?
?
eXtensible Markup Language可扩展标记语言
????
????????主要是用于描述数据,而非显示数据。一般用于配置文件
????????html是一个特殊的XML
a,声明必须处于xml文件的第一行,声明之前不能有任何内容。
????????b,<?xml和?>中间定义 version版本 和 encoding字符集 standalone表示文档是独立的还是依赖其它文档
????????c,<?xml中间不能有空格,?>之间也不能有空格
?

?
<!--只有一种注释--> 且不能嵌套
?
命名规范:
可以由字母,汉字,下划线,数字,减号组成。
但是,只能以字母,汉字和下划线开头。
书写规范:
元素都是用<>包裹起来的
<和元素名称直接不能有空格,制表符
XML中元素都需要有结束
????????元素可以有主体内容,也可以没有
元素之间不能嵌套
?
a,属性名称的命名规范与元素相同
????????b,属性只能出现在开始元素中
????????c,同一个元素的属性名称不能相同
????????d,属性的值都是用‘或""括起来的
?
?
CDATA的区是让区域内容以文本的形式显示
????????????<![CDATA[ 内容 ]]>
?
< <
> >
& &
"表示双引号
&qpos; 表示单引号
?
?
?
PI指令:用来指挥软件如何解析XML文档。
????????XML的声明,就是PI指令的一种具体体现形式????
Document Type Definition 文档类型定义
用来约束XML中元素,元素属性的个数和顺序。
????????????a. 直接写在XML文档当中
?
????????????b. 引用dtd文件
????????????????第一种:使用本地DTD
????????????????????<!DOCTYPE 根元素 SYSTEM DTD URL>

?
第二种:使用网络DTD
????<!DOCTYPE 根元素???? PUBLIC DTD URL>
???? ?
?

????小括号内可以子元素,例如:(书)和(书名,作者,售价)
????也可以是具体类型,例如:(#PCDATA)表示普通文本>
?
子元素的规则
1 如果括号内的元素以逗号分开,则表示其必须是按照书写顺序出现
2 如果括号内的元素以|分开,则表示其任选其一
3 +,*,?表示的是元素出现的次数
????+ 表示可出现多次
????* 表示可有可无,可出现多次
?????表示可有可无,但是如果有的话,只能出现一次
????什么都不写表示有且只有一次
?
?
????a,定义:
Schema它也是一个XML,是一个特殊的XML,同时也遵循XML的规范。
????????xmlns:(xml name space ) 引入xsd的名称空间
????????targetNamespace:目标名称空间。将当前xsd绑定到哪个名称空间上。
????
b,如何引入(使用)xsd
?
????????1 使用xmlns来引入名称空间,该名称空间与targetNamespace一致。
????????2 使用schemaLocation指定该名称空间下的哪个xsd文件。
????????3 使用xmlns:xsi来指定schemaLocation来自哪个名称空间

????????????DOM:是树形结构解析。需要加载整个文档。弊端:容易造成内存溢出。
????????????SAX:按行读取,读一行解析一行。弊端:增删改都不方便
????????????JAXP: 基于DOM,是w3c推出。
????????????DOM4J:基于DOM,是第三方开源的
????????????SAX:基于SAX,是来源于一个开源社区
?
?
?
1,获取document对象
????????a 获取解析器工厂类 DocumentBuilderFactory
?
????????b 获取解析器 DocumentBuilder
?
????????c 获取Document
?
????2,将内容保存
????????TransformerFactory
????????Transformer
????????former.transform(
new DOMSource(document),
new StreamResult("src/com/jinfulin/db/Students.xml"));
???? ?
?
?
1,概述
针对DOM解析的缺点诞生的。(不耗费很多的内存);按行解析,查询速度快,缺点是只适合查询。
SAX:Simple API for XML。来自开源社区。
?
2、原理:

SAX解析是读到XML文档的每一部分,就立刻进行解析。调用对应处理器的响应方法。
?
4,处理过程
?
//通过工厂获取解析器对象
????????SAXParserFactory factory = ????????????????????????SAXParserFactory.newInstance();
????????SAXParser parser = factory.newSAXParser();
????????//调用parse方法通过DefaultHandler子类实现方法
????parser.parse("src/LocalLIst.xml",new myHandler());
?
????SAXReader reader = new SAXReader();
???? Document document = reader.read("src/LocalList.xml");
????OutputFormat format= OutputFormat.createPrettyPrint();
//给人看,有格式
????//OutputFormat format =OutputFormat.createCompactFormat();
//给电脑看,没有格式(一行的形式 )
????????XMLWriter writer = new XMLWriter(
new FileOutputStream("src/LocalList.xml"),
format);
????????writer.write(document);
?
//获取根节点
????????Element root = document.getRootElement();
????????//获取全部指定名称子节点
????????List<Element> list = root.elements("City");
????????//获取子节点内容
????????Element e = list.get(4);
????????Element ee = e.element("name");
????????System.out.println(ee.getText());
?
//创建元素节点
????????Element etest = DocumentHelper.createElement("test");
//设置节点文本
????????etest.setText("jinfulin");
//添加子节点
eCity.add(etest);
????????
//设置元素属性
e.addAttribute("king", "aa");
?
?
?
Xpath主要用于获取节点
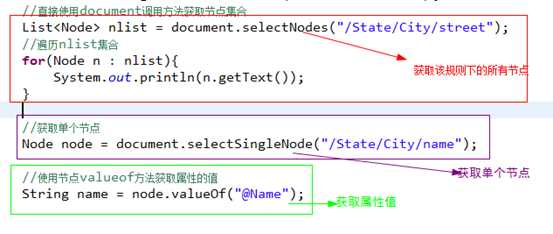
?
Document:selectNodes("xpath"),返回多个节点
Document:selectSingleNode("xpath"),返回一个节点或者没有
Node:valueOf("xpath") 取属性的值
?
注意:
使用XPath之前要引用dom4j-1.6.1\dom4j-1.6.1\lib\jaxen-1.1-beta-6.jar包,否则会报error
?
?
?
???? * 1 必须是public的
???? * 2 必须没有返回值
???? * 3 必须没有参数
???? * 4 全都有@Test注解
?
???? * @Test 测试方法的注解
???? * 有两个常用属性
???? * ????timeout:方法的过期时间,当不超过过期时间,并且断言通过的情况下,测试通过
???? * expected:预期的异常,当出现此异常时,测试通过
???? * @Before 在每次方法执行前执行
???? * @After 在每次方法执行后执行
???? * @Before和@After是有几个方法就会执行几次
???? *
???? * @BeforeClass 在类加载的时候执行
???? * @AfterClass 在类卸载前执行
???? * @BeforeClass和@AfterClass只会执行一次
?
?
????????Node
????????NodeList
????????Element
????????TransformerFactory
????????Transformer
?
Document -- Node--Element---
?
?
?
?
?
?
?
?
?
原文:http://www.cnblogs.com/jinfulin/p/4358389.html