JUnit提供了Test Suite来帮助我们组织case,还提供了Category来帮助我们来给建立大的Test Set,比如BAT,MAT, Full Testing。 那么什么情况下,这些仍然不能满足我们的需求,需要进行拓展呢?
闲话不表,直接上需求:
1. 老板希望能精确的衡量出每个Sprint写了多少条自动化case,或者每个User Story又设计了多少条case来保证覆盖率,以此来对工作量和效率有数据上的直观表示。
2. 对于云服务,通常会有不同的server来对应产品不同的开发阶段,比如dev的server,这里大家可以随意上传代码,ScrumQA会测试每一个开发提交的Feature -> 然后当产品部署到测试server时,Scrum QA 和 System QA 就得对产品进行充分的测试 -> 甚或者有预发布的server,来模拟真实产品环境,这个server,仍然需要测试 -> 最后产品会部署到真正的生产环境上。
这时候就衍生了测试代码版本控制的问题,比如当我针对新需求写的自动化case所测得Feature,当前只在Dev上部署,还没有在其他的server部署,那我的case怎么办?在其他的server上运行一定会失败。
3. 当产品足够复杂时,我们可能就有成千上万条case,这样全部运行这些case,时间上可能就非常耗时。 而如果使用JUnit的category来分组可能颗粒度太粗,不灵活,怎么办?
综合考虑,为解决以上需求,我们觉得必须在Case级别上做文章,所以结合JUnit4的功能,我们最终引入了新的注解Annotation:Spint, UserStory, 和 Defect。
| 名称 | 描述 | 作用域 |
| Sprint | 用来标记这条Case是在什么时候引进的,或者说这条Case是哪个Sprint的加入的功能 | 方法 |
| UserStory | 用来标记这条Case测试的是哪个UserStory,或者说覆盖的那个UserStory,这样即使过了很长时间,我们也能清晰地知道,我们为什么加这条Case,以及它到底测的是什么功能 | 方法 |
| Defect | 用来标记这条Case覆盖的Defect,或者说覆盖的Defect | 方法 |
在实际使用时,我们就可以这么用:
@Test @Sprint("15.3") @UserStory("US30145") @Defect(CR = "30775", Title = "[cr30775][p0] xxxx...") public void test_AddUserDirectDebitInformation_204_WithoutXXXBefore() { // Case Body }
那么在运行时,根据这些标记,我们就可以随心所欲的Filter出我们需要的Case了:
当然统计每个Sprint的工作量也就有了可能。
研究过类似问题的童鞋可能知道,IBM的网站上,有一篇文章,讲过这个问题(地址在文章底有列)。并且他还定义了更多的注解需求, 也给出了部分实现。这篇文章有个好处就是先从JUnit整体架构运行流程出发,采用各个模块包装的方法,然后从入口JUnitCore出发去重新发起Request来运行我们自定义的Case,我觉得研究这篇文章可以对不了解JUnit核心框架的童鞋有一定的帮助。
这篇文章已经给出了自定义Runner部分的代码,缺了两块。第一是IntentObject部分,它把参数封装成对象。第二部分就是定义实现Filter。我这里给出它缺的那部分Filter的实现,Intent这块直接当String处理就可以了。
public class FilterFactory { public static final String REGEX_COMMA = ","; public static final String ANNOTATION_PREFIX = "com.junit.extension.annotations."; // 包名的前缀 public static final String REGEX_EQUAL = "="; public static List<Filter> filters = new ArrayList<Filter>(); public static List<Filter> getFilters() { return filters; } // This is a special toggle served {@link Sprint} public static String FILTER_RUN_CASE_ISONLY_TOGGLE = "isOnly"; private static FilterSprint fSprint = null; private static FilterUserStory fUserStory = null; private static FilterDefect fDefect = null; public static List<Filter> createFilters(String intention) throws ClassNotFoundException { String[] splits = intention.split(REGEX_COMMA); for(String split : splits) { String[] pair = split.split(REGEX_EQUAL); if(pair != null && pair.length == 2) { if(pair[0].trim().equalsIgnoreCase(FILTER_RUN_CASE_ISONLY_TOGGLE)) { if(fSprint == null) { fSprint = new FilterSprint(); } fSprint.setIsOnly(Boolean.parseBoolean(pair[1].trim())); } else { Class<?> annotation = Class.forName(ANNOTATION_PREFIX + pair[0].trim()); if(annotation.isAssignableFrom(Sprint.class)) { fSprint = new FilterSprint(pair[1].trim()); } else if(annotation.isAssignableFrom(UserStory.class)) { fUserStory = new FilterUserStory(pair[1].trim()); filters.add(fUserStory); } else if(annotation.isAssignableFrom(Defect.class)) { fDefect = new FilterDefect(pair[1].trim()); filters.add(fDefect); } } if(fSprint != null) { filters.add(fSprint); } } } return filters; }
然后再实现各个注解自定义Filter类,实现Filter的shouldRun方法定义, 以Sprint为例:
