转载地址http://blog.csdn.net/yming0221/article/details/7492423
作者:闫明
本文分析基于Linux Kernel 1.2.13
注:标题中的”(上)“,”(下)“表示分析过程基于数据包的传递方向:”(上)“表示分析是从底层向上分析、”(下)“表示分析是从上向下分析。
上篇:
上一篇博文中我们从宏观上分析了Linux内核中网络栈的初始化过程,这里我们再从宏观上分析一下一个数据包在各网络层的传递的过程。
我们知道网络的OSI模型和TCP/IP模型层次结构如下:

上文中我们看到了网络栈的层次结构:
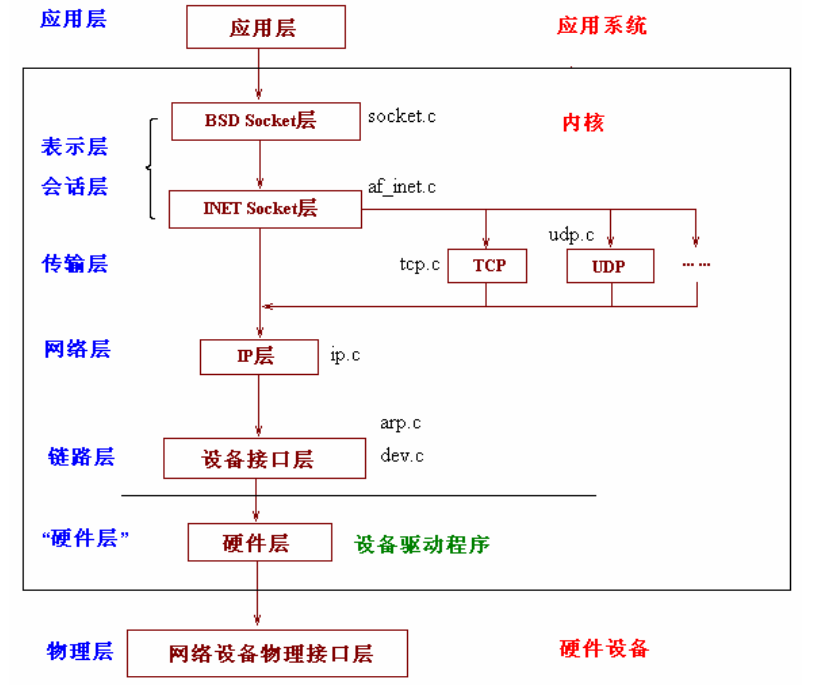
我们就从最底层开始追溯一个数据包的传递流程。
1、网络接口层
* 硬件监听物理介质,进行数据的接收,当接收的数据填满了缓冲区,硬件就会产生中断,中断产生后,系统会转向中断服务子程序。
*
在中断服务子程序中,数据会从硬件的缓冲区复制到内核的空间缓冲区,并包装成一个数据结构(sk_buff),然后调用对驱动层的接口函数netif_rx()将数据包发送给链路层。该函数的实现在net/inet/dev.c中,(在整个网络栈实现中dev.c文件的作用重大,它衔接了其下的驱动层和其上的网络层,可以称它为链路层模块的实现)
该函数的实现如下:
-
-
-
-
-
-
-
-
- void netif_rx(struct sk_buff *skb)
- {
- static int dropping = 0;
-
-
-
-
-
-
- skb->sk = NULL;
- skb->free = 1;
- if(skb->stamp.tv_sec==0)
- skb->stamp = xtime;
-
-
-
-
-
- if (!backlog_size)
- dropping = 0;
- else if (backlog_size > 300)
- dropping = 1;
-
- if (dropping)
- {
- kfree_skb(skb, FREE_READ);
- return;
- }
-
-
-
-
- #ifdef CONFIG_SKB_CHECK
- IS_SKB(skb);
- #endif
- skb_queue_tail(&backlog,skb);
- backlog_size++;
-
-
-
-
-
-
- mark_bh(NET_BH);
- return;
- }
该函数中用到了bootom
half技术,该技术的原理是将中断处理程序人为的分为两部分,上半部分是实时性要求较高的任务,后半部分可以稍后完成,这样就可以节省中断程序的处理时间。可整体的提高系统的性能。该技术将会在后续的博文中详细分析。
我们从上一篇分析中知道,在网络栈初始化的时候,已经将NET的下半部分执行函数定义成了net_bh(在socket.c文件中1375行左右)
- bh_base[NET_BH].routine= net_bh;
* 函数net_bh的实现在net/inet/dev.c中
2、网络层
*
就以IP数据包为例来说明,那么从链路层向网络层传递时将调用ip_rcv函数。该函数完成本层的处理后会根据IP首部中使用的传输层协议来调用相应协议的处理函数。
UDP对应udp_rcv、TCP对应tcp_rcv、ICMP对应icmp_rcv、IGMP对应igmp_rcv(虽然这里的ICMP,IGMP一般成为网络层协议,但是实际上他们都封装在IP协议里面,作为传输层对待)
这个函数比较复杂,后续会详细分析。这里粘贴一下,让我们对整体了解更清楚
-
-
-
-
- int ip_rcv(struct sk_buff *skb, struct device *dev, struct packet_type *pt)
- {
- struct iphdr *iph = skb->h.iph;
- struct sock *raw_sk=NULL;
- unsigned char hash;
- unsigned char flag = 0;
- unsigned char opts_p = 0;
- struct inet_protocol *ipprot;
- static struct options opt;
-
- int brd=IS_MYADDR;
- int is_frag=0;
- #ifdef CONFIG_IP_FIREWALL
- int err;
- #endif
-
- ip_statistics.IpInReceives++;
-
-
-
-
-
- skb->ip_hdr = iph;
-
-
-
-
-
-
-
-
-
-
- if (skb->len<sizeof(struct iphdr) || iph->ihl<5 || iph->version != 4 ||
