关于select与epoll的区别,网上的文章已是一大堆。不过别人的终究是别人的,总得自己去理解才更深刻。于是在阅读了大量的文章后,再装模作样的看下源码,写下了自己的一些理解。
在开始之前,要明白linux中分用户空间、内核空间,这相当于两块不能直接相互访问的内存。而用户程序要访问设备,包括网络、读写文件,都需要调用内核的相关函数。而调用内核相关函数,则往往需要从用户空间往内核拷贝一些数据,反之亦然。当调用非常频繁,这个拷贝的消耗也是不能忽略的。具体请参考:http://www.kerneltravel.net/jiaoliu/005.htm
select相关函数的源代码http://lxr.free-electrons.com/source/fs/select.c
epoll相关函数的源代码http://lxr.free-electrons.com/source/fs/eventpoll.c

SYSCALL_DEFINE5(select, int, n, fd_set __user *, inp, fd_set __user *, outp, fd_set __user *, exp, struct timeval __user *, tvp) { struct timespec end_time, *to = NULL; struct timeval tv; int ret; if (tvp) { /* 如果设置了超时,则需要将时间结构体从用户空间拷贝到内核空间 */ if (copy_from_user(&tv, tvp, sizeof(tv))) return -EFAULT; to = &end_time; /* 格式化时间到结构体to中 */ if (poll_select_set_timeout(to, tv.tv_sec + (tv.tv_usec / USEC_PER_SEC), (tv.tv_usec % USEC_PER_SEC) * NSEC_PER_USEC)) return -EINVAL; } ret = core_sys_select(n, inp, outp, exp, to); /* 拷贝文件描述符集合,然后调用do_select */ ret = poll_select_copy_remaining(&end_time, tvp, 1, ret);/* 把处理后超时信息拷贝到用户空间 */ return ret; }
int core_sys_select(int n, fd_set __user *inp, fd_set __user *outp, fd_set __user *exp, struct timespec *end_time) { fd_set_bits fds; void *bits; int ret, max_fds; unsigned int size; struct fdtable *fdt; /* Allocate small arguments on the stack to save memory and be faster */ long stack_fds[SELECT_STACK_ALLOC/sizeof(long)]; ret = -EINVAL; if (n < 0) goto out_nofds; /* max_fds can increase, so grab it once to avoid race */ rcu_read_lock(); fdt = files_fdtable(current->files); max_fds = fdt->max_fds; rcu_read_unlock(); if (n > max_fds) n = max_fds; /* * We need 6 bitmaps (in/out/ex for both incoming and outgoing), * since we used fdset we need to allocate memory in units of * long-words. */ size = FDS_BYTES(n); bits = stack_fds; if (size > sizeof(stack_fds) / 6) { /* Not enough space in on-stack array; must use kmalloc */ ret = -ENOMEM; bits = kmalloc(6 * size, GFP_KERNEL); if (!bits) goto out_nofds; } fds.in = bits; fds.out = bits + size; fds.ex = bits + 2*size; fds.res_in = bits + 3*size; fds.res_out = bits + 4*size; fds.res_ex = bits + 5*size; /* get_fd_set只是将文件描述符从用户空间拷贝到内核空间 */ if ((ret = get_fd_set(n, inp, fds.in)) || (ret = get_fd_set(n, outp, fds.out)) || (ret = get_fd_set(n, exp, fds.ex))) goto out; zero_fd_set(n, fds.res_in); zero_fd_set(n, fds.res_out); zero_fd_set(n, fds.res_ex); ret = do_select(n, &fds, end_time); if (ret < 0) goto out; if (!ret) { ret = -ERESTARTNOHAND; if (signal_pending(current)) goto out; ret = 0; } /* get_fd_set只是将文件描述符从内核空间拷贝到用户空间 */ if (set_fd_set(n, inp, fds.res_in) || set_fd_set(n, outp, fds.res_out) || set_fd_set(n, exp, fds.res_ex)) ret = -EFAULT; out: if (bits != stack_fds) kfree(bits); out_nofds: return ret; } int get_fd_set(unsigned long nr, void __user *ufdset, unsigned long *fdset) { nr = FDS_BYTES(nr); if (ufdset) return copy_from_user(fdset, ufdset, nr) ? -EFAULT : 0; memset(fdset, 0, nr); return 0; }