/** * Filter rules for the annotation {@link Sprint} * * @author Carl Ji * */ public class FilterSprint extends Filter { private String tgValue = null; private Boolean _isOnly = false; public FilterSprint(String targetValue) { setTgValue(targetValue); } public FilterSprint(String targetValue, Boolean isOnly) { setTgValue(targetValue); _isOnly = isOnly; } public FilterSprint() { // TODO Auto-generated constructor stub } public Boolean getIsOnly() { return _isOnly; } public void setIsOnly(Boolean isOnly) { this._isOnly = isOnly; } public String getTgValue() { return tgValue; } public void setTgValue(String tgValue) { this.tgValue = tgValue; } @Override public boolean shouldRun(FrameworkMethod method) { Sprint aSprint = method.getAnnotation(Sprint.class); return filterRule(aSprint); } @Override public boolean shouldRun(Description description) { if(description.isTest()) { Sprint aSprint = description.getAnnotation(Sprint.class); return filterRule(aSprint); } else { return true; } } @Override public String describe() { // TODO Auto-generated method stub return null; } // Implement of filter rule for Sprint Annotation private boolean filterRule(Sprint aSprint) { if(_isOnly) { if(aSprint != null && aSprint.value().equalsIgnoreCase(tgValue)) { return true; } else { return false; } } else { if(aSprint == null) { return true; } else { if(0 >= new StringComparator().compare(aSprint.value(), tgValue)) { return true; } } } return false; }
我这里多了个isOnly属性,是为了解决历史遗留的问题。很多以前的Case并没有我们加上新自定义的注解,那么就可以通过这个属性来定义这些Case要不要执行。
当然核心的Filter的方法,还是要看大家各自的需求,自行设定。
上面的实现方法做了很多工作,比如你要扩展JunitCore类,扩展Request 类,扩展RunnerBuilder类,还要扩展BlockJunit4ClassRunner类,那么研究过JUnit源码的童鞋可能知道,JUnit是提供入口让我们去注入Filter对象。具体是在ParentRunner类里的下面方法:
// // Implementation of Filterable and Sortable // public void filter(Filter filter) throws NoTestsRemainException { for (Iterator<T> iter = getFilteredChildren().iterator(); iter.hasNext(); ) { T each = iter.next(); if (shouldRun(filter, each)) { try { filter.apply(each); } catch (NoTestsRemainException e) { iter.remove(); } } else { iter.remove(); } } if (getFilteredChildren().isEmpty()) { throw new NoTestsRemainException(); } }
那其实我们只要把我们自定义的Filter对象传进来,我们的需求也就实现了。
public class FilterCollections extends Filter { List<Filter> filters = null; public FilterCollections(String intent) { try { filters = FilterFactory.createFilters(intent); } catch(ClassNotFoundException e) { e.printStackTrace(); } } @Override public boolean shouldRun(Description description) { List<Boolean> result = new ArrayList<Boolean>(); for(Filter filter : filters) { if(filter != null && filter.shouldRun(description)) { result.add(true); } else { result.add(false); } } if(result.contains(false)) { return false; } else { return true; } }
这样就可以通过BlockJunit4ClassRunner直接调用:
public class EntryToRunCases { public static void main(String... args) { if(args != null) { System.out.println("Parameters: " + args[0]); Filter customeFilter = new FilterCollections(args[0]); EntryToRunCases instance = new EntryToRunCases(); instance.runTestCases(customeFilter); } else { System.out.println("No parameters were input!"); } } protected void runTestCases(Filter aFilter) { BlockJUnit4ClassRunner aRunner = null; try { try { aRunner = new BlockJUnit4ClassRunner(JunitTest.class); } catch(InitializationError e) { System.out.print(e.getMessage()); } aRunner.filter(aFilter); aRunner.run(new RunNotifier()); } catch(NoTestsRemainException e) { System.out.print(e.getMessage()); } } }
这种方法要比上面IBM的实现,简单很多,不需要包装一些不必要的类了。
但是我们仍然发现它还有两个不方便的地方:
第一个问题很好解决,我们只要自己写方法来查找项目下的所有.java文件,匹配包含org.junit.Test.class注解的测试类就可以了,那第二个问题呢?
