应用:
1.Redis里替代char *;
2.实现字符串对象;
主要技能:
1.O(1)的时间获取字符串的长度;
2.有缓冲区,比较方便的实现字符串的拓展;
3.二进制安全的;
源码:
先看sdshdr结构体:
typedef char *sds; struct sdshdr { unsigned int len; unsigned int free; char buf[]; };
有len来记录当前字符串的长度,能在O(1)获取长度;
拓展空间的策略:
#define SDS_MAX_PREALLOC (1024*1024)
/* Enlarge the free space at the end of the sds string so that the caller * is sure that after calling this function can overwrite up to addlen * bytes after the end of the string, plus one more byte for nul term. * * Note: this does not change the *length* of the sds string as returned * by sdslen(), but only the free buffer space we have. */ sds sdsMakeRoomFor(sds s, size_t addlen) { struct sdshdr *sh, *newsh; size_t free = sdsavail(s); size_t len, newlen; if (free >= addlen) return s; len = sdslen(s); sh = (void*) (s-(sizeof(struct sdshdr))); newlen = (len+addlen); if (newlen < SDS_MAX_PREALLOC) newlen *= 2; else newlen += SDS_MAX_PREALLOC; newsh = zrealloc(sh, sizeof(struct sdshdr)+newlen+1); if (newsh == NULL) return NULL; newsh->free = newlen - len; return newsh->buf; }
当所需要的空间比1M小的时候,空间扩展为所需空间的2倍;
当所需要的空间比1M小的时候,空间扩展为所需空间+1M;
Q:这些空间什么时候会被释放?会浪费内存吗?
执行过APPEND 命令的字符串会带有额外的预分配空间,这些预分配空间不会被释放,除非该字符串所对应的键被删除,或者等到关闭Redis 之后,再次启动时重新载入的字符串对象将不会有预分配空间。
执行APPEND 命令的字符串不会太多,这样内存不会被消耗太多,如果如果执行APPEND 操作的键很多,而字符串的体积又很大的话,可以那可能就需要修改Redis 服务器,让它定时释放一些字符串键的预分配空间,从而更有效地使用内存。
应用:
1.Redis列表的底层实现之一;
2.事务模块使用双端链表来按顺序保存输入的命令;
3.服务器模块使用双端链表来保存多个客户端;
4.订阅/发送模块使用双端链表来保存订阅模式的多个客户端;
5.事件模块使用双端链表来保存时间事件(time event);
主要技能:
1.O(1)获取链表的长度;
2.listNode 带有prev 和next 两个指针,因此,对链表的遍历可以在两个方向上进行;
3.list 保存了head 和tail 两个指针,因此,对链表的表头和表尾进行插入的复杂度都为O(1);
源码:
先看节点的结构体:
typedef struct listNode { struct listNode *prev; struct listNode *next; void *value; } listNode; typedef struct listIter { listNode *next; int direction; } listIter; typedef struct list { listNode *head; listNode *tail; void *(*dup)(void *ptr); void (*free)(void *ptr); int (*match)(void *ptr, void *key); unsigned long len; } list;
具体的添加,删除,查找操作,一般算法书里面都是有的;
应用:
1.实现Redis的键空间;
2.Hash类型的一种底层实现;
名词解释:
键空间:
每个数据库都有一个与之相对应的字典,这个字典被称之为键空间。
主要技能:
1.是一组键值对;
源码:
字典有多种实现的方法:
1.最简单的就是使用链表或数组,但是这种方式只适用于元素个数不多的情况下;
2.追求高效及简单,可以用哈希表;
3.如果追求更为稳定的性能特征,并且希望高效地实现排序操作的话,则可以使用更为复杂的平衡二叉树;
Redis用的是哈希表。
先看dict及其相关的结构:
typedef struct dictEntry { void *key; union { void *val; uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; } dictEntry; typedef struct dictType { unsigned int (*hashFunction)(const void *key); /*散列函数*/ void *(*keyDup)(void *privdata, const void *key);/*复制键*/ void *(*valDup)(void *privdata, const void *obj);/*复制值*/ int (*keyCompare)(void *privdata, const void *key1, const void *key2);/*比较键*/ void (*keyDestructor)(void *privdata, void *key); void (*valDestructor)(void *privdata, void *obj); } dictType; /* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; /*指针数组的长度掩码,用于计算索引值*/ unsigned long used; } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ int iterators; /* number of iterators currently running */// 当前正在运作的安全迭代器数量 } dict;
