古腾堡项目 www.gutenberg.org
OLAC元数据格式档 http://www.language-archives.org/
语料库邮件列表 http://clu.uni.no/corpora/sub.html
ETHNOLOGUE 世界完整语言清单 http://www.ethnologue.com/
SIL 语言项目http://www.sil.org/
1.

1 >>> phrase = [‘abstruse‘] 2 >>> type(phrase) 3 <type ‘list‘> 4 >>> phrase + [‘bb‘] 5 [‘abstruse‘, ‘bb‘] 6 >>> phrase + [‘bb‘] * 3 7 [‘abstruse‘, ‘bb‘, ‘bb‘, ‘bb‘] 8 >>> (phrase + [‘bb‘]) * 3 9 [‘abstruse‘, ‘bb‘, ‘abstruse‘, ‘bb‘, ‘abstruse‘, ‘bb‘] 10 >>> tmp = (phrase + [‘bb‘]) * 3 11 >>> tmp[-3:] 12 [‘bb‘, ‘abstruse‘, ‘bb‘] 13 >>> sorted(tmp) 14 [‘abstruse‘, ‘abstruse‘, ‘abstruse‘, ‘bb‘, ‘bb‘, ‘bb‘] 15 >>> tmp[-1] 16 ‘bb‘
2.
1 >>> import nltk 2 >>> nltk.corpus.gutenberg.fileids() 3 [‘austen-emma.txt‘, ‘austen-persuasion.txt‘, ‘austen-sense.txt‘, ‘bible-kjv.txt‘, ‘blake-poems.txt‘, ‘bryant-stories.txt‘, ‘burgess-busterbrown.txt‘, ‘carroll-alice.txt‘, ‘chesterton-ball.txt‘, ‘chesterton-brown.txt‘, ‘chesterton-thursday.txt‘, ‘edgeworth-parents.txt‘, ‘melville-moby_dick.txt‘, ‘milton-paradise.txt‘, ‘shakespeare-caesar.txt‘, ‘shakespeare-hamlet.txt‘, ‘shakespeare-macbeth.txt‘, ‘whitman-leaves.txt‘] 4 >>> per = nltk.corpus.gutenberg.words(‘austen-persuasion.txt‘) 5 >>> len(per) 6 98171 7 >>> len(set(per)) 8 6132 9 ## 区别 10 >>> len(set((s.lower() for s in per if s.isalpha()))) 11 5739 12 ## 13 >>> from __future__ import division 14 >>> len(per) / len(set(per)) 15 16.00962165688193 16 >>> type(per) 17 <class ‘nltk.corpus.reader.util.StreamBackedCorpusView‘> 18 >>> per[20:30] 19 [‘was‘, ‘a‘, ‘man‘, ‘who‘, ‘,‘, ‘for‘, ‘his‘, ‘own‘, ‘amusement‘, ‘,‘]
3
from nltk.corpus import brown brown.categories() [‘adventure‘, ‘belles_lettres‘, ‘editorial‘, ‘fiction‘, ‘government‘, ‘hobbies‘, ‘humor‘, ‘learned‘, ‘lore‘, ‘mystery‘, ‘news‘, ‘religion‘, ‘reviews‘, ‘romance‘, ‘science_fiction‘] b = brown.words(categories=‘humor‘) print ‘ ‘.join(b[:50]) w = nltk.corpus.webtext.words(‘pirates.txt‘) print ‘ ‘.join(w[:50])
4
1 modals = [‘men‘, ‘women‘, ‘people‘] 2 3 cfd = nltk.ConditionalFreqDist( 4 (target,fileid[:4]) 5 for fileid in state_union.fileids() 6 for w in state_union.words(fileid) 7 for target in modals 8 if w.lower().startswith(target)) 9 cfd.plot()