仔细思考我们的需求,我们会发现,我们并不想改变JUnit的Case执行能力,我们期望的只是希望JUnit能够只运行我们希望让它跑的Case. 而JUnit的Categories实现的就是这种功能。Categories继承自Suite类,我们看他的构造函数:
public Categories(Class<?> klass, RunnerBuilder builder) throws InitializationError { super(klass, builder); try { filter(new CategoryFilter(getIncludedCategory(klass), getExcludedCategory(klass))); } catch (NoTestsRemainException e) { throw new InitializationError(e); } assertNoCategorizedDescendentsOfUncategorizeableParents(getDescription()); }
实际上就是把自定义的CategoryFilter传递给ParentRunner的filter方法,跟上面的方式,异曲同工。
Categories不识别我们的注解,那么我们是不是可以仿照它,做自己的Categories类呢?如下:
1。 首先定义使用自定义Categories的参数:
@Retention(RetentionPolicy.RUNTIME) public @interface IncludeSprint { String value(); /* * This annotation will determine whether we want to run case without Sprint annotation or not * If not set, it is false by default */ boolean isOnly() default false; } @Retention(RetentionPolicy.RUNTIME) public @interface IncludeUserStory { String value(); } @Retention(RetentionPolicy.RUNTIME) public @interface IncludeDefect { String value(); }
2。然后就可以在构造函数里针对它做处理:
/** * Used by JUnit */ public AnnotationClasspathSuite(Class<?> suiteClass, RunnerBuilder builder) throws InitializationError { super(builder, suiteClass, getTestclasses(new ClasspathClassesFinder(getClasspathProperty(suiteClass), new ClassChecker( getSuiteType(suiteClass))).find())); try { filter(new AnnotationsFilter(getIncludedSprint(suiteClass), getIncludedUserStory(suiteClass), getIncludedDefect(suiteClass), IsOnlyRunCaseWithSprintAnnotation(suiteClass))); } catch(NoTestsRemainException e) { throw new InitializationError(e); } assertNoCategorizedDescendentsOfUncategorizeableParents(getDescription()); }
这样做出的自定义Suite Runner在使用上就非常方便了,比如:
@RunWith(AnnotationClasspathSuite.class) @IncludeSprint(value = "15.3", isOnly = true) public class TestRunner { }
这样就可以明确的表明,我们只想跑Spring15.3的Case。并且结果也能在Eclipse IDE里完美展示:
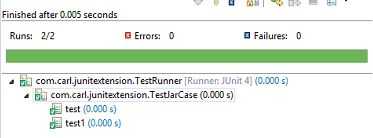
通过上面的实现,我们就能更细粒度的规划我们的case,也能按需灵活的运行自动化测试用例。
实现这个期间,参考了不是好文章和代码,推荐童鞋们看看:
http://www.ibm.com/developerworks/cn/java/j-lo-junit4tdd/
http://highstick.blogspot.com/2011/11/howto-categorize-junit-test-methods-and.html
https://github.com/takari/takari-cpsuite
如果您看了本篇博客,觉得对您有所收获,请点击下面的 [推荐]
如果您想转载本博客,请注明出处
如果您对本文有意见或者建议,欢迎留言
原文:http://www.cnblogs.com/jinsdu/p/4373070.html