Hive Tables
将HIVE_HOME/conf/hive-site.xml 文件copy到SPARK_HOME/conf/下
When not configured by the hive-site.xml, the context automatically creates metastore_db and warehouse in the current directory.
// sc is an existing SparkContext.val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")sqlContext.sql("LOAD DATA LOCAL INPATH ‘examples/src/main/resources/kv1.txt‘ INTO TABLE src")// Queries are expressed in HiveQLsqlContext.sql("FROM src SELECT key, value").collect().foreach(println)

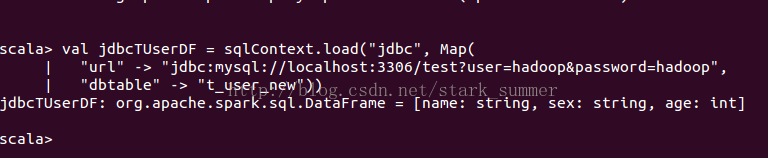
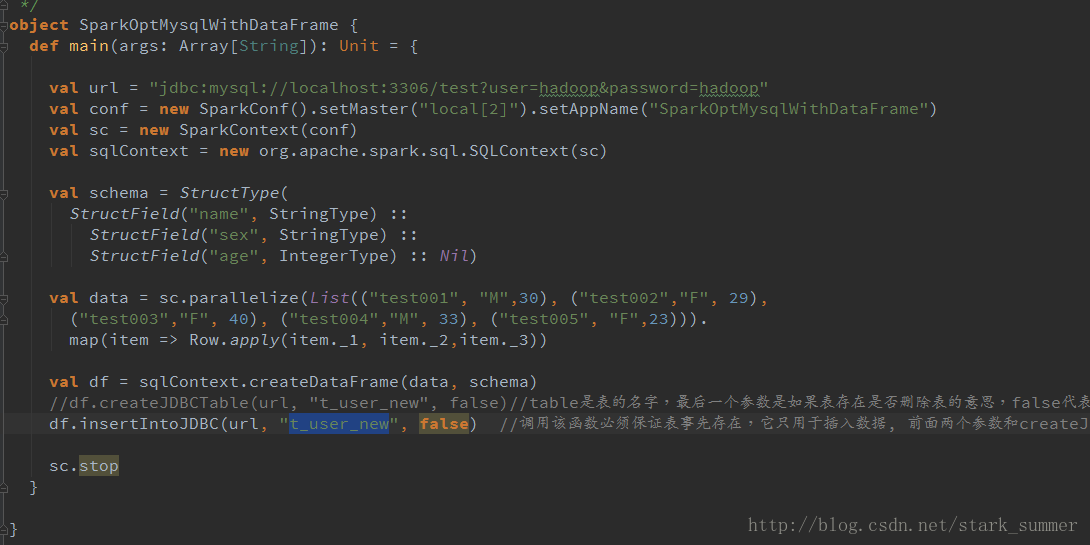
