|
1
2
3
4
5
6
7
8 |
CREATE TABLE `test` ( `id` INT(20) NOT NULL AUTO_INCREMENT, `name` VARCHAR(20) NULL DEFAULT NULL, `age` INT(5) NULL DEFAULT NULL, PRIMARY KEY (`id`))COLLATE=‘utf8_general_ci‘ENGINE=InnoDB |
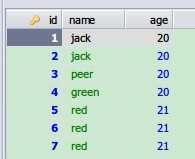
查询出所有重复的记录 ,删除所有 select a.* 换成delete
|
1
2
3
4 |
select a.* from test a join
(select name,count(*) from
test group
by name having count(*)> 1 ) b on a.name = b.name; |
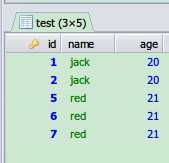
查询不重复的记录,和重复记录里最后插入的记录
|
1 |
select
* from
test a where
a.id = (select
max(id) from
test b where
a.name = b.name); |
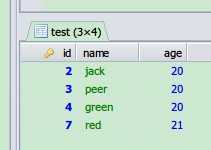
查询不重复的记录。和重复记录里,最先插入的记录
|
1 |
select * from test a where
a.id = (select
min(id) from
test b where
a.name = b.name); |
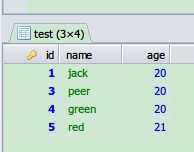
查询出重复记录里,第一条重复记录以外的所有重复记录 删除的话select * 换成delete
|
1 |
select * from test a where
a.id != (select
min(id) from
test b where
a.name = b.name); |
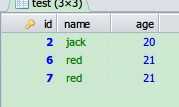
查询出重复记录里,最后一条重复记录以外所有重复的记录 ,删除的话select * 换成delete
|
1 |
select * from test a where
a.id != (select
max(id) from
test b where
a.name = b.name); |
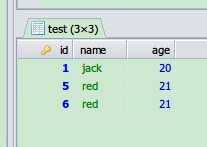
mysql 查询及 删除表中重复数据,布布扣,bubuko.com
原文:http://www.cnblogs.com/or2-/p/3594945.html