HDFS Federation能解决一下问题:
1. 支持多个namespace
2. 水平扩展出多个namenode后,就可以避免网络架构上的性能瓶颈问题
3. 多个应用可以使用各自的namenode,从而相互隔离。
不过还是没有解决单点故障问题。
官方文档:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/Federation.html
架构图如下:
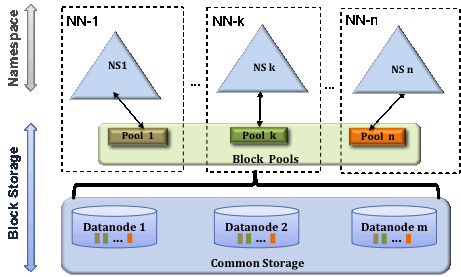
现在准备两个namenode server: namenode1和namenode2, /etc/hosts里面的配置如下:
#hdfs cluster 192.168.1.71 namenode1 192.168.1.72 namenode2 192.168.1.73 datanode1 192.168.1.74 datanode2 192.168.1.75 datanode3现在来看看上面5台server的配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>net.topology.node.switch.mapping.impl</name>
<value>org.apache.hadoop.net.ScriptBasedMapping</value>
<description> The default implementation of the DNSToSwitchMapping. It
invokes a script specified in net.topology.script.file.name to resolve
node names. If the value for net.topology.script.file.name is not set, the
default value of DEFAULT_RACK is returned for all node names.
</description>
</property>
<property>
<name>net.topology.script.file.name</name>
<value>/opt/rack.lsp</value>
</property>
<property>
<name>net.topology.script.number.args</name>
<value>100</value>
<description> The max number of args that the script configured with
net.topology.script.file.name should be run with. Each arg is an
IP address.
</description>
</property>
</configuration><configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/mydata/hdfs/namenode</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>datanode1,datanode2,datanode3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!--hdfs federation begin-->
<property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>namenode1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>namenode2:9000</value>
</property>
<!--hdfs federation end-->
</configuration>
注意添加了hdfs federation的配置,里面有两个namespaces: ns1和ns2,分别位于namenode1和namenode2上。datanode1 datanode2 datanode3
<configuration>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration><configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/mydata/hdfs/datanode</value>
</property>
<!--hdfs federation begin-->
<property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>namenode1:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>namenode2:9000</value>
</property>
<!--hdfs federation end-->
</configuration>
hdfs namenode -format -clusterId csfreebird hadoop-daemon.sh --config $HADOOP_CONF_DIR --script hdfs start namenode因为曾经格式化过namenode,要回答y表示重新格式化。

export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
现在再namenode1上执行下面的命令,停止所有hdfs的服务:
hduser@namenode1:~$ stop-dfs.sh Stopping namenodes on [namenode1 namenode2] namenode2: no namenode to stop namenode1: no namenode to stop datanode2: no datanode to stop datanode1: no datanode to stop datanode3: no datanode to stop
如果在启动datanode的时候日志中报错:
java.io.IOException: Incompatible clusterIDsUbuntu上使用Hadoop 2.x 十 HDFS Federation,布布扣,bubuko.com
Ubuntu上使用Hadoop 2.x 十 HDFS Federation
原文:http://blog.csdn.net/csfreebird/article/details/21301613