- skb->len<ntohs(iph->tot_len) || ip_fast_csum((unsigned char *)iph, iph->ihl) !=0)
- {
- ip_statistics.IpInHdrErrors++;
- kfree_skb(skb, FREE_WRITE);
- return(0);
- }
-
-
-
-
-
- #ifdef CONFIG_IP_FIREWALL
-
- if ((err=ip_fw_chk(iph,dev,ip_fw_blk_chain,ip_fw_blk_policy, 0))!=1)
- {
- if(err==-1)
- icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0, dev);
- kfree_skb(skb, FREE_WRITE);
- return 0;
- }
-
- #endif
-
-
-
-
-
-
- skb->len=ntohs(iph->tot_len);
-
-
-
-
-
-
- if (iph->ihl != 5)
- {
- memset((char *) &opt, 0, sizeof(opt));
- if (do_options(iph, &opt) != 0)
- return 0;
- opts_p = 1;
- }
-
-
-
-
-
- if(iph->frag_off)
- {
- if (iph->frag_off & 0x0020)
- is_frag|=1;
-
-
-
-
- if (ntohs(iph->frag_off) & 0x1fff)
- is_frag|=2;
- }
-
-
-
-
-
-
-
-
-
-
-
-
-
- if ( iph->daddr != skb->dev->pa_addr && (brd = ip_chk_addr(iph->daddr)) == 0)
- {
-
-
-
-
- if(skb->pkt_type!=PACKET_HOST || brd==IS_BROADCAST)
- {
- kfree_skb(skb,FREE_WRITE);
- return 0;
- }
-
-
-
-
-
- #ifdef CONFIG_IP_FORWARD
- ip_forward(skb, dev, is_frag);
- #else
-
-
- ip_statistics.IpInAddrErrors++;
- #endif
-
-
-
-
-
- kfree_skb(skb, FREE_WRITE);
- return(0);
- }
-
- #ifdef CONFIG_IP_MULTICAST
-
- if(brd==IS_MULTICAST && iph->daddr!=IGMP_ALL_HOSTS && !(dev->flags&IFF_LOOPBACK))
- {
-
-
-
- struct ip_mc_list *ip_mc=dev->ip_mc_list;
- do
- {
- if(ip_mc==NULL)
- {
- kfree_skb(skb, FREE_WRITE);
- return 0;
- }
- if(ip_mc->multiaddr==iph->daddr)
- break;
- ip_mc=ip_mc->next;
- }
- while(1);
- }
- #endif
-
-
-
-
- #ifdef CONFIG_IP_ACCT
- ip_acct_cnt(iph,dev, ip_acct_chain);
- #endif
-
-
-
-
-
- if(is_frag)
- {
-
- skb=ip_defrag(iph,skb,dev);
- if(skb==NULL)
- return 0;
- skb->dev = dev;
- iph=skb->h.iph;
- }
-
-
-
-
-
-
-
- skb->ip_hdr = iph;
- skb->h.raw += iph->ihl*4;
-
-
-
-
-
- hash = iph->protocol & (SOCK_ARRAY_SIZE-1);
-
-
- if((raw_sk=raw_prot.sock_array[hash])!=NULL)
- {
- struct sock *sknext=NULL;
- struct sk_buff *skb1;
- raw_sk=get_sock_raw(raw_sk, hash, iph->saddr, iph->daddr);
- if(raw_sk)
- {
- do
- {
-
- sknext=get_sock_raw(raw_sk->next, hash, iph->saddr, iph->daddr);
