方法一:以空间换时间,可以定义一个数组int count[MAX],并将其数组元素都初始化为0,然后执行for(int i=0;i<100;i++) count[A[i]]++;操作,这样比如A[0]、A[3]和A[5]都为2,那么count[2]的值就为3,最后在count中找最大的数对应的下标,即为重复次数最多的数。
程序示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33 |
#include "stdafx.h"int GetMaxNum(int* arr, int
len, int& num){ int
index = arr[0]; int
i; for
(i = 0; i < len; i++) { if
(arr[i]>index) { index = arr[i]; num = i; } //printf("%d\n", num); } return
index;}int
main(){ int
array[] = { 1, 1, 2, 2, 4, 4, 4, 4, 5, 5, 6,6 }; int
length = sizeof(array) / sizeof(array[0]); int
i; int
num = 0; int* count = new
int[GetMaxNum(array, length, num)]; for
(i = 0; i < length; i++) count[i] = 0; for
(i = 0; i < length; i++) count[array[i]]++; printf("最大的数出现的次数是:%d\n", GetMaxNum(count, GetMaxNum(array, length, num), num)); printf("出现次数最多的数是:%d\n", num); getchar(); return
0;} |
效果如图:
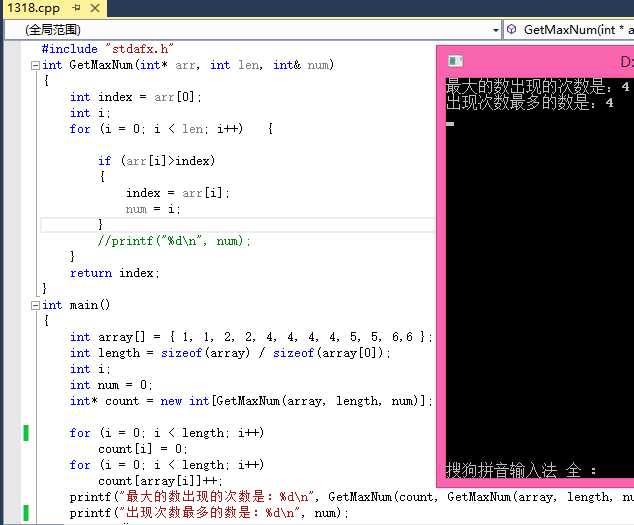
上例是一种典型的空间换时间算法。一般情况下,除非内存空间足够大,否则一般不采用这种方法。
方法二:使用map映射表,通过引入map表来记录每一个元素出现的次数。map是STL的一个关联容器,它提供一对一的数据处理能力,其中第一个为关键字,每个关键字只能在map中出现一次,第二个称为该关键字的值,map的初始化值全部为0.我们设定初始状态时重复次数最多的数为val,那么它的出现次数就为map[val]。对目标数组中的每一个元素都与当前的最大重复次数,即map[val]作比较,若大于等于map[val],那val就该换为该元素了。这样一轮循环过后,就能找出重复次数最多的元素了。
程序示例如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 |
#include "stdafx.h"#include <iostream>#include <map>using
namespace std;bool
findMostFrequentInArray(int
*a, int
size, int
&val){ if
(a == NULL || size <= 0) return
false; map<int, int> m; for
(int i = 0; i < size; i++) { m[a[i]]++; if
(m[a[i]] >= m[val]) val = a[i]; //cout << a[i]<<m[a[i]] << endl; } return
true;}int
main(){ int
val = 0; int
a[] = { 1, 5, 4, 3, 4, 4, 5, 4, 5, 5, 6 }; if
(findMostFrequentInArray(a, 11, val)) cout << val << endl; getchar(); return
0;} |
效果如图:
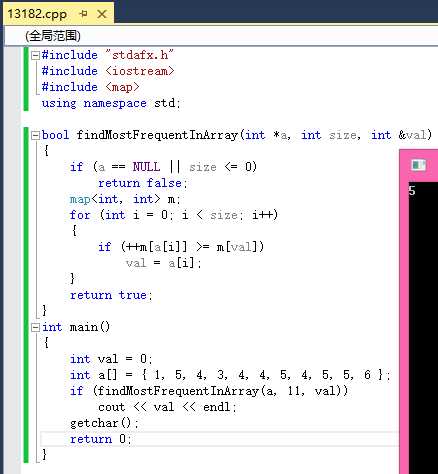
我觉着这种方法更快,时间复杂度只有O(n)的说。。。。。
如何找出数组中重复次数最多的数,布布扣,bubuko.com
原文:http://www.cnblogs.com/cysolo/p/3585857.html