上张图,直观的看看整个结构:
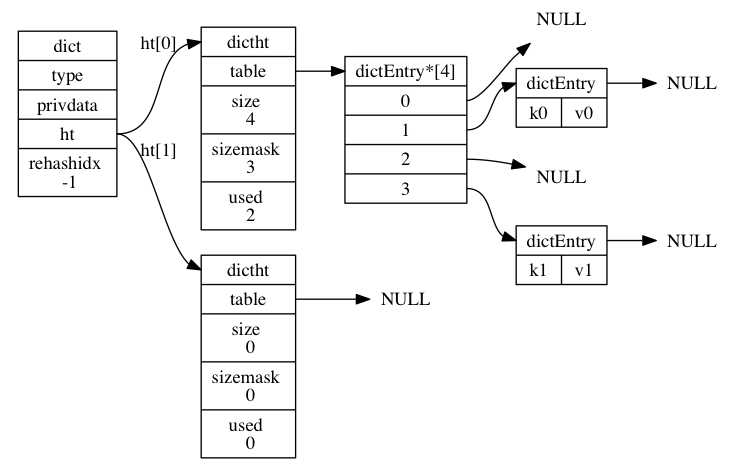
既然是哈希表,要知道用什么hash函数,是什么方式来解决碰撞问题,Redis使用的是 链地址法;但是链地址法在节点数量比哈希表的大小要大很多的话,那么哈希表就会退化成多个链表,哈希表本身的性能优势就不再存在;为了在字典的键值对不断增多的情况下保持良好的性能,字典需要对所使用的哈希表(ht[0])进行rehash 操作:在不修改任何键值对的情况下,对哈希表进行扩容,尽量将比率维持在1:1左右。
1.hash函数:
/* MurmurHash2, by Austin Appleby * Note - This code makes a few assumptions about how your machine behaves - * 1. We can read a 4-byte value from any address without crashing * 2. sizeof(int) == 4 * * And it has a few limitations - * * 1. It will not work incrementally. * 2. It will not produce the same results on little-endian and big-endian * machines. */
这种算法的分布率和速度都非常好;
另一种hash方法,大小写无关:
/* And a case insensitive hash function (based on djb hash) */ unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) { unsigned int hash = (unsigned int)dict_hash_function_seed; while (len--) hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */ return hash; }
2.hash表的缩小和扩容:
/* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USED/BUCKETS ratio near to <= 1 */ int dictResize(dict *d) { int minimal; if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; minimal = d->ht[0].used; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; return dictExpand(d, minimal); } /* Expand or create the hash table */ int dictExpand(dict *d, unsigned long size) { dictht n; /* the new hash table */ unsigned long realsize = _dictNextPower(size); /* the size is invalid if it is smaller than the number of * elements already inside the hash table */ if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR; /* Allocate the new hash table and initialize all pointers to NULL */ n.size = realsize; n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*)); n.used = 0; /* Is this the first initialization? If so it‘s not really a rehashing * we just set the first hash table so that it can accept keys. */ if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; } /* Prepare a second hash table for incremental rehashing */ d->ht[1] = n; d->rehashidx = 0; return DICT_OK; }
3.hash的添加:
dictEntry *dictAddRaw(dict *d, void *key) { int index; dictEntry *entry; dictht *ht; if (dictIsRehashing(d)) _dictRehashStep(d); /* Get the index of the new element, or -1 if * the element already exists. */ if ((index = _dictKeyIndex(d, key)) == -1) return NULL; /* Allocate the memory and store the new entry */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++; /* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; }