- if(sknext)
- skb1=skb_clone(skb, GFP_ATOMIC);
- else
- break;
- if(skb1)
- raw_rcv(raw_sk, skb1, dev, iph->saddr,iph->daddr);
- raw_sk=sknext;
- }
- while(raw_sk!=NULL);
-
-
- }
- }
-
-
-
-
-
- hash = iph->protocol & (MAX_INET_PROTOS -1);
- for (ipprot = (struct inet_protocol *)inet_protos[hash];ipprot != NULL;ipprot=(struct inet_protocol *)ipprot->next)
- {
- struct sk_buff *skb2;
-
- if (ipprot->protocol != iph->protocol)
- continue;
-
-
-
-
-
-
- if (ipprot->copy || raw_sk)
- {
- skb2 = skb_clone(skb, GFP_ATOMIC);
- if(skb2==NULL)
- continue;
- }
- else
- {
- skb2 = skb;
- }
- flag = 1;
-
-
-
-
-
-
- ipprot->handler(skb2, dev, opts_p ? &opt : 0, iph->daddr,
- (ntohs(iph->tot_len) - (iph->ihl * 4)),
- iph->saddr, 0, ipprot);
-
- }
-
-
-
-
-
-
-
-
- if(raw_sk!=NULL)
- raw_rcv(raw_sk, skb, dev, iph->saddr, iph->daddr);
- else if (!flag)
- {
- if (brd != IS_BROADCAST && brd!=IS_MULTICAST)
- icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0, dev);
- kfree_skb(skb, FREE_WRITE);
- }
-
- return(0);
- }
3、传输层
如果在IP数据报的首部标明的是使用TCP传输数据,则在上述函数中会调用tcp_rcv函数。该函数的大体处理流程为:
“所有使用TCP 协议的套接字对应sock 结构都被挂入tcp_prot 全局变量表示的proto 结构之sock_array
数组中,采用以本地端口号为索引的插入方式,所以当tcp_rcv 函数接收到一个数据包,在完成必要的检查和处理后,其将以TCP
协议首部中目的端口号(对于一个接收的数据包而言,其目的端口号就是本地所使用的端口号)为索引,在tcp_prot 对应sock 结构之sock_array
数组中得到正确的sock 结构队列,在辅之以其他条件遍历该队列进行对应sock 结构的查询,在得到匹配的sock 结构后,将数据包挂入该sock
结构中的缓存队列中(由sock 结构中receive_queue 字段指向),从而完成数据包的最终接收。”
该函数的实现也会比较复杂,这是由TCP协议的复杂功能决定的。附代码如下:
-
-
-
-
- int tcp_rcv(struct sk_buff *skb, struct device *dev, struct options *opt,
- unsigned long daddr, unsigned short len,
- unsigned long saddr, int redo, struct inet_protocol * protocol)
- {
- struct tcphdr *th;
- struct sock *sk;
- int syn_ok=0;
-
- if (!skb)
- {
- printk("IMPOSSIBLE 1\n");
- return(0);
- }
-
- if (!dev)
- {
- printk("IMPOSSIBLE 2\n");
- return(0);
- }
-
- tcp_statistics.TcpInSegs++;
-
- if(skb->pkt_type!=PACKET_HOST)
- {
- kfree_skb(skb,FREE_READ);
- return(0);
- }
-
- th = skb->h.th;
-
-
-
-
-
- sk = get_sock(&tcp_prot, th->dest, saddr, th->source, daddr);
-
-
-
-
-
-
-
-
-
-
- if (sk!=NULL && (sk->zapped || sk->state==TCP_CLOSE))