int do_select(int n, fd_set_bits *fds, struct timespec *end_time) { ktime_t expire, *to = NULL; struct poll_wqueues table; /* 注意这是等待队列 */ poll_table *wait; int retval, i, timed_out = 0; unsigned long slack = 0; unsigned int busy_flag = net_busy_loop_on() ? POLL_BUSY_LOOP : 0; unsigned long busy_end = 0; rcu_read_lock(); retval = max_select_fd(n, fds); rcu_read_unlock(); if (retval < 0) return retval; n = retval; /* 这里初始化队列信息,设置设备唤醒回调指针 当程序进入休眠后,如果设备有事件发生,根据回调指针唤醒当前进程 */ poll_initwait(&table); wait = &table.pt; if (end_time && !end_time->tv_sec && !end_time->tv_nsec) { wait->_qproc = NULL; timed_out = 1; } if (end_time && !timed_out) slack = select_estimate_accuracy(end_time); retval = 0; for (;;) { /* 循环,方便唤醒后重新遍历文件描述符查找事件 */ unsigned long *rinp, *routp, *rexp, *inp, *outp, *exp; bool can_busy_loop = false; inp = fds->in; outp = fds->out; exp = fds->ex; rinp = fds->res_in; routp = fds->res_out; rexp = fds->res_ex; /* 遍历所有的文件描述符,查找是否有文件描述符存在读写、异常事件 */ for (i = 0; i < n; ++rinp, ++routp, ++rexp) { unsigned long in, out, ex, all_bits, bit = 1, mask, j; unsigned long res_in = 0, res_out = 0, res_ex = 0; in = *inp++; out = *outp++; ex = *exp++; all_bits = in | out | ex; if (all_bits == 0) { i += BITS_PER_LONG; continue; } for (j = 0; j < BITS_PER_LONG; ++j, ++i, bit <<= 1) { struct fd f; if (i >= n) break; if (!(bit & all_bits)) continue; f = fdget(i); if (f.file) { const struct file_operations *f_op; f_op = f.file->f_op; mask = DEFAULT_POLLMASK; /* 如果找到对应的poll函数,找不到就是设备驱动没写好,socket对应的函数是sock_poll */ if (f_op->poll) { wait_key_set(wait, in, out, bit, busy_flag); /* 得到当前设备状态,这里有wait,但不会阻塞。只是设置回调指针 */ mask = (*f_op->poll)(f.file, wait); } fdput(f); /* 下面按位检测事件 */ if ((mask & POLLIN_SET) && (in & bit)) { res_in |= bit; retval++; wait->_qproc = NULL; } if ((mask & POLLOUT_SET) && (out & bit)) { res_out |= bit; retval++; wait->_qproc = NULL; } if ((mask & POLLEX_SET) && (ex & bit)) { res_ex |= bit; retval++; wait->_qproc = NULL; } /* got something, stop busy polling */ if (retval) { can_busy_loop = false; busy_flag = 0; /* * only remember a returned * POLL_BUSY_LOOP if we asked for it */ } else if (busy_flag & mask) can_busy_loop = true; } } if (res_in) *rinp = res_in; if (res_out) *routp = res_out; if (res_ex) *rexp = res_ex; cond_resched(); } wait->_qproc = NULL; /* 如果已经有结果,直接返回 */ if (retval || timed_out || signal_pending(current)) break; if (table.error) { retval = table.error; break; } /* only if found POLL_BUSY_LOOP sockets && not out of time */ if (can_busy_loop && !need_resched()) { if (!busy_end) { busy_end = busy_loop_end_time(); continue; } if (!busy_loop_timeout(busy_end)) continue; } busy_flag = 0; /* * If this is the first loop and we have a timeout * given, then we convert to ktime_t and set the to * pointer to the expiry value. */ if (end_time && !to) { expire = timespec_to_ktime(*end_time); to = &expire; } if (!poll_schedule_timeout(&table, TASK_INTERRUPTIBLE, /* 这里阻塞,直到超时 */ to, slack)) timed_out = 1; /* 设置超时,上面为什么会用一个for(;;)就是为了超时后还去检查一次是否有事件 */ } poll_freewait(&table); return retval; }
