Storm Topology:

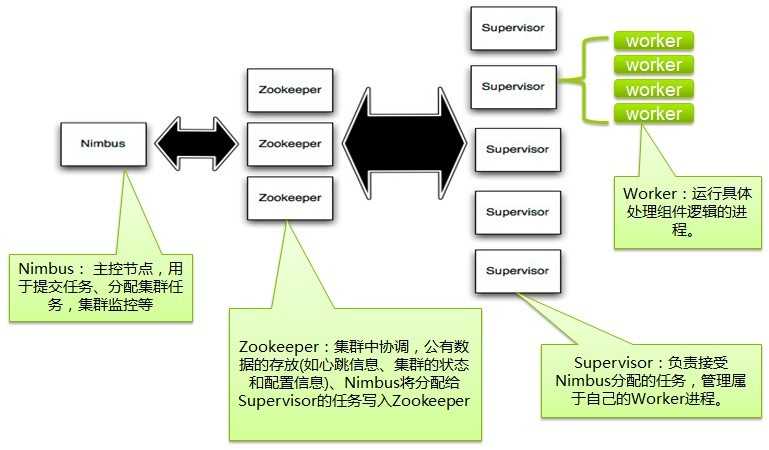
Nimbus和Supervisor之间的所有协调工作都是通过一个Zookeeper集群来完成。并且,nimbus进程和supervisor都是快速失败(fail-fast)和无状态的。所有的状态要么在Zookeeper里面, 要么在本地磁盘上。这也就意味着你可以用kill -9来杀死nimbus和supervisor进程, 然后再重启它们,它们可以继续工作, 就好像什么都没有发生过似的。这个设计使得storm不可思议的稳定。
Hadoop VS Storm:
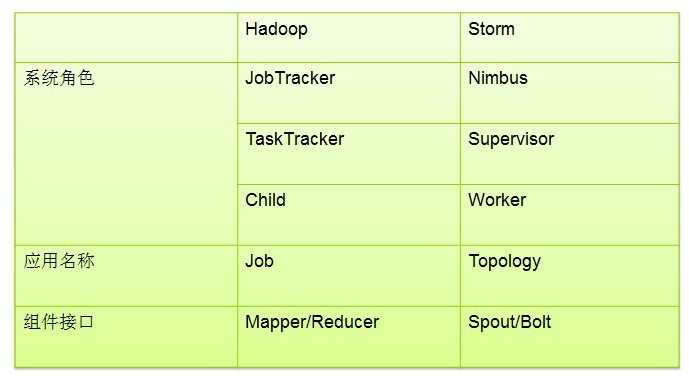
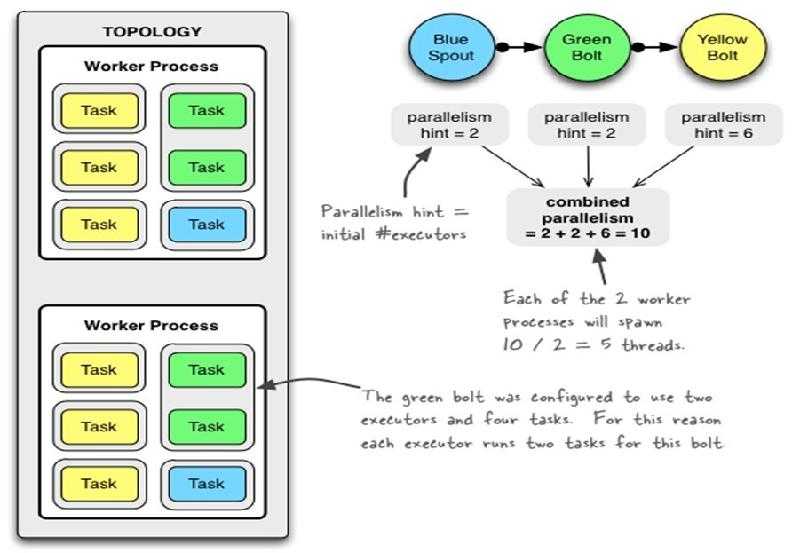
a. Worker processes(进程)
b. Executors (threads)(线程)
c. Tasks
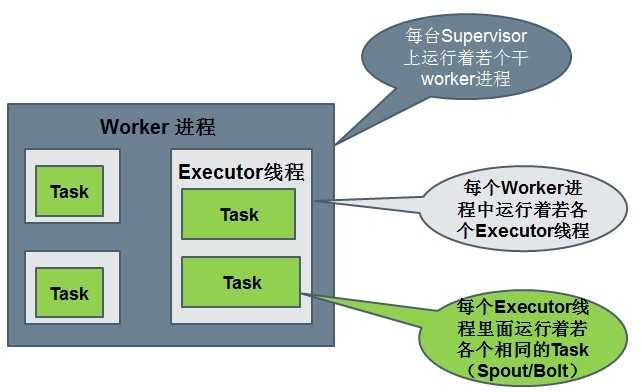
Spout或者Bolt的Task个数一旦指定之后就不能改变了,而Executor的数量可以根据情况来进行动态的调整。默认情况下# executor = #tasks即一个Executor中运行着一个Task。
示例代码:
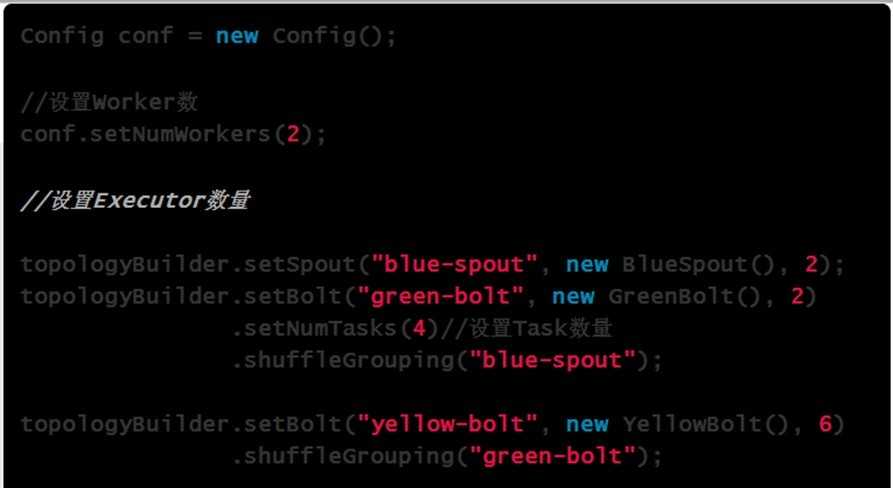
分析:
结果展示:

原文:http://www.cnblogs.com/xymqx/p/4366429.html