- sk=NULL;
-
- if (!redo)
- {
- if (tcp_check(th, len, saddr, daddr ))
- {
- skb->sk = NULL;
- kfree_skb(skb,FREE_READ);
-
-
-
-
- return(0);
- }
- th->seq = ntohl(th->seq);
-
-
- if (sk == NULL)
- {
-
-
-
- tcp_reset(daddr, saddr, th, &tcp_prot, opt,dev,skb->ip_hdr->tos,255);
- skb->sk = NULL;
-
-
-
- kfree_skb(skb, FREE_READ);
- return(0);
- }
-
- skb->len = len;
- skb->acked = 0;
- skb->used = 0;
- skb->free = 0;
- skb->saddr = daddr;
- skb->daddr = saddr;
-
-
- cli();
- if (sk->inuse)
- {
- skb_queue_tail(&sk->back_log, skb);
- sti();
- return(0);
- }
- sk->inuse = 1;
- sti();
- }
- else
- {
- if (sk==NULL)
- {
- tcp_reset(daddr, saddr, th, &tcp_prot, opt,dev,skb->ip_hdr->tos,255);
- skb->sk = NULL;
- kfree_skb(skb, FREE_READ);
- return(0);
- }
- }
-
-
- if (!sk->prot)
- {
- printk("IMPOSSIBLE 3\n");
- return(0);
- }
-
-
-
-
-
-
- if (sk->rmem_alloc + skb->mem_len >= sk->rcvbuf)
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return(0);
- }
-
- skb->sk=sk;
- sk->rmem_alloc += skb->mem_len;
-
-
-
-
-
-
-
-
- if(sk->state!=TCP_ESTABLISHED)
- {
-
-
-
-
-
- if(sk->state==TCP_LISTEN)
- {
- if(th->ack)
- tcp_reset(daddr,saddr,th,sk->prot,opt,dev,sk->ip_tos, sk->ip_ttl);
-
-
-
-
-
-
-
-
- if(th->rst || !th->syn || th->ack || ip_chk_addr(daddr)!=IS_MYADDR)
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
-
-
- tcp_conn_request(sk, skb, daddr, saddr, opt, dev, tcp_init_seq());
-
-
-
-
-
-
-
-
-
-
- release_sock(sk);
- return 0;
- }
-
-
- if (sk->state == TCP_SYN_RECV && th->syn && th->seq+1 == sk->acked_seq)
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
-
-
-
- if(sk->state==TCP_SYN_SENT)
- {
-
- if(th->ack)
- {
-
- if(!tcp_ack(sk,th,saddr,len))
- {
-
-
- tcp_statistics.TcpAttemptFails++;
- tcp_reset(daddr, saddr, th,
- sk->prot, opt,dev,sk->ip_tos,sk->ip_ttl);
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return(0);
- }
- if(th->rst)
- return tcp_std_reset(sk,skb);
- if(!th->syn)
- {
-
-
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
-
- syn_ok=1;
- sk->acked_seq=th->seq+1;
- sk->fin_seq=th->seq;