SYSCALL_DEFINE1(epoll_create1, int, flags) { int error, fd; struct eventpoll *ep = NULL; struct file *file; /* Check the EPOLL_* constant for consistency. */ BUILD_BUG_ON(EPOLL_CLOEXEC != O_CLOEXEC); if (flags & ~EPOLL_CLOEXEC) return -EINVAL; /* * Create the internal data structure ("struct eventpoll"). */ error = ep_alloc(&ep); if (error < 0) return error; /* * Creates all the items needed to setup an eventpoll file. That is, * a file structure and a free file descriptor. */ fd = get_unused_fd_flags(O_RDWR | (flags & O_CLOEXEC));/* 分配一个文件描述符 */ if (fd < 0) { error = fd; goto out_free_ep; } file = anon_inode_getfile("[eventpoll]", &eventpoll_fops, ep, O_RDWR | (flags & O_CLOEXEC)); if (IS_ERR(file)) { error = PTR_ERR(file); goto out_free_fd; } ep->file = file; fd_install(fd, file); return fd; out_free_fd: put_unused_fd(fd); out_free_ep: ep_free(ep); return error; } static int ep_alloc(struct eventpoll **pep) { int error; struct user_struct *user; struct eventpoll *ep; user = get_current_user(); error = -ENOMEM; ep = kzalloc(sizeof(*ep), GFP_KERNEL); /* 在内核上分配一块内存 */ if (unlikely(!ep)) goto free_uid; spin_lock_init(&ep->lock); mutex_init(&ep->mtx); init_waitqueue_head(&ep->wq); /* 初始化监听文件描述符链表 */ init_waitqueue_head(&ep->poll_wait); INIT_LIST_HEAD(&ep->rdllist); /* 初始化就绪链表 */ ep->rbr = RB_ROOT; ep->ovflist = EP_UNACTIVE_PTR; ep->user = user; *pep = ep; return 0; free_uid: free_uid(user); return error; }
SYSCALL_DEFINE4(epoll_ctl, int, epfd, int, op, int, fd, struct epoll_event __user *, event) { int error; int full_check = 0; struct fd f, tf; struct eventpoll *ep; struct epitem *epi; struct epoll_event epds; struct eventpoll *tep = NULL; error = -EFAULT; if (ep_op_has_event(op) && copy_from_user(&epds, event, sizeof(struct epoll_event))) /* 这里可能会产生拷贝 */ goto error_return; error = -EBADF; f = fdget(epfd); if (!f.file) goto error_return; /* Get the "struct file *" for the target file */ tf = fdget(fd); if (!tf.file) goto error_fput; /* The target file descriptor must support poll */ error = -EPERM; if (!tf.file->f_op->poll) goto error_tgt_fput; /* Check if EPOLLWAKEUP is allowed */ if (ep_op_has_event(op)) ep_take_care_of_epollwakeup(&epds); /* * We have to check that the file structure underneath the file descriptor * the user passed to us _is_ an eventpoll file. And also we do not permit * adding an epoll file descriptor inside itself. */ error = -EINVAL; if (f.file == tf.file || !is_file_epoll(f.file)) goto error_tgt_fput; /* * At this point it is safe to assume that the "private_data" contains * our own data structure. */ ep = f.file->private_data; /* * When we insert an epoll file descriptor, inside another epoll file * descriptor, there is the change of creating closed loops, which are * better be handled here, than in more critical paths. While we are * checking for loops we also determine the list of files reachable * and hang them on the tfile_check_list, so we can check that we * haven‘t created too many possible wakeup paths. * * We do not need to take the global ‘epumutex‘ on EPOLL_CTL_ADD when * the epoll file descriptor is attaching directly to a wakeup source, * unless the epoll file descriptor is nested. The purpose of taking the * ‘epmutex‘ on add is to prevent complex toplogies such as loops and * deep wakeup paths from forming in parallel through multiple * EPOLL_CTL_ADD operations. */ mutex_lock_nested(&ep->mtx, 0); if (op == EPOLL_CTL_ADD) { if (!list_empty(&f.file->f_ep_links) || is_file_epoll(tf.file)) { full_check = 1; mutex_unlock(&ep->mtx); mutex_lock(&epmutex); if (is_file_epoll(tf.file)) { error = -ELOOP; if (ep_loop_check(ep, tf.file) != 0) { clear_tfile_check_list(); goto error_tgt_fput; } } else list_add(&tf.file->f_tfile_llink, &tfile_check_list); mutex_lock_nested(&ep->mtx, 0); if (is_file_epoll(tf.file)) { tep = tf.file->private_data; mutex_lock_nested(&tep->mtx, 1); } } } /* * Try to lookup the file inside our RB tree, Since we grabbed "mtx" * above, we can be sure to be able to use the item looked up by * ep_find() till we release the mutex. */ epi = ep_find(ep, tf.file, fd); error = -EINVAL; switch (op) { case EPOLL_CTL_ADD: if (!epi) { epds.events |= POLLERR | POLLHUP; error = ep_insert(ep, &epds, tf.file, fd, full_check); } else error = -EEXIST; if (full_check) clear_tfile_check_list(); break; case EPOLL_CTL_DEL: if (epi) error = ep_remove(ep, epi); else error = -ENOENT; break; case EPOLL_CTL_MOD: if (epi) { epds.events |= POLLERR | POLLHUP; error = ep_modify(ep, epi, &epds); } else error = -ENOENT; break; } if (tep != NULL) mutex_unlock(&tep->mtx); mutex_unlock(&ep->mtx); error_tgt_fput: if (full_check) mutex_unlock(&epmutex); fdput(tf); error_fput: fdput(f); error_return: return error; }
SYSCALL_DEFINE4(epoll_wait, int, epfd, struct epoll_event __user *, events, int, maxevents, int, timeout) { int error; struct fd f; struct eventpoll *ep; /* The maximum number of event must be greater than zero */ if (maxevents <= 0 || maxevents > EP_MAX_EVENTS) return -EINVAL; /* Verify that the area passed by the user is writeable */ if (!access_ok(VERIFY_WRITE, events, maxevents * sizeof(struct epoll_event))) return -EFAULT; /* Get the "struct file *" for the eventpoll