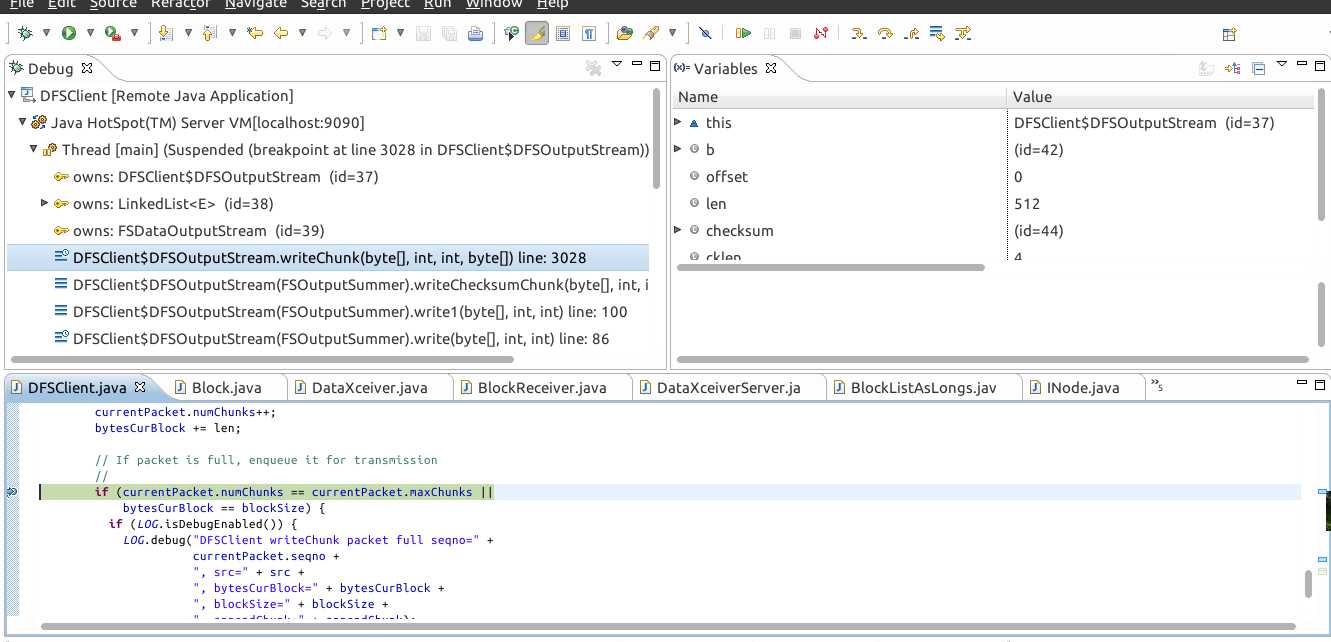
并在你需要设置断点的地方设置断点,再点击Debug,这时候命令就会跳到断点的地方并查看变量的值了,如图:
终
搭建hadoop源代码调试环境,布布扣,bubuko.com
原文:http://www.cnblogs.com/ttblog/p/3585329.html