- tcp_send_ack(sk->sent_seq,sk->acked_seq,sk,th,sk->daddr);
- tcp_set_state(sk, TCP_ESTABLISHED);
- tcp_options(sk,th);
- sk->dummy_th.dest=th->source;
- sk->copied_seq = sk->acked_seq;
- if(!sk->dead)
- {
- sk->state_change(sk);
- sock_wake_async(sk->socket, 0);
- }
- if(sk->max_window==0)
- {
- sk->max_window = 32;
- sk->mss = min(sk->max_window, sk->mtu);
- }
- }
- else
- {
-
- if(th->syn && !th->rst)
- {
-
-
- if(sk->saddr==saddr && sk->daddr==daddr &&
- sk->dummy_th.source==th->source &&
- sk->dummy_th.dest==th->dest)
- {
- tcp_statistics.TcpAttemptFails++;
- return tcp_std_reset(sk,skb);
- }
- tcp_set_state(sk,TCP_SYN_RECV);
-
-
-
-
-
- }
-
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
- goto rfc_step6;
- }
-
-
-
-
-
-
-
- #define BSD_TIME_WAIT
- #ifdef BSD_TIME_WAIT
- if (sk->state == TCP_TIME_WAIT && th->syn && sk->dead &&
- after(th->seq, sk->acked_seq) && !th->rst)
- {
- long seq=sk->write_seq;
- if(sk->debug)
- printk("Doing a BSD time wait\n");
- tcp_statistics.TcpEstabResets++;
- sk->rmem_alloc -= skb->mem_len;
- skb->sk = NULL;
- sk->err=ECONNRESET;
- tcp_set_state(sk, TCP_CLOSE);
- sk->shutdown = SHUTDOWN_MASK;
- release_sock(sk);
- sk=get_sock(&tcp_prot, th->dest, saddr, th->source, daddr);
- if (sk && sk->state==TCP_LISTEN)
- {
- sk->inuse=1;
- skb->sk = sk;
- sk->rmem_alloc += skb->mem_len;
- tcp_conn_request(sk, skb, daddr, saddr,opt, dev,seq+128000);
- release_sock(sk);
- return 0;
- }
- kfree_skb(skb, FREE_READ);
- return 0;
- }
- #endif
- }
-
-
-
-
-
-
-
- if(!tcp_sequence(sk,th,len,opt,saddr,dev))
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
- if(th->rst)
- return tcp_std_reset(sk,skb);
-
-
-
-
-
- if(th->syn && !syn_ok)
- {
- tcp_reset(daddr,saddr,th, &tcp_prot, opt, dev, skb->ip_hdr->tos, 255);
- return tcp_std_reset(sk,skb);
- }
-
-
-
-
-
-
- if(th->ack && !tcp_ack(sk,th,saddr,len))
- {
-
-
-
-
- if(sk->state==TCP_SYN_RECV)
- {
- tcp_reset(daddr, saddr, th,sk->prot, opt, dev,sk->ip_tos,sk->ip_ttl);
- }
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
- rfc_step6:
-
-
-
-
-
- if(tcp_urg(sk, th, saddr, len))