加载mysql数据库:test,表:t_user_new返回DataFrame
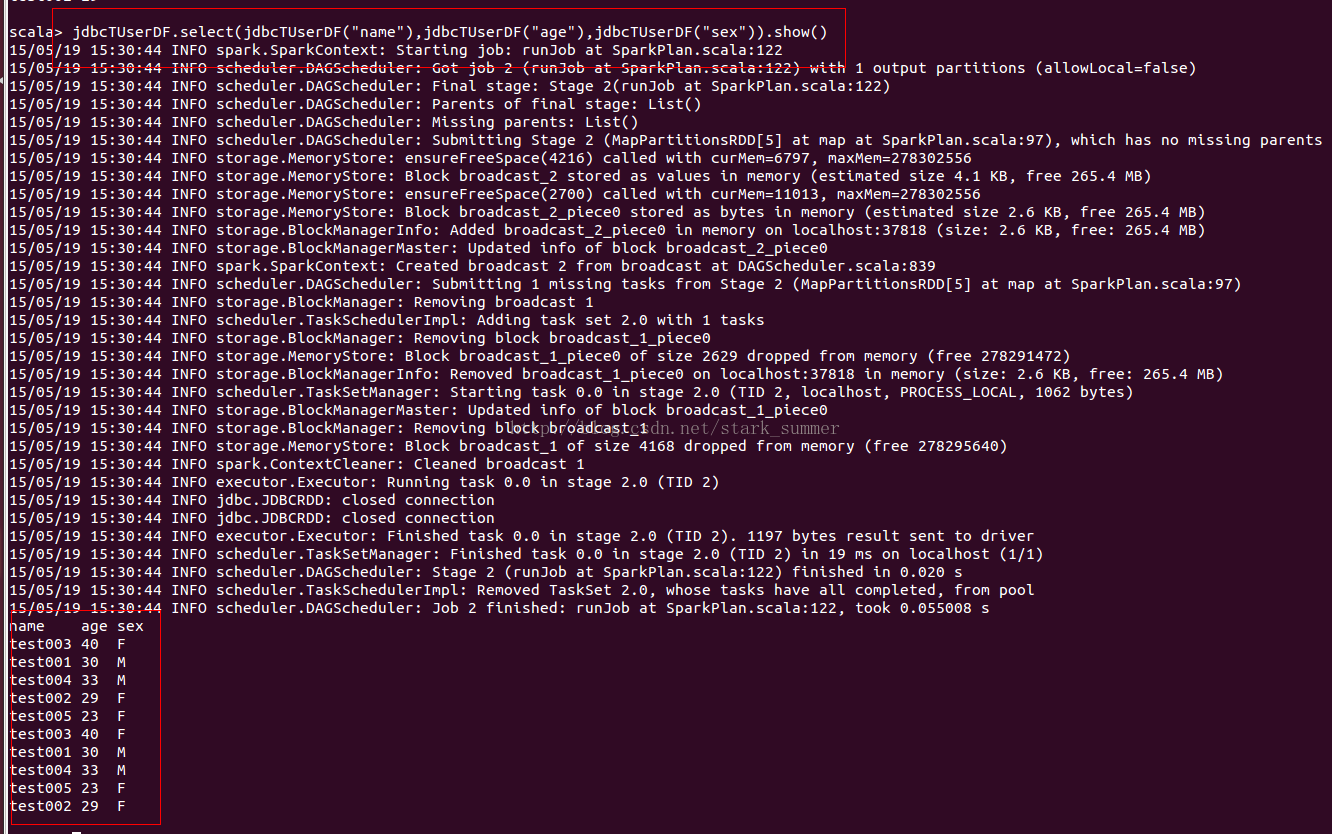
查询数据:
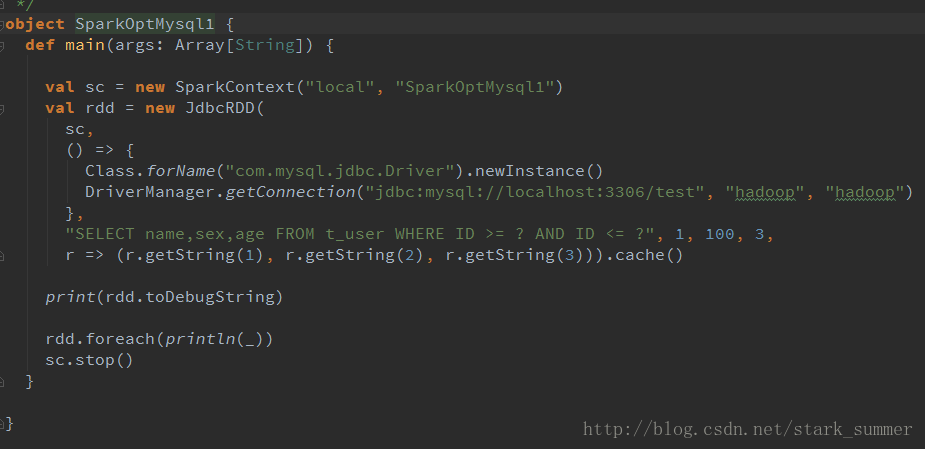
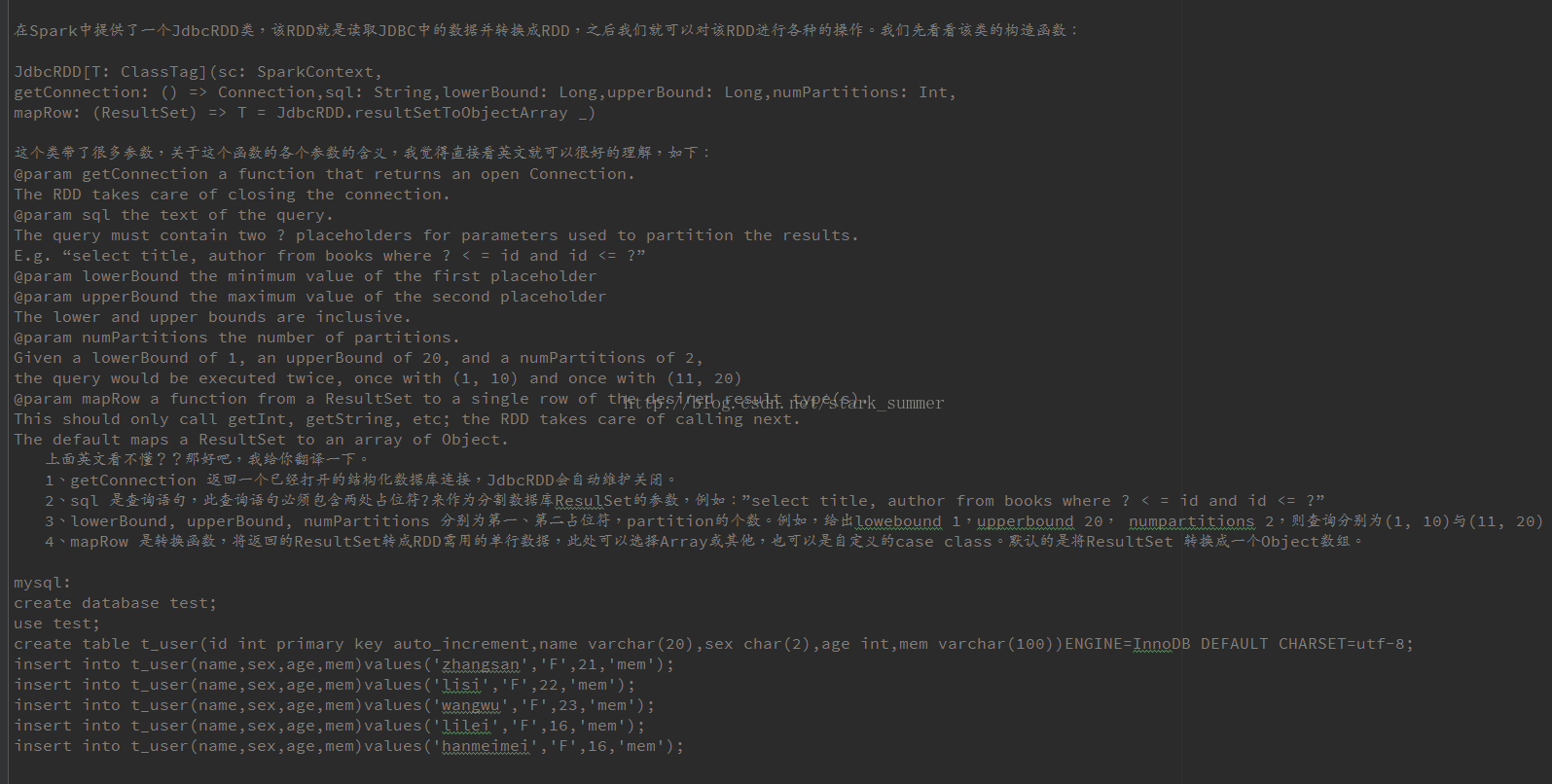
spark 程序操作JDBC:



未完待续~~~
尊重原创,未经允许不得转载:http://blog.csdn.net/stark_summer/article/details/45843803
原文:http://my.oschina.net/u/230960/blog/417246