等价关系与等价类
若对于每一对元素(a,b),a,b∈S,a R b或者为true或者为false,则称在集合S上定义关系R。如果a R b为true,那么我们说a与b有关系。
等价关系(equivalence relation)是满足下列三个性质的关系R:
(1) 自反性:对于所有a∈S,a R a
(2) 对称性:若a R b当且仅当b R a
(3) 传递性:若a R b且b R c 则a R c
关系“≤”不是等价关系。虽然它是自反的(即a≤a)、可传递的(即由a≤b和b≤c得出a≤c),但它不是对称的,因为a≤b不能得出b≤a。
如果两个城市位于同一个国家,那么定义它们是由关系的。容易验证这是一个等价关系。如果能够通过公路从a旅行到b,则设a与b有关系。如果所有的道路都是双向行驶的,那么这种关系也是一个等价关系。
并查集:
在计算机科学中,并查集是一种树形的数据结构,其保持着用于处理一些不想交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示,进行快速规整。
并查集保持一组不想交的动态集合S={S1,S2,...,Sk}。每个集合通过一个代表来识别,代表即集合中的某个成员。在某些应用中,哪一个成员被选作代表无所谓。在一些应用中,如何选择代表可能存在预先说明的规则,例如选择集合中的最小元素。
并查集提供一下操作:
1. Find:确定元素属于哪一个集合。它可以被用来确定两个元素是否属于同一子集。返回的是包含给定元素的集合的名字
2. Union:将两个子集合并成同一个集合
3. MakeSet: 用于建立单元素集合。
并查集的表示方法:
1. 单链表表示
要实现并查集数据结构,一种简单的方法是每一个集合都用一个链表来表示。每个链表的第一个对象作为它所在集合的代表。链表中的每一个对象都包含一个集合成员、一个指向包含下一个集合成员的对象的指针,以及指向代表的指针。每个链表都含head指针和tail指针,head指向链表的代表,tail指向链表中最后的对象。
2. 并查集森林
并查集的另一种更快的实现是用有根树表示集合树中每个节点包含一个成员,每棵树代表一个集合。在一个不相交森林中,每个成员仅指向指向它的父节点。每棵树的根包含集合的代表,并且是其自己的父节点。正如我们将要看到的那样,虽然使用这种表示的直接算法并不比使用链表表示的算法快,但通过引入两种启发式策略(“按秩合并”和“路径压缩"),我们能得到一个渐进最优的不相交集合数据结构。
在这种表示方法中,MAKE-SET操作简单地创建一棵只有一个节点的树,Find操作通过沿着指向父节点的指针找到树的根。这一通过根节点的简单路径上所访问过的节点构成了查找路径。union操作使得一棵树指向另一棵树的根。下图所示为union操作:
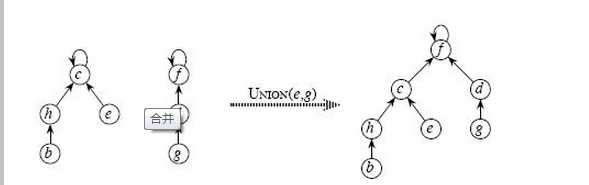
开始时每个集合含有一个元素。这些书不一定必须是二叉树,但是用二叉树表示起来要容易,因为我们需要的唯一信息就是父链(parent link)。集合的名字由根处的节点给出。由于只需要父节点的名字,因此可以假设这棵树是被非显式的存储在数组中(与二叉堆类似):数组的每个成员s[i]表示元素i的父亲。如果i是根,那么s[i]=-1.、
并查集森林的两种改进策略:
1. 按秩合并(union by rank)。改进union操作的方法。这种方法的思想是在union操作中使较少节点的树的根指向具有较多节点的树的根。为了实现这种方法,我们需要记住每一棵树的大小。由于实际上使用了一个数组,因此可以让每个根的数组包含它的树的大小的负值。这样一来,初始时的数组表示就都是-1了。当执行一次union时,要检查树的大小;新的大小是原来的大小的和。这样桉大小秩求并的实现并不困难,并且不需要额外的空间,其平均速度也很快。
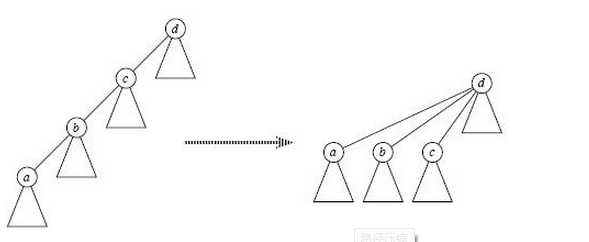
2. 路径压缩(path compression)。改进find操作的方法。它在查找过程中将每个节点直接指向根。如下所示
实现代码:
1 class DisjSets { 2 public: 3 explicit DisjSets(int numElements); 4 5 int Find(int x); 6 7 void Union(int element1, int element2); // union is key word in C++, use Union 8 9 private: 10 vector<int> s; 11 }; 12 13 DisjSets::DisjSets(int numElements): s(numElements) { 14 for (vector<int>::iterator iter = s.begin(); 15 iter != s.end(); ++iter) { 16 *iter = -1; 17 } 18 } 19 20 //路径压缩 21 int DisjSets::Find(int x) { 22 if (s[x] < 0) 23 return x; 24 else 25 return s[x] = Find(s[x]); 26 } 27 28 void DisjSets::Union(int element1, int element2) { 29 int root1 = Find(element1); //find root of element1 30 int root2 = Find(element2); //find root of element2 31 32 if (s[root2] < s[root1]) { //root2 is deeper 33 s[root1] = root2; //Make root2 new root 34 } else { 35 if (s[root1] == s[root2]) 36 s[root1]--; //Update height id same 37 s[root2] = root1; //Make root1 new root 38 } 39 }
原文:http://www.cnblogs.com/vincently/p/4415786.html