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
-
-
-
- if(tcp_data(skb,sk, saddr, len))
- {
- kfree_skb(skb, FREE_READ);
- release_sock(sk);
- return 0;
- }
-
-
-
-
-
- release_sock(sk);
- return 0;
- }
4、应用层
当用户需要接收数据时,首先根据文件描述符inode得到socket结构和sock结构,然后从sock结构中指向的队列recieve_queue中读取数据包,将数据包COPY到用户空间缓冲区。数据就完整的从硬件中传输到用户空间。这样也完成了一次完整的从下到上的传输。
下篇:
在博文Linux内核--网络栈实现分析(二)--数据包的传递过程(上)中分析了数据包从网卡设备经过驱动链路层,网络层,传输层到应用层的过程。
本文就分析一下本机产生数据是如何通过传输层,网络层到达物理层的。
综述来说,数据流程图如下:
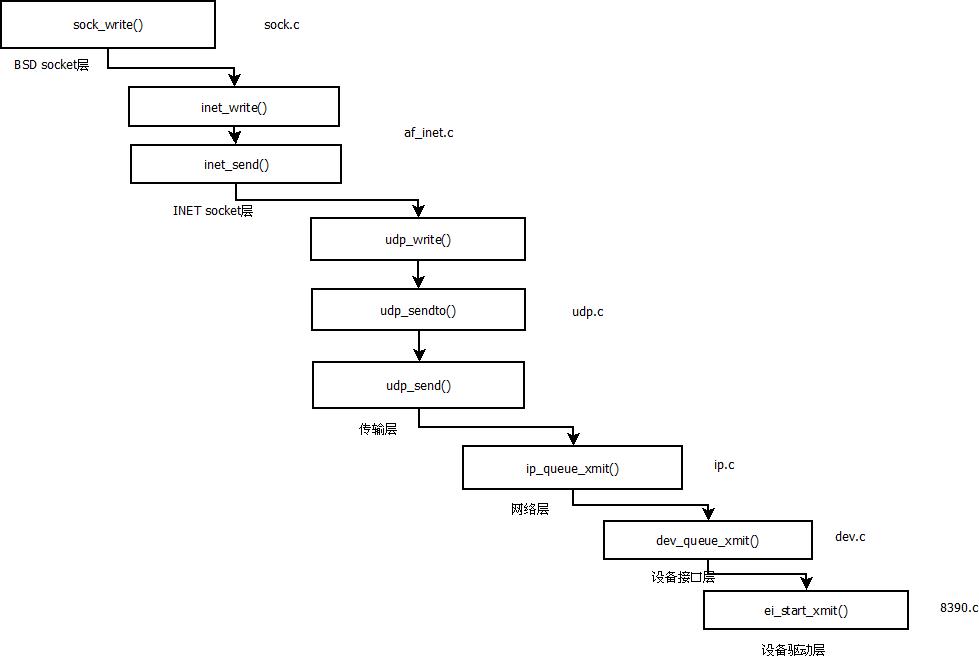
一、应用层
应用层可以通过系统调用或文件操作来调用内核函数,BSD层的sock_write()函数会调用INET层的inet_wirte()函数。
-
-
-
-
-
- static int sock_write(struct inode *inode, struct file *file, char *ubuf, int size)
- {
- struct socket *sock;
- int err;
-
- if (!(sock = socki_lookup(inode)))
- {
- printk("NET: sock_write: can‘t find socket for inode!\n");
- return(-EBADF);
- }
-
- if (sock->flags & SO_ACCEPTCON)
- return(-EINVAL);
-
- if(size<0)
- return -EINVAL;
- if(size==0)
- return 0;
-
- if ((err=verify_area(VERIFY_READ,ubuf,size))<0)
- return err;
- return(sock->ops->write(sock, ubuf, size,(file->f_flags & O_NONBLOCK)));
- }
INET层会调用具体传输层协议的write函数,该函数是通过调用本层的inet_send()函数实现功能的,inet_send()函数的UDP协议对应的函数为udp_write()
- static int inet_send(struct socket *sock, void *ubuf, int size, int noblock,
- unsigned flags)
- {
- struct sock *sk = (struct sock *) sock->data;
- if (sk->shutdown & SEND_SHUTDOWN)
- {
- send_sig(SIGPIPE, current, 1);
- return(-EPIPE);
- }
- if(sk->err)
- return inet_error(sk);
-
- if(inet_autobind(sk)!=0)
- return(-EAGAIN);
- return(sk->prot->write(sk, (unsigned char *) ubuf, size, noblock, flags));
- }
-
- static int inet_write(struct socket *sock, char *ubuf, int size, int noblock)
- {
- return inet_send(sock,ubuf,size,noblock,0);
- }
二、传输层
在传输层udp_write()函数调用本层的udp_sendto()函数完成功能。
-
-
-
-
- static int udp_write(struct sock *sk, unsigned char *buff, int len, int noblock,
- unsigned flags)
- {
- return(udp_sendto(sk, buff, len, noblock, flags, NULL, 0));
- }
udp_send()函数完成sk_buff结构相应的设置和报头的填写后会调用udp_send()来发送数据。具体的实现过程后面会详细分析。
而在udp_send()函数中,最后会调用ip_queue_xmit()函数,将数据包下放的网络层。