说明:可以看到,添加时第一步的操作是判断是不是在进行rehash操作;然后再进行计算散列下标,注意,在rehash时散列于ht[1],否则是ht[0];
PS:在_dictKeyIndex函数值得看一下:
/* Returns the index of a free slot that can be populated with * a hash entry for the given ‘key‘. * If the key already exists, -1 is returned. * * Note that if we are in the process of rehashing the hash table, the * index is always returned in the context of the second (new) hash table. */ static int _dictKeyIndex(dict *d, const void *key) { unsigned int h, idx, table; dictEntry *he; /* Expand the hash table if needed */ if (_dictExpandIfNeeded(d) == DICT_ERR) return -1; /* Compute the key hash value */ h = dictHashKey(d, key); for (table = 0; table <= 1; table++) { idx = h & d->ht[table].sizemask; /* Search if this slot does not already contain the given key */ he = d->ht[table].table[idx]; while(he) { if (dictCompareKeys(d, key, he->key)) return -1; he = he->next; } if (!dictIsRehashing(d)) break; } return idx; }
需要先拓展,调用_dictExpandIfNeeded函数;
* Expand the hash table if needed */ static int _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK; /* If the hash table is empty expand it to the initial size. */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); } return DICT_OK; }
可以看出来:
Rehash时候不拓展;
字典是空的时候,需要拓展;
当 used/size 在 [1,5]之间的时候,当dict_can_resize为真时拓展;
当 used/size > 5的时候 ,一定拓展;
没有在rehash时,数据都在ht[0]表中;
4.rehash操作
/* Performs N steps of incremental rehashing. Returns 1 if there are still * keys to move from the old to the new hash table, otherwise 0 is returned. * Note that a rehashing step consists in moving a bucket (that may have more * than one key as we use chaining) from the old to the new hash table. */ int dictRehash(dict *d, int n) { if (!dictIsRehashing(d)) return 0; while(n--) { dictEntry *de, *nextde; /* Check if we already rehashed the whole table... */ if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return 0; } /* Note that rehashidx can‘t overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++; de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ while(de) { unsigned int h; nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; } return 1; }
说明:
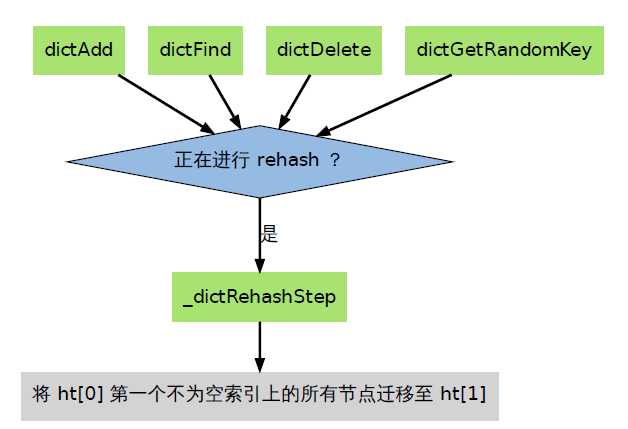
rehashidx=-1的时候,并不进行 rehash,当rehashidx!=-1的时候进行 rehash;rehashidx这个值记录当前需要重新散列的ht[0]的rehashidx链表,将其中的每一个节点重新散列到ht[1];散列几次 由参数 n 决定;另外,当 ht[0].used == 0 将 ht[1] 替换ht[0],同时将ht[1]清空;
在rehash 开始进行之后(d->rehashidx 不为-1),每次执行一次添加、查找、删除操作,都会rehash;
参考资料:
《redis 设计与实现》
原文:http://www.cnblogs.com/zhouyuqing-blog/p/4369295.html