8
1 names = nltk.corpus.names 2 3 cfd = nltk.ConditionalFreqDist( 4 (fileid, name[0]) 5 for fileid in names.fileids() 6 for name in names.words(fileid)) 7 8 cfd.plot
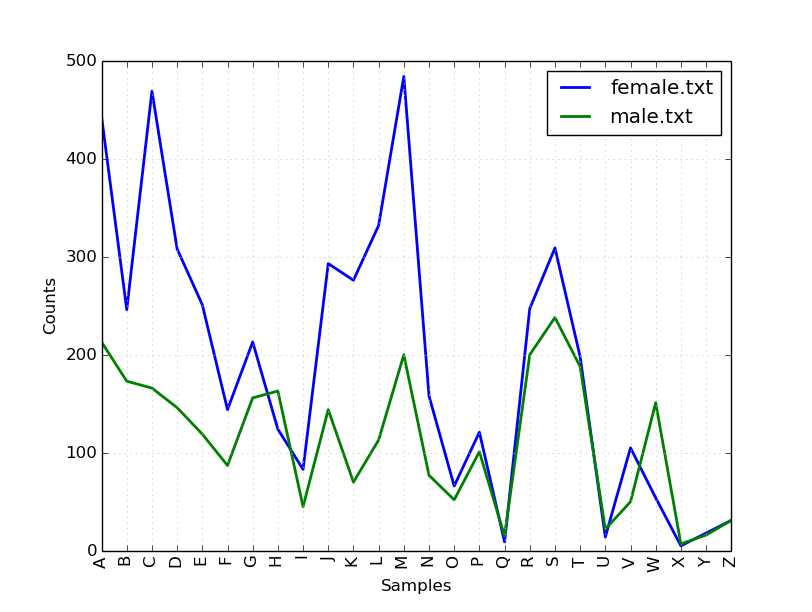
图显示,首字母H和W在男名中比女名中更常用。
9.
用词典过滤文本语料的内容。
# 函数定义
# myproc.py
from __future__ import division import nltk from nltk.corpus import stopwords def content_fraction(text): """calculate words fractioin without stop words""" stopwords = nltk.corpus.stopwords.words(‘english‘) content = [w for w in text if w.lower() not in stopwords] return len(content) / len(set(content)) # 命令行 from nltk.book import *
from myproc iimport * content_fraction(text1) 8.06865891513653 content_fraction(text2) 11.399421789409617
可以看出,去掉停用词后,<<Moby Dick>>词汇比<<Sense and Sensibility>>更丰富。(注,不去停用词,统计结果同样支持这个结论。)
疑问:如何考察文体(genre)差异? 文体上分,二者都是小说,再具体点,一个是恐怖(惊悚)小说,一个是言情(浪漫)小说。
如果有分类语料库,如BROWN,直接提供了类型。
若如TEXT1,TEXT2等TEXT词链表,如何能根据词汇统计得出“文体”的结论呢?分类语料库是如何进行文本分类的,依据是什么?搞清楚这两点,大约可以仿BROWN分类方法,将这道题目做出来了。
尝试,发现Moby dick应是写whale的, S&S应是写人的。
探查一个词在两个文本中的词义,如下。
1 text1.concordance(‘monstrous‘) 2 text2.concordance(‘monstrous‘) 3 4 text1.similar(‘monstrous‘) 5 text2.similar(‘monstrous‘) 6 7 #还可以 8 text1.common_contexts("‘monstrous‘", "abundant") 9 text2.common_contexts("‘monstrous‘", "very")
用WordNet考察monstrous词义,会发现该词意义很单一,没有小说中那么丰富的变化。定义就是"abnormally large"。
这个意义更接近现在的词义。是否因为写于1811的S&S比写于1851年的MB在语言用法方面与现代距离更远呢?
1 >>> from nltk.corpus import wordnet as wn 2 >>> wn.synsets(‘monstrous‘) 3 [Synset(‘monstrous.s.01‘), Synset(‘atrocious.s.01‘), Synset(‘grotesque.s.01‘)] 4 >>> wn.synset(‘monstrous.s.01‘).lemma_names 5 [‘monstrous‘] 6 >>> wn.synset(‘atrocious.s.01‘).lemma_names 7 [‘atrocious‘, ‘flagitious‘, ‘grievous‘, ‘monstrous‘] 8 >>> wn.synset(‘grotesque.s.01‘).lemma_names 9 [‘grotesque‘, ‘monstrous‘] 10 >>> wn.synset(‘monstrous.s.01‘).definition 11 ‘abnormally large‘ 12 >>> wn.synset(‘monstrous.s.01‘).examples 13 [] 14 >>> wn.synset(‘monstrous.s.01‘).lemmas 15 [Lemma(‘monstrous.s.01.monstrous‘)]
(待续……)
原文:http://www.cnblogs.com/cfsmile/p/4340740.html