下面是udp_prot定义:
- struct proto udp_prot = {
- sock_wmalloc,
- sock_rmalloc,
- sock_wfree,
- sock_rfree,
- sock_rspace,
- sock_wspace,
- udp_close,
- udp_read,
- udp_write,
- udp_sendto,
- udp_recvfrom,
- ip_build_header,
- udp_connect,
- NULL,
- ip_queue_xmit,
- NULL,
- NULL,
- NULL,
- udp_rcv,
- datagram_select,
- udp_ioctl,
- NULL,
- NULL,
- ip_setsockopt,
- ip_getsockopt,
- 128,
- 0,
- {NULL,},
- "UDP",
- 0, 0
- };
- static int udp_send(struct sock *sk, struct sockaddr_in *sin,
- unsigned char *from, int len, int rt)
- {
- struct sk_buff *skb;
- struct device *dev;
- struct udphdr *uh;
- unsigned char *buff;
- unsigned long saddr;
- int size, tmp;
- int ttl;
-
-
-
-
-
- ........................
-
-
-
-
-
- ..........................
-
-
-
-
- ..............................
-
-
-
-
-
- memcpy_fromfs(buff, from, len);
-
-
-
-
-
- udp_send_check(uh, saddr, sin->sin_addr.s_addr, skb->len - tmp, sk);
-
-
-
-
-
- udp_statistics.UdpOutDatagrams++;
-
- sk->prot->queue_xmit(sk, dev, skb, 1);
- return(len);
- }
三、网络层
在网络层,函数ip_queue_xmit()的功能是将数据包进行一系列复杂的操作,比如是检查数据包是否需要分片,是否是多播等一系列检查,最后调用dev_queue_xmit()函数发送数据。
四、驱动层(链路层)
在函数中,函数调用会调用具体设备的发送函数来发送数据包
dev->hard_start_xmit(skb, dev);
具体设备的发送函数在网络初始化的时候已经设置了。
这里以8390网卡为例来说明驱动层的工作原理,在net/drivers/8390.c中函数ethdev_init()函数中设置如下:
-
- int ethdev_init(struct device *dev)
- {
- if (ei_debug > 1)
- printk(version);
-
- if (dev->priv == NULL) {
- struct ei_device *ei_local;
-
- dev->priv = kmalloc(sizeof(struct ei_device), GFP_KERNEL);
- memset(dev->priv, 0, sizeof(struct ei_device));
- ei_local = (struct ei_device *)dev->priv;
- #ifndef NO_PINGPONG
- ei_local->pingpong = 1;
- #endif
- }
-
-
- if (dev->open == NULL)
- dev->open = &ei_open;
-
- dev->hard_start_xmit = &ei_start_xmit;
- dev->get_stats = get_stats;
- #ifdef HAVE_MULTICAST
- dev->set_multicast_list = &set_multicast_list;
- #endif
-
- ether_setup(dev);
-
- return 0;
- }
驱动中的发送函数比较复杂,和硬件关系紧密,这里不再详细分析。
这样就大体分析了下网络数据从应用层到物理层的数据通路,后面会详细分析。
Linux内核--网络栈实现分析(二)--数据包的传递过程--转,布布扣,bubuko.com
Linux内核--网络栈实现分析(二)--数据包的传递过程--转
原文:http://www.cnblogs.com/davidwang456/p/3604089.html