这个东西应该有用,所以前段时间就尝试在自己笔记本上实验一下,结果始终没成功。
昨天回来路上想,是该做点儿事情,遂想起了这事。
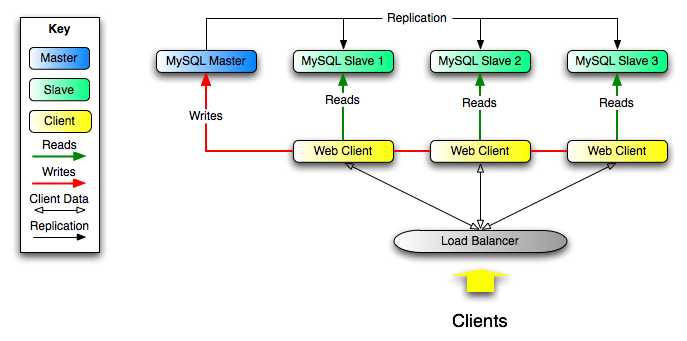
初步理解就是:master数据库有相应的操作时,会记录到一个binaery_log里,然后slave去读取这个log,然后再在自己的数据库中进行相应的操作,从而达到同步。当然这个同步会有时间延迟。
配置:
在master和slave两端都需要对数据库的配置文件进行修改
master
server-id=1
auto-increment-increment=2
auto-increment-offset=1
log-bin=binary_log
binlog-do-db=同步数据库
slave
master-host=master ip
master-user=对应在master上的用户名
master-password=用户密码
replicate-do-db=同步数据库
在master上创建一个slave的用户注意这个slave用户需要有一定的权限
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO ’slave’@’slave ip′ IDENTIFIED BY ’slave’;
然后重启一下master的服务(FLUSH PRIVILEGES;也可以吗?),show master status; 记录一下相应的log文件和position
接着stop slave,change master to master_host=’master ip’,master_user=’master user’,master_password=’password’, master_log_file=’记录的log文件名’,master_log_pos=刚才记录的position;
slave start.
注意:两边数据库中的表结构要一致。多尝试。
还有就是为什么我这master上设置slave的ip是我主机ip呢。囧。
我的slave是在virtualbox中的centos
原文:http://www.cnblogs.com/ekse/p/4294630.html