HQL操作
1、Distribute by
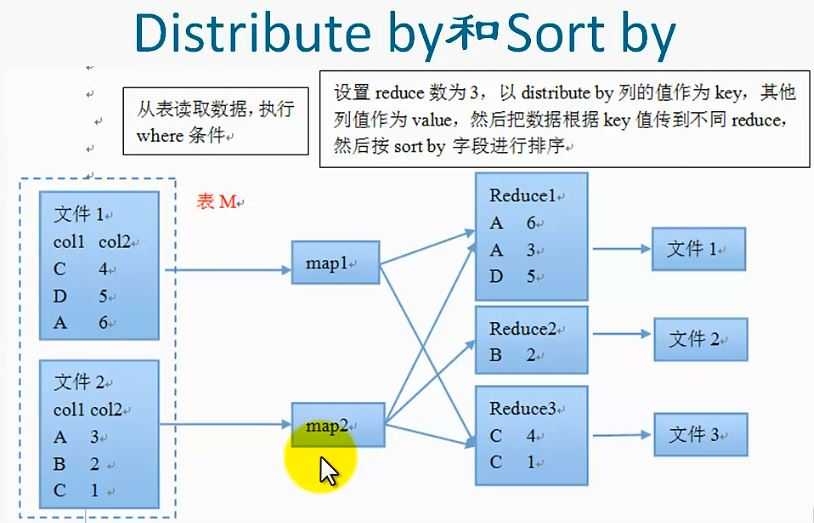
distribute by col按照col列把数据分散到不同的reduce
sort
sort by col 按照col列把数据排序
select col,co2 from table_name distribute by col1 sort by col1
asc,col2 desc;
两者结合出现,确保每个reduce的输出都是有序的
应用场景:
* map输出的文件大小不均
* reduce输出文件大小不均
* 小文件过多
* 文件超大
2、cluster by
把有相同值得数据聚集到一起,并排序,例如:
cluster by col
distribute by col order by col
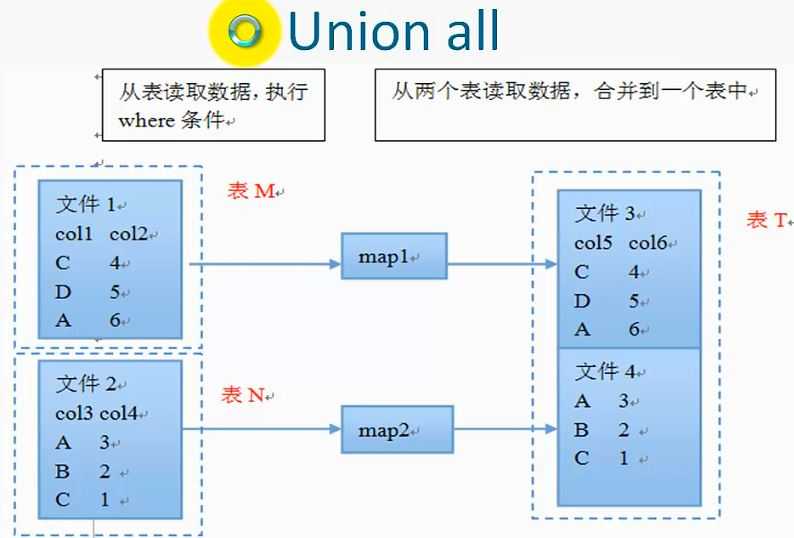
3、Union all
将多个表的数据合并成一个表,hive不支持union
select col from(select a as col from t1 union all select b as col from t2)tmp
要求:
字段名字一样
字段类型一样
字段个数一样
子表不能有别名
如果需要从合并之后的表中查询数据,那么合并的表必须有别名
原文:http://www.cnblogs.com/sunfie/p/4376648.html