file */ f = fdget(epfd); if (!f.file) return -EBADF; /* * We have to check that the file structure underneath the fd * the user passed to us _is_ an eventpoll file. */ error = -EINVAL; if (!is_file_epoll(f.file)) goto error_fput; /* * At this point it is safe to assume that the "private_data" contains * our own data structure. */ ep = f.file->private_data; /* Time to fish for events ... */ error = ep_poll(ep, events, maxevents, timeout); error_fput: fdput(f); return error; }
static int ep_poll(struct eventpoll *ep, struct epoll_event __user *events, int maxevents, long timeout) { int res = 0, eavail, timed_out = 0; unsigned long flags; long slack = 0; wait_queue_t wait; ktime_t expires, *to = NULL; if (timeout > 0) { struct timespec end_time = ep_set_mstimeout(timeout); slack = select_estimate_accuracy(&end_time); to = &expires; *to = timespec_to_ktime(end_time); } else if (timeout == 0) { /* * Avoid the unnecessary trip to the wait queue loop, if the * caller specified a non blocking operation. */ timed_out = 1; spin_lock_irqsave(&ep->lock, flags); goto check_events; } fetch_events: spin_lock_irqsave(&ep->lock, flags); if (!ep_events_available(ep)) { /* * We don‘t have any available event to return to the caller. * We need to sleep here, and we will be wake up by * ep_poll_callback() when events will become available. */ /* 这里初始化等待队列,如果一个设备有事件,則会先往就绪链表中加就绪设备 然后唤醒进程 */ init_waitqueue_entry(&wait, current); __add_wait_queue_exclusive(&ep->wq, &wait); for (;;) { /* * We don‘t want to sleep if the ep_poll_callback() sends us * a wakeup in between. That‘s why we set the task state * to TASK_INTERRUPTIBLE before doing the checks. */ set_current_state(TASK_INTERRUPTIBLE); if (ep_events_available(ep) || timed_out) break; if (signal_pending(current)) { res = -EINTR; break; } spin_unlock_irqrestore(&ep->lock, flags); if (!schedule_hrtimeout_range(to, slack, HRTIMER_MODE_ABS)) /* 进入休眠 */ timed_out = 1; spin_lock_irqsave(&ep->lock, flags); } __remove_wait_queue(&ep->wq, &wait);/* 删除等待队列 */ set_current_state(TASK_RUNNING); } check_events: /* Is it worth to try to dig for events ? */ eavail = ep_events_available(ep); spin_unlock_irqrestore(&ep->lock, flags); /* * Try to transfer events to user space. In case we get 0 events and * there‘s still timeout left over, we go trying again in search of * more luck. */ if (!res && eavail && !(res = ep_send_events(ep, events, maxevents)) && !timed_out) goto fetch_events; return res; } static inline int ep_events_available(struct eventpoll *ep) { return !list_empty(&ep->rdllist) || ep->ovflist != EP_UNACTIVE_PTR; }
总结一下,select和epoll的流程如下: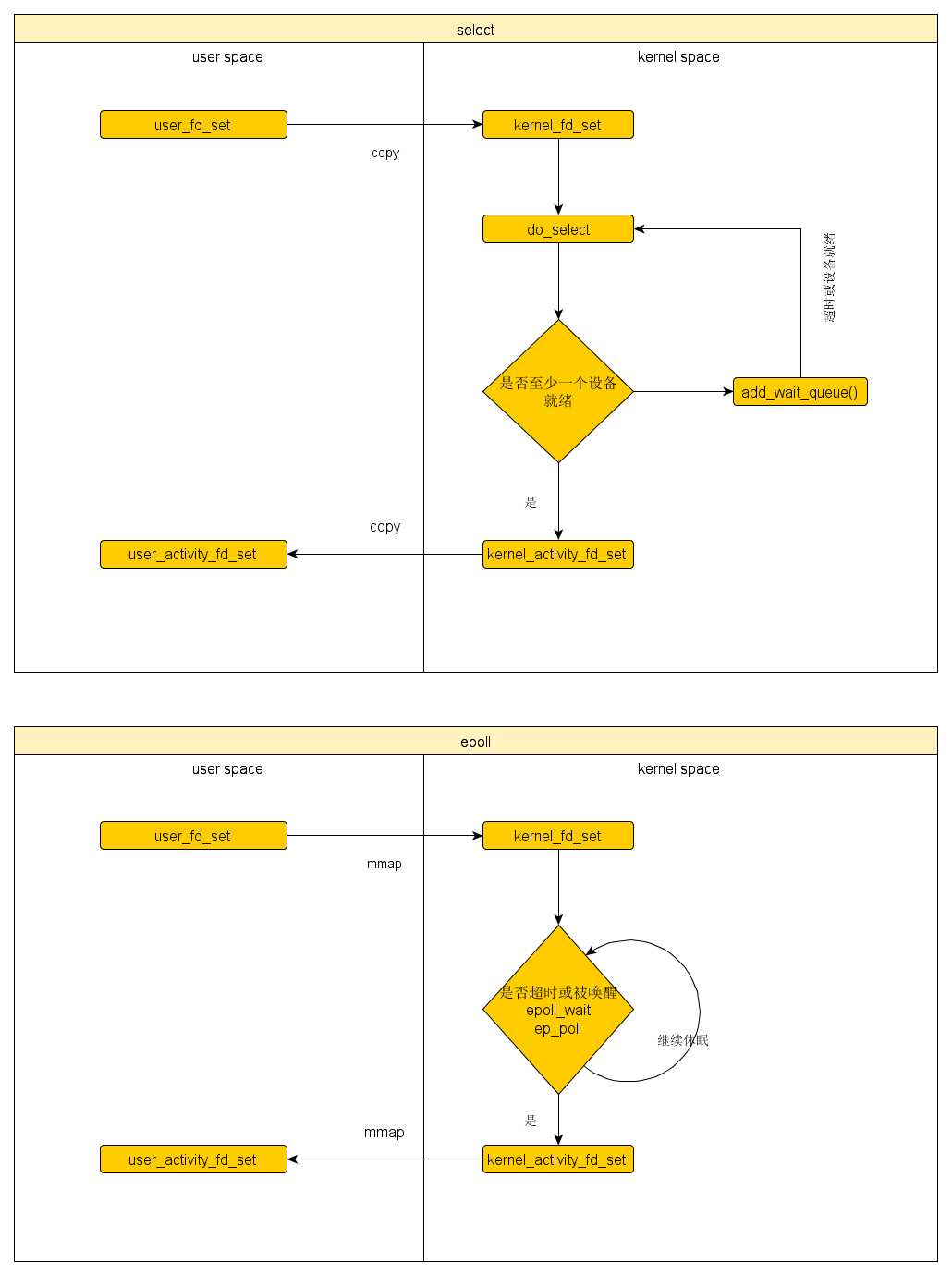
如果要比性能,那么大概有以下的区别:
一句话,select是你每天起床都去各个快递公司问是否有自己的快递,而epoll是每天起床到门口的邮箱查下是否有自己的快递。
原文:http://www.cnblogs.com/coding-my-life/p/4392656.html
