微软的那个臭屁的JOEL(就是写《JOEL说软件》的那个牛人)曾说:“每一位软件开发人员必须、绝对要至少具备UNICODE与字符集知识(没有任何例外)”,我也常常困扰于字符集的转换等很多问题,所以这次下决心要把他搞个清楚。
有关字符编码的学习,在这篇blog中,就从两个程序开始:
class TestDataGenerator { public static void CreateNewTestDataFile(string FileName, int record_length) { using(FileStream fs = File.Create(FileName)) { StringBuilder sb = new StringBuilder(); for (int i = 0; i < record_length; i++ ) { sb.Append(‘的‘); }//for byte[] content = Encoding.Unicode.GetBytes(sb.ToString()); fs.Write(content, 0, content.Length); }//using }//CreateNewTestDataFile() }
在上面的代码中:
Encoding.Unicode.GetBytes(sb.ToString());
这句话的意思就是把string编码成UTF-16的字节流。
调用该函数生成包含100个字符的测试文件:
TestDataGenerator.CreateNewTestDataFile("test.txt", 100);
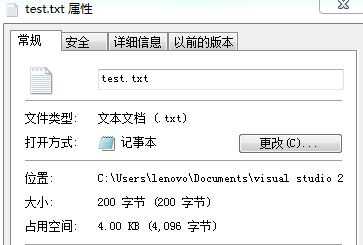
可以看到文件大小为200字节。原因是UTF-16使用2个字节来存储包括汉字和ASCII码在内的字符
读取Unicode字符串:
FileStream fs = new System.IO.FileStream("test.txt", FileMode.Open, FileAccess.Read);
byte[] blob = new byte[100];
fs.Read(blob, 0, 100);
fs.Flush();
string strUtf16 = Encoding.Unicode.GetString(blob);
string strUtf8 = Encoding.UTF8.GetString(blob);
从Watch窗口可见, 将字符串强转为UTF-8形式会出现乱码,这是因为UTF-8标准使用3个字节来存储汉字等字符,而不是UTF-16的2个字节。
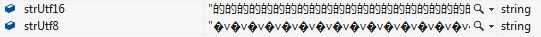
下面使用UTF-8编码存储字符:
byte[] content = Encoding.UTF8.GetBytes(sb.ToString()); fs.Write(content, 0, content.Length);
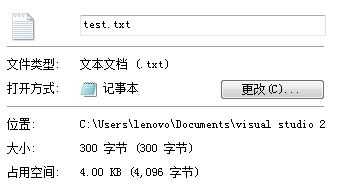
然后就能看到文件的大小为300个字节:
同理用UTF-16的编码方式去读取UTF-8编码方式存储的文件也是不行的。

对上面的代码解释几个概念:
C#的类Encoding的Encoding.Unicode属性:获取使用Little-Endian字节顺序的UTF-16格式的编码。
C#的类Encoding的Encoding.ASCII属性:获取ASCII(7位)字符集的编码。
C#的类Encoding的Encoding.UTF8属性:获取UTF-8格式的编码。
原文:http://www.cnblogs.com/stemon/p/4432965.html