第一个MR程序是实现关系型数据库中经常都会遇到的表连接操作,也就是join。这里是连接sales和accounts表,通过共同的ID列进行连接。同时统计出总的购买件数以及总的消费额。
下面是两个示例数据,一个是sales.txt,另一个是accounts.txt。
首先是sales.txt:
001 35.99 2012-03-15
002 12.49 2004-07-02
004 13.42 2005-12-20
003 499.99 2010-12-20
001 78.95 2012-04-02
002 21.99 2006-11-30
002 93.45 2008-09-10
001 9.99 2012-05-17
然后是accounts.txt:
001 John Allen Standard 2012-03-15
002 Abigail Smith Premium 2004-07-13
003 April Stevens Standard 2010-12-20
004 Nasser Hafez Premium 2001-04-23
这段程序的具体思想是由MR两个部分来分开连接的过程。首先用两个mapper(SalesRecordMapper&AccountsRecordMapper)来分别对两个数据文件进行处理,生成类似(001,sales 35.99)以及(001,accounts John Allen)的键值对。然后通过一个shuffle的过程,生成类似(001,sales 35.99,sales 78.95...)的键值对,然后传送到ReduceJoinReducer中进行循环处理。这就是整个程序的处理过程。我们还可以根据这个程序改写出适应其他情况的程序。
import java.io.* ;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs ;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat ;
public class ReduceJoin
{
public static class SalesRecordMapper
extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException
{
String record = value.toString() ;
String[] parts = record.split("\t") ;
context.write(new Text(parts[0]), new Text("sales\t"+parts[1])) ;
}
}
public static class AccountRecordMapper
extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException
{
String record = value.toString() ;
String[] parts = record.split("\t") ;
context.write(new Text(parts[0]), new Text("accounts\t"+parts[1])) ;
}
}
public static class ReduceJoinReducer
extends Reducer<Text, Text, Text, Text>
{
public void reduce(Text key, Iterable<Text> values,
Context context
) throws IOException, InterruptedException
{
String name = "" ;
double total = 0.0 ;
int count = 0 ;
for(Text t: values)
{
String parts[] = t.toString().split("\t") ;
if (parts[0].equals("sales"))
{
count++ ;
total+= Float.parseFloat(parts[1]) ;//sales取出并求和
}
else if (parts[0].equals("accounts"))
{
name = parts[1] ;//accounts取出作为name
}
}
String str = String.format("%d\t%f", count, total) ;
context.write(new Text(name), new Text(str)) ;
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Reduce-side join");
job.setJarByClass(ReduceJoin.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, SalesRecordMapper.class) ;
MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, AccountRecordMapper.class) ;
// FileOutputFormat.setOutputPath(job, new Path(args[2]));
Path outputPath = new Path(args[2]);
FileOutputFormat.setOutputPath(job, outputPath);
outputPath.getFileSystem(conf).delete(outputPath);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
到这里。已经准备好东西。可以开始运行。
首先是编译,这里使用命令:javac -classpath /home/leung/hadoop1/hadoop-core-1.2.1.jar ReduceJoin.java进行编译,也可以在path文件中指定类路径。这里编译这个程序只需要加载hadoop的核心包即可。其他情况可不一定哦~(是要根据import的包来决定的)。
然后是打成jar包。jar -cvf join.jar *.class 。最后是运行:hadoop jar join.jar ReduceJoin sales.txt accounts.txt output。最后就可以查看结果啦!
我运行的结果如下:
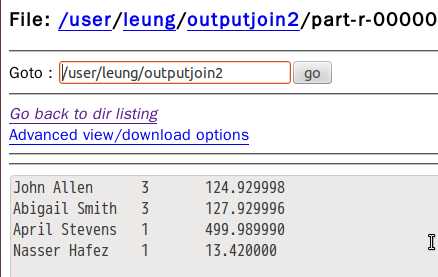
OK!下次再见!
学习的一个MapReduce程序(《beginner`s guide》中的例子)
原文:http://www.cnblogs.com/UUhome/p/4293545.html