源:CNUOJ-0384 http://oj.cnuschool.org.cn/oj/home/problem.htm?problemID=354
题目分析:当时拿到这道题第一个想法就是排序后n^2暴力枚举,充分利用好有序这一特性随时“短路”。

1 read(n);read(m); 2 int temp; 3 4 for(int i = 0; i < n; i++) 5 { 6 read(temp); 7 if(temp <= m) 8 { 9 p[tot].v = temp; 10 p[tot++].num = i; 11 } 12 } 13 14 sort(p, p + tot); 15 16 for(int i = 0; i < tot - 1; i++) 17 { 18 for(int j = i + 1; j < tot; j++) 19 { 20 if(p[i].v + p[j].v > m) break; 21 else if(p[i].num < p[j].num) ans++; 22 } 23 ans %= 1000000007; 24 } 25 26 printf("%d\n", ans); 27 28 return 0;
然后很高兴的简单一测试就哭了……为什么答案始终不对呢……

如上图就是一个十分典型的例子(下标为序号),不难发现当我们手算时,我们是算的“2 + 1”,但排完序后计算机执行的是“1 + 2”,序号不符合题意就被砍掉了……
那么怎么解决呢?第一个想法便是优化一下 j 的循环,从头到尾全来一遍,保证不漏解:
1 read(n);read(m); 2 int temp; 3 4 for(int i = 0; i < n; i++) 5 { 6 read(temp); 7 if(temp <= m) 8 { 9 p[tot].v = temp; 10 p[tot++].num = i; 11 } 12 } 13 14 sort(p, p + tot); 15 16 for(int i = 0; i < tot; i++) 17 { 18 for(int j = 0; j < tot; j++) 19 { 20 if(i == j) continue; 21 if(p[i].v + p[j].v > m) break; 22 else if(p[i].num < p[j].num) ans++; 23 } 24 ans %= 1000000007; 25 } 26 27 printf("%d\n", ans);
排序是nlogn,枚举是n^2,对于十万的数据量无法吐槽……只能有50分……

好的,接下来我们来分析一下这个算法干了些什么,比如对于3 2 1这个序列:
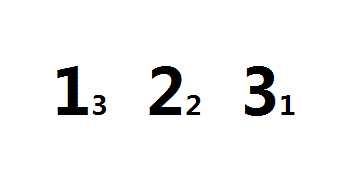
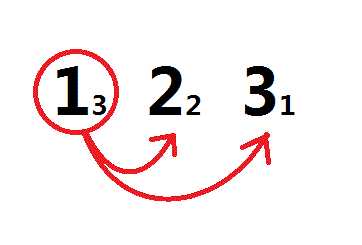
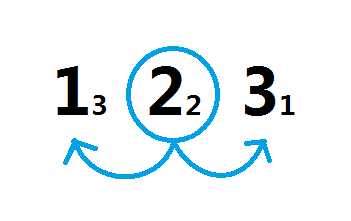
可以看到,1 -> 2, 2 -> 1 分别别计算过一次,其中红色的一次失败了,蓝色的成功了。(在红色中3 > 2,而在蓝色中是2 < 3满足题意)
也不难得出:每一对数字都被正着计算了一次,反着计算了一次;一次失败,一次成功。
那么:反正判断不判断都是ans++ 一次(仅成功一次,失败的时候不会更新),那为什么要判断呢?
于是,我们编出了下面没有判断编号只判断了大小的程序:
1 for(int i = 0; i < tot - 1; i++) 2 { 3 for(int j = i + 1; j < tot; j++) 4 { 5 if(p[i].v + p[j].v > m) break; 6 ans++; 7 } 8 ans %= 1000000007; 9 }
这个算法常数可以几乎砍掉一半多,但复杂度仍然是n^2的,它的表现……呵呵

进一步的优化就要从查询方法开始了:用十分常见的二分法效果怎么样呢?于是我们终于得到了标程:
1 #include <iostream> //第一题标程 2 #include <cstdio> 3 #include <cmath> 4 #include <algorithm> 5 using namespace std; 6 7 const int maxn = 100000 + 5; 8 int n, m; 9 10 int p[maxn]; 11 int ans = 0; 12 13 int tot = 0; 14 15 int A[maxn]; 16 17 void read(int& x) 18 { 19 x = 0; 20 char ch = getchar(); 21 int sig = 1; 22 while(!isdigit(ch)) 23 { 24 if(ch == ‘-‘) sig = -1; 25 ch = getchar(); 26 } 27 while(isdigit(ch)) 28 { 29 x = x * 10 + ch - ‘0‘; 30 ch = getchar(); 31 } 32 x *= sig; 33 return ; 34 } 35 36 37 int main() 38 { 39 read(n);read(m); 40 int temp; 41 42 for(int i = 0; i < n; i++) 43 { 44 read(temp); 45 if(temp <= m) p[tot++] = temp; 46 } 47 48 sort(p, p + tot); 49 50 int L, R, M; 51 52 for(int i = 0; i < tot - 1; i++) 53 { 54 L = i; 55 R = tot - 1; 56 57 if(p[R] + p[i] <= m) 58 { 59 ans += R - i; 60 continue; 61 } 62 63 while(L < R) 64 { 65 M = L + R >> 1; 66 //printf("L:%d M:%d R:%d\n", L, M, R); 67 if(p[i] + p[M] <= m) L = M + 1; 68 else R = M; 69 } 70 71 if(L - i > 1) ans += L - i - 1; 72 73 //cout << ans << endl; 74 ans %= 1000000007; 75 } 76 77 printf("%d\n", ans); 78 79 return 0; 80 }
从n^2到nlogn是不小的进步,十万的数据专为nlogn而生:

这道题就这样被干掉了……
小结:本题一定要好好读条件,仔细分析哪些可以优化。
考点:二分,坑题
原文:http://www.cnblogs.com/chxer/p/4321331.html
