dummy_function(void) { unsigned char * ptr=0x00; *ptr=0x00; } int main() { dummy_function(); return 0; }
作为一名熟练的c/c++程序员,以上代码的bug应该是很清楚的,因为它尝试操作地址为0的内存区域,而这个地址区域通常是不可访问的禁区,当然会出错了。
方法1 :利用gdb逐步查找段错误 这种方法也是被大众所熟知并广泛采用的方法,首先我们需要一个带有调试 信息的可执行程序,所以我们加上"-g -rdynamic“的参数进行编译,然后调用 gdb调试运行这个新编译的程序。
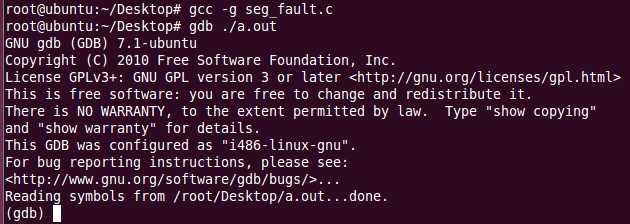
这个版本的gdb没有提示出错误,以前的那个版本提示除了错误。
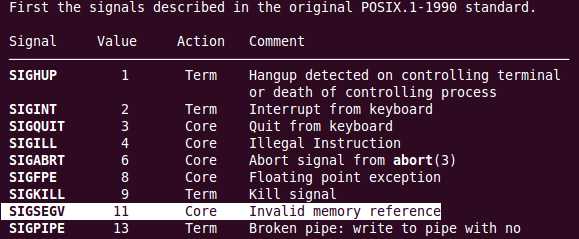
不仅提示出第几行有错误,而且还提示出了了是因为进程是由于收到了SIGSEGV信号而结束的。通过进一步的查阅资料文档(man 7 signal),
我们知道SIGSEGV默认handler的动作是打印”段错误“的出错信息,并产生core文件,由此我们又产生了方法二。

方法2:分析core文件
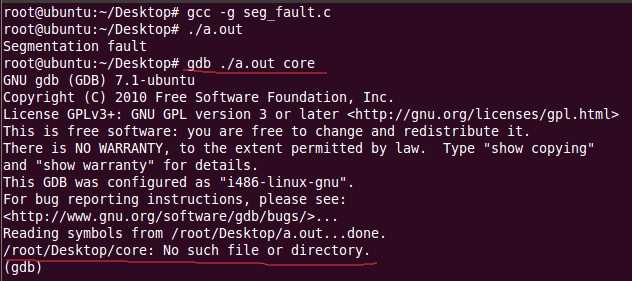
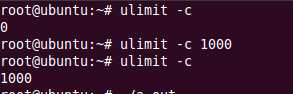
但是奇怪了我的系统上并没有生成core文件,linux系统默认禁止生成core文件,我们用下面的命令测试了一下果真如此。
我们将core文件的大小限制为1000, 这个好像每次都要设置不然输不出来,估计要修改那个文件,不管了,知道就行了。
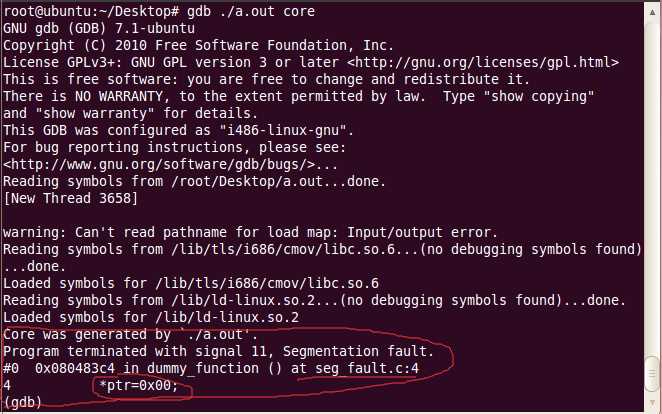
哇,好厉害,还是一步定位到了错误所在地,佩服linux系统的此类设计,
方法3:段错误时启动调试(试过没成功)
1 #include<signal.h> 2 #include<stdlib.h> 3 void dump(int signo) 4 { 5 //此处省略。。。。 system("gdb"); 6 7 } 8 dummy_function(void) 9 { 10 unsigned char * ptr=0x00; 11 *ptr=0x00; 12 sleep(10); 13 } 14 int main() 15 { 16 signal(SIGSEGV,&dump); 17 dummy_function(); 18 return 0; 19 } 大概思路就是这样的,然后进入调试界面后输入”bt"
方法4:利用backtrace和objdump进行分析。
原文:http://www.cnblogs.com/leijiangtao/p/4594256.html