透视数据是一种把数据从行的状态旋转为列的状态的处理。每个透视转换将涉及分组、扩展及聚合三个逻辑处理阶段,每个阶段都有相关的元素:分组阶段处理相关的分组或行元素,扩展阶段处理相关的扩展或列元素,聚合阶段处理相关的聚合元素和聚合函数。现在假设有一张表数据如下:
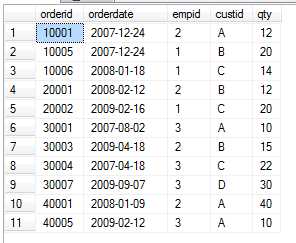
我现在需要查询出下面的结果:

需求分析:需要在结果中为每一个雇员生成一行记录,这就需要对Orders表中的行按照其empid列进行分组;从结果看,还需要为每一个客户生成一个不同的结果列,那么扩展元素就是custid列;最后还需要对数据进行聚合(本例中为SUM)。以下代码是使用标准SQL进行透视转换:
SELECT empid, SUM(CASE WHEN custid = ‘A‘ THEN qty END) AS A, SUM(CASE WHEN custid = ‘B‘ THEN qty END) AS B, SUM(CASE WHEN custid = ‘C‘ THEN qty END) AS C, SUM(CASE WHEN custid = ‘D‘ THEN qty END) AS D FROM dbo.Orders GROUP BY empid;
使用T-SQL PIVOT运算符进行透视转换。SQL Server 2005引入了一个T-SQL特有的表运算符PIVOT,PIVOT运算符同样涉及三个逻辑处理阶段(分组、扩展和聚合)。注意,一般不直接把PIVOT运算符应用到源表,而是将其应用到一个表表达式(该表表达式只包含透视转换需要的3种元素,不包含其他属性):
SELECT empid, A, B, C, D FROM (SELECT empid, custid, qty FROM dbo.Orders) AS D PIVOT(SUM(qty) FOR custid IN(A, B, C, D)) AS P;
上面代码中PIVOT操作符并没有直接操作Orders表,而是对一个名为D的派生表进行操作,该派生表只包含透视转换元素empid、custid、qty。
需求如下,原数据如下:

现在需要得到这样的数据:
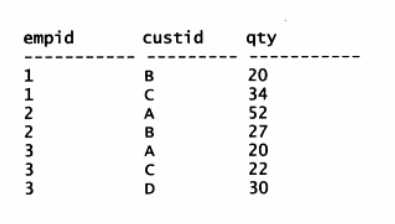
使用标准SQL进行逆透视转换。逆透视转换的标准SQL解决方案非常明确地要实现3个逻辑处理阶段:生成副本、提取元素和删除不相关的交叉。
SELECT empid, custid, CASE custid WHEN ‘A‘ THEN A WHEN ‘B‘ THEN B WHEN ‘C‘ THEN C WHEN ‘D‘ THEN D END AS qty FROM dbo.EmpCustOrders CROSS JOIN (VALUES(‘A‘),(‘B‘),(‘C‘),(‘D‘)) AS Custs(custid);
执行结果如下:
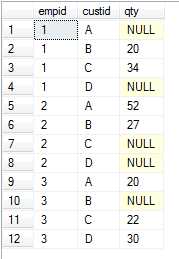
如果还想进一步过滤掉含有null值的数据,则可以这样:
SELECT * FROM (SELECT empid, custid, CASE custid WHEN ‘A‘ THEN A WHEN ‘B‘ THEN B WHEN ‘C‘ THEN C WHEN ‘D‘ THEN D END AS qty FROM dbo.EmpCustOrders CROSS JOIN (VALUES(‘A‘),(‘B‘),(‘C‘),(‘D‘)) AS Custs(custid)) AS D WHERE qty IS NOT NULL;
使用T-SQL的UNPIVOT运算符进行逆透视转换:
SELECT empid, custid, qty FROM dbo.EmpCustOrders UNPIVOT(qty FOR custid IN(A, B, C, D)) AS U;
GROUPING SETS从属子句:
SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY GROUPING SETS ( (empid, custid), (empid), (custid), () );
CUBE从属子句
SELECT empid, custid, SUM(qty) AS sumqty FROM dbo.Orders GROUP BY CUBE(empid, custid);
笔记-Microsoft SQL Server 2008技术内幕:T-SQL语言基础-07 透视、逆透视及分组集
原文:http://www.cnblogs.com/laixiancai/p/4593985.html