---恢复内容开始---
Storm
是个实时的、分布式以及具备高容错的计算系统。同Hadoop一样Storm也可以处理大批量的数据,然而Storm在保证高可靠性的前提下还可以让处理进行的更加实时;也就是说,所有的信息都会被处理。 Storm同样还具备容错和分布计算这些特性,这就让Storm可以扩展到不同的机器上进行大批量的数据处理。
Storm 与Hadoop异同
1、Strom服务已经开启除非认为关闭,否者不会停止,
?2、实时:storm延时低,storm数据在内存中,hadoop数据使用磁盘作为交换介质。
3、storm延时低 storm 数据在内存中,网络直传,内存计算,省去了批处理时间。
4、storm吞吐量不及hadoop。不适合批处理。
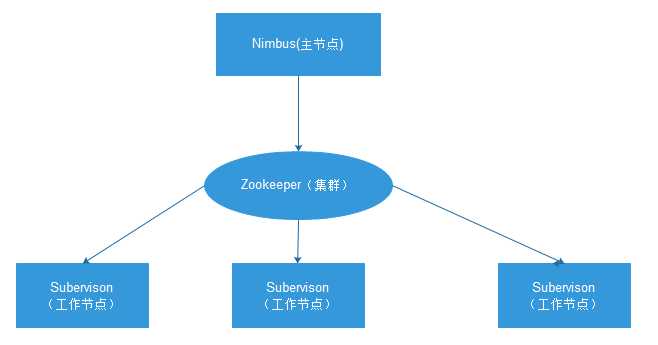
Storm集群主要由一个主节点和一群工作节点(worker node)组成,通过 Zookeeper进行协调。
Storm系结构简图:
• 主节点:
• 主节点通常运行一个后台程序 —— Nimbus,用于响应分布在集群中的节点,分配任务和监测故障。这
个很类似于Hadoop中的Job Tracker。
• 工作节点:
• 工作节点同样会运行一个后台程序 —— Supervisor,用于收听工作指派并基于要求运行工作进程。每个
工作节点都是topology中一个子集的实现。而Nimbus和Supervisor之间的协调则通过Zookeeper系统或
者集群。
• Zookeeper
• Zookeeper是完成Supervisor和Nimbus之间协调的服务。而应用程序实现实时的逻辑则被封装进Storm
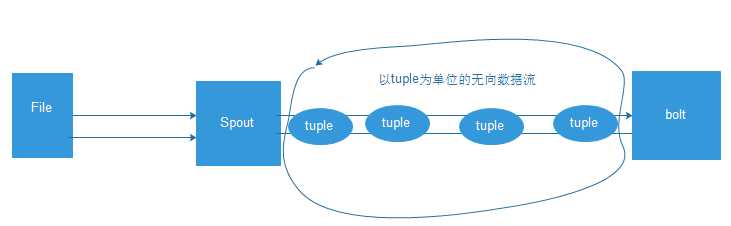
中的 “ topology” 。 topology则是一组由Spouts(数据源)和Bolts(数据操作)通过Stream
Groupings进行连接的图。下面对出现的术语进行更深刻的解析。
• Spout:
• 简而言之,Spout从来源处读取数据并放入topology。 Spout分成可靠和不可靠两种;当Storm接收失败
时,可靠的Spout会对 tuple(元组,数据项组成的列表)进行重发;而不可靠的Spout不会考虑接收成
功与否只发射一次。而Spout中最主要的方法就是 nextTuple(),该方法会发射一个新的tuple到
topology,如果没有新tuple发射则会简单的返回。
• Bolt:
• Topology中所有的处理都由Bolt完成。 Bolt可以完成任何事,比如:连接的过滤、聚合、访问文件/数据
库、等等。 Bolt从Spout 中接收数据并进行处理,如果遇到复杂流的处理也可能将tuple发送给另一个Bolt
进行处理。而Bolt中最重要的方法是execute(),以新的 tuple作为参数接收。不管是Spout还是Bolt,
如果将tuple发射成多个流,这些流都可以通过declareStream()来声明。
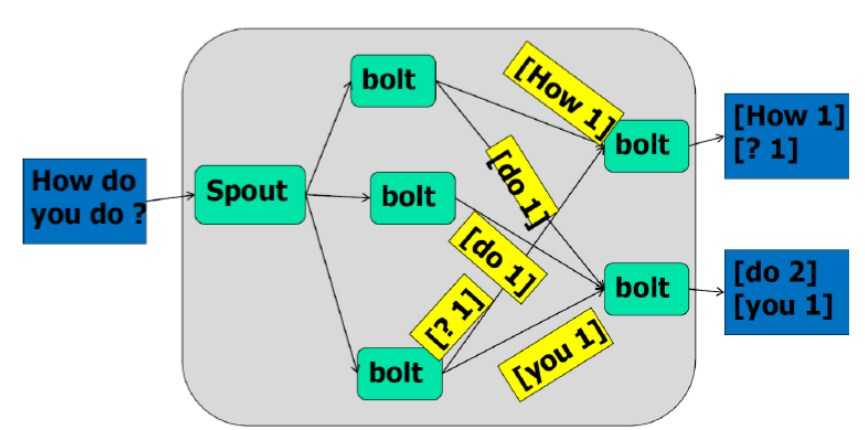
Topology
– –计算逻辑的封装
– –由spouts和bolts组成的图,通过stream grouping将图中的spouts
和bolts连接起来
---恢复内容结束---
Strom学习笔记一
原文:http://www.cnblogs.com/kxgdby/